 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAADNet: An End-to-End Deep Learning Model for Auditory Attention Decoding
Paper and Code
Oct 16, 2024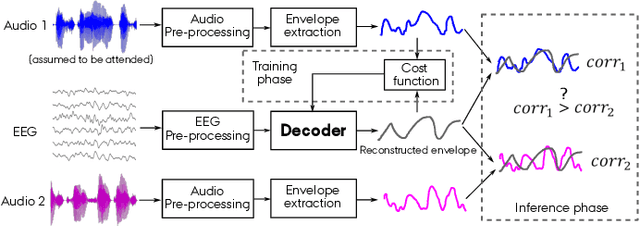
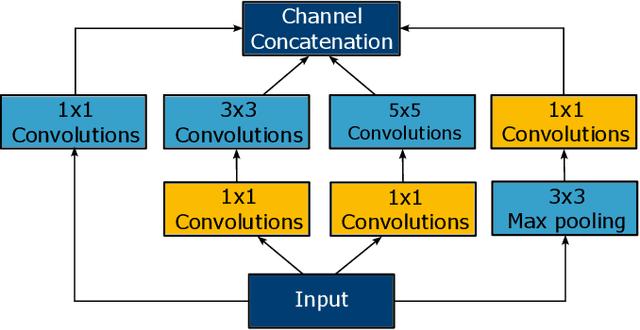
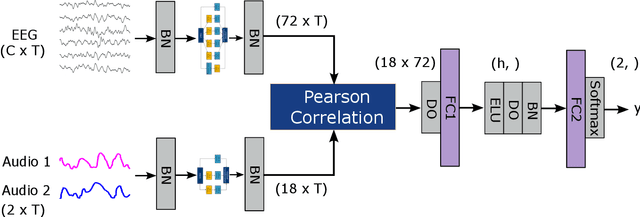
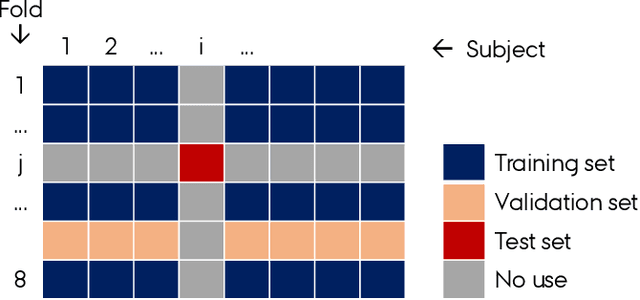
Auditory attention decoding (AAD) is the process of identifying the attended speech in a multi-talker environment using brain signals, typically recorded through electroencephalography (EEG). Over the past decade, AAD has undergone continuous development, driven by its promising application in neuro-steered hearing devices. Most AAD algorithms are relying on the increase in neural entrainment to the envelope of attended speech, as compared to unattended speech, typically using a two-step approach. First, the algorithm predicts representations of the attended speech signal envelopes; second, it identifies the attended speech by finding the highest correlation between the predictions and the representations of the actual speech signals. In this study, we proposed a novel end-to-end neural network architecture, named AADNet, which combines these two stages into a direct approach to address the AAD problem. We compare the proposed network against the traditional approaches, including linear stimulus reconstruction, canonical correlation analysis, and an alternative non-linear stimulus reconstruction using two different datasets. AADNet shows a significant performance improvement for both subject-specific and subject-independent models. Notably, the average subject-independent classification accuracies from 56.1 % to 82.7 % with analysis window lengths ranging from 1 to 40 seconds, respectively, show a significantly improved ability to generalize to data from unseen subjects. These results highlight the potential of deep learning models for advancing AAD, with promising implications for future hearing aids, assistive devices, and clinical assessments.