 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScattering Transform for Auditory Attention Decoding
Feb 26, 2026The use of hearing aids will increase in the coming years due to demographic change. One open problem that remains to be solved by a new generation of hearing aids is the cocktail party problem. A possible solution is electroencephalography-based auditory attention decoding. This has been the subject of several studies in recent years, which have in common that they use the same preprocessing methods in most cases. In this work, in order to achieve an advantage, the use of a scattering transform is proposed as an alternative to these preprocessing methods. The two-layer scattering transform is compared with a regular filterbank, the synchrosqueezing short-time Fourier transform and the common preprocessing. To demonstrate the performance, the known and the proposed preprocessing methods are compared for different classification tasks on two widely used datasets, provided by the KU Leuven (KUL) and the Technical University of Denmark (DTU). Both established and new neural-network-based models, CNNs, LSTMs, and recent Transformer/graph-based models are used for classification. Various evaluation strategies were compared, with a focus on the task of classifying speakers who are unknown from the training. We show that the two-layer scattering transform can significantly improve the performance for subject-related conditions, especially on the KUL dataset. However, on the DTU dataset, this only applies to some of the models, or when larger amounts of training data are provided, as in 10-fold cross-validation. This suggests that the scattering transform is capable of extracting additional relevant information.
Efficient Chebyshev Reconstruction for the Anisotropic Equilibrium Model in Magnetic Particle Imaging
Apr 17, 2025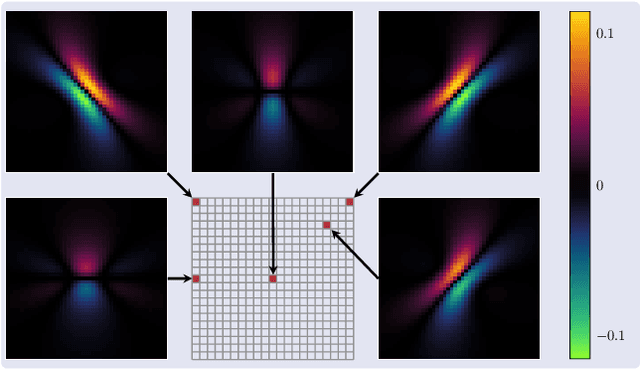
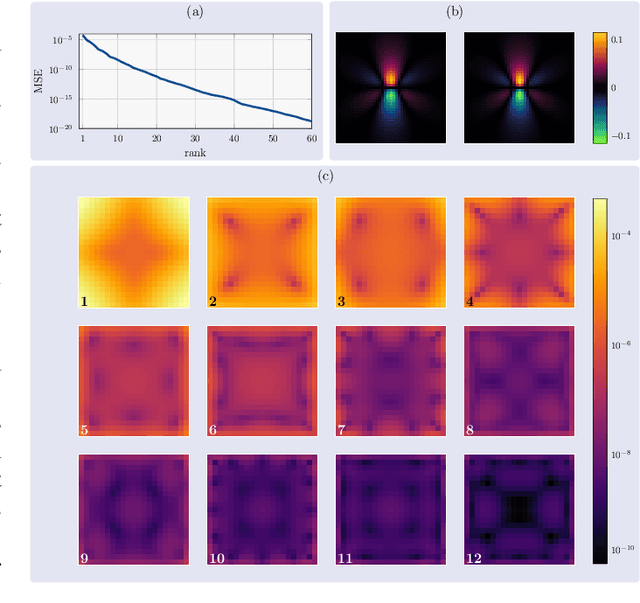


Magnetic Particle Imaging (MPI) is a tomographic imaging modality capable of real-time, high-sensitivity mapping of superparamagnetic iron oxide nanoparticles. Model-based image reconstruction provides an alternative to conventional methods that rely on a measured system matrix, eliminating the need for laborious calibration measurements. Nevertheless, model-based approaches must account for the complexities of the imaging chain to maintain high image quality. A recently proposed direct reconstruction method leverages weighted Chebyshev polynomials in the frequency domain, removing the need for a simulated system matrix. However, the underlying model neglects key physical effects, such as nanoparticle anisotropy, leading to distortions in reconstructed images. To mitigate these artifacts, an adapted direct Chebyshev reconstruction (DCR) method incorporates a spatially variant deconvolution step, significantly improving reconstruction accuracy at the cost of increased computational demands. In this work, we evaluate the adapted DCR on six experimental phantoms, demonstrating enhanced reconstruction quality in real measurements and achieving image fidelity comparable to or exceeding that of simulated system matrix reconstruction. Furthermore, we introduce an efficient approximation for the spatially variable deconvolution, reducing both runtime and memory consumption while maintaining accuracy. This method achieves computational complexity of O(N log N ), making it particularly beneficial for high-resolution and three-dimensional imaging. Our results highlight the potential of the adapted DCR approach for improving model-based MPI reconstruction in practical applications.
Equilibrium Model with Anisotropy for Model-Based Reconstruction in Magnetic Particle Imaging
Mar 01, 2024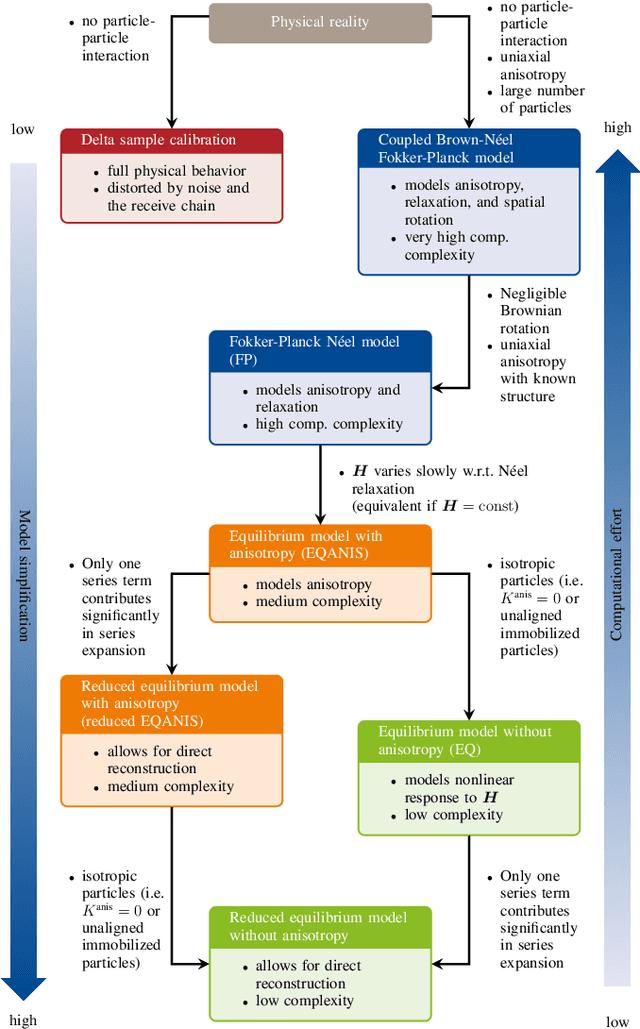
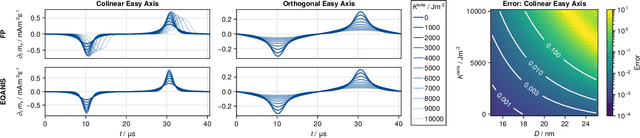
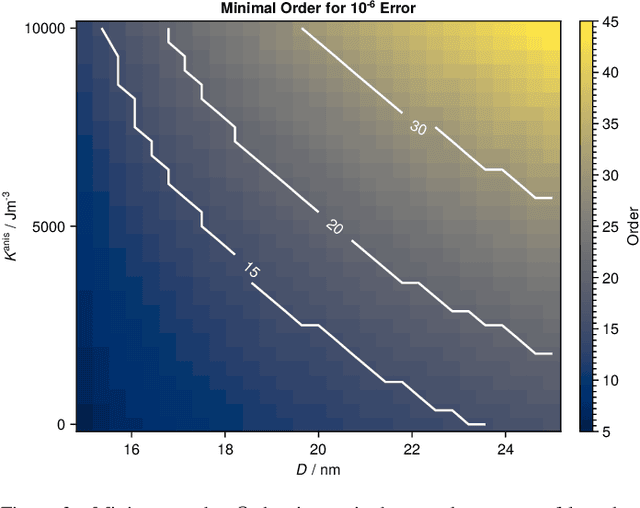

Magnetic particle imaging is a tracer-based tomographic imaging technique that allows the concentration of magnetic nanoparticles to be determined with high spatio-temporal resolution. To reconstruct an image of the tracer concentration, the magnetization dynamics of the particles must be accurately modeled. A popular ensemble model is based on solving the Fokker-Plank equation, taking into account either Brownian or N\'eel dynamics. The disadvantage of this model is that it is computationally expensive due to an underlying stiff differential equation. A simplified model is the equilibrium model, which can be evaluated directly but in most relevant cases it suffers from a non-negligible modeling error. In the present work, we investigate an extended version of the equilibrium model that can account for particle anisotropy. We show that this model can be expressed as a series of Bessel functions, which can be truncated based on a predefined accuracy, leading to very short computation times, which are about three orders of magnitude lower than equivalent Fokker-Planck computation times. We investigate the accuracy of the model for 2D Lissajous MPI sequences and show that the difference between the Fokker-Planck and the equilibrium model with anisotropy is sufficiently small so that the latter model can be used for image reconstruction on experimental data with only marginal loss of image quality, even compared to a system matrix-based reconstruction.
Audio Scene Classification with Deep Recurrent Neural Networks
Jun 05, 2017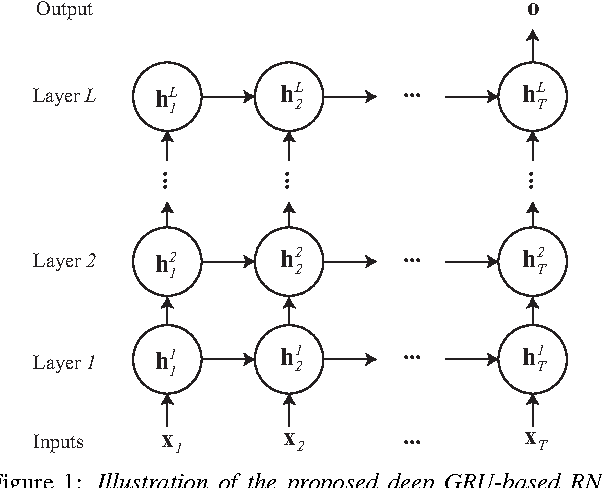

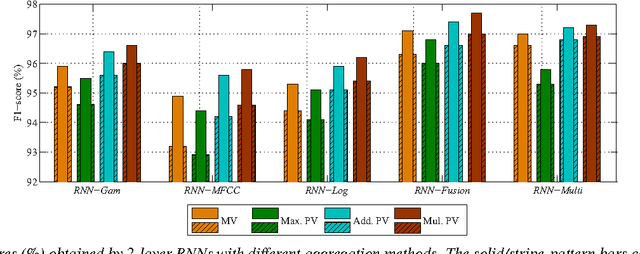
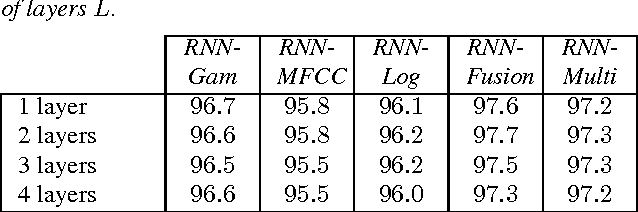
We introduce in this work an efficient approach for audio scene classification using deep recurrent neural networks. An audio scene is firstly transformed into a sequence of high-level label tree embedding feature vectors. The vector sequence is then divided into multiple subsequences on which a deep GRU-based recurrent neural network is trained for sequence-to-label classification. The global predicted label for the entire sequence is finally obtained via aggregation of subsequence classification outputs. We will show that our approach obtains an F1-score of 97.7% on the LITIS Rouen dataset, which is the largest dataset publicly available for the task. Compared to the best previously reported result on the dataset, our approach is able to reduce the relative classification error by 35.3%.
CNN-LTE: a Class of 1-X Pooling Convolutional Neural Networks on Label Tree Embeddings for Audio Scene Recognition
Aug 15, 2016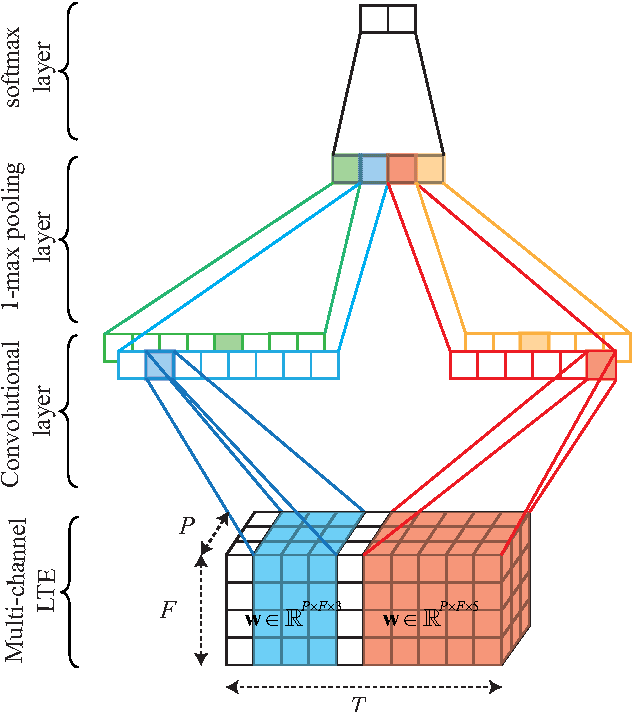
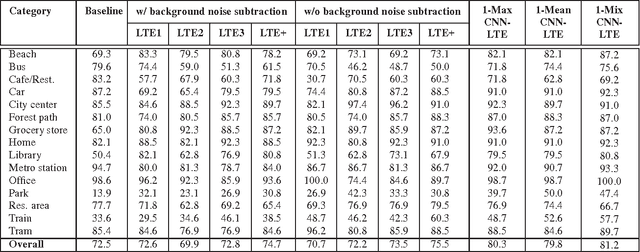

We describe in this report our audio scene recognition system submitted to the DCASE 2016 challenge. Firstly, given the label set of the scenes, a label tree is automatically constructed. This category taxonomy is then used in the feature extraction step in which an audio scene instance is represented by a label tree embedding image. Different convolutional neural networks, which are tailored for the task at hand, are finally learned on top of the image features for scene recognition. Our system reaches an overall recognition accuracy of 81.2% and 83.3% and outperforms the DCASE 2016 baseline with absolute improvements of 8.7% and 6.1% on the development and test data, respectively.
CaR-FOREST: Joint Classification-Regression Decision Forests for Overlapping Audio Event Detection
Aug 15, 2016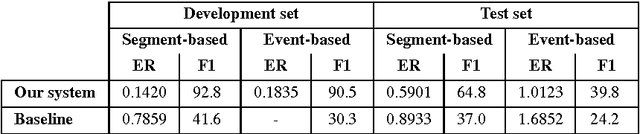
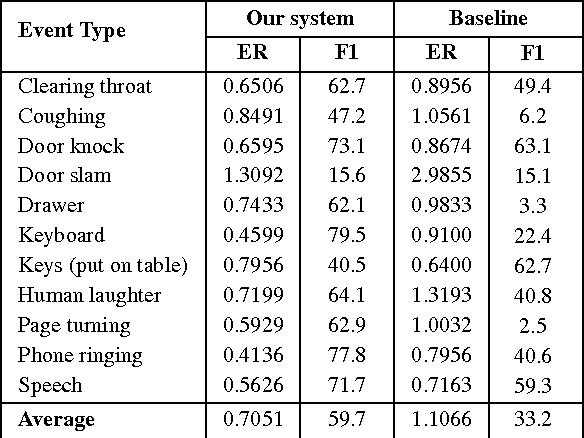
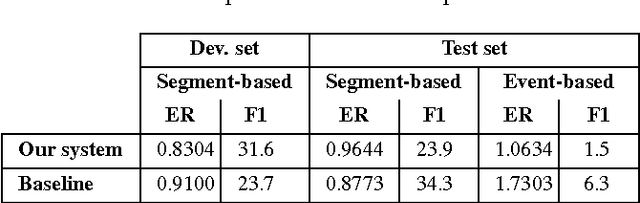
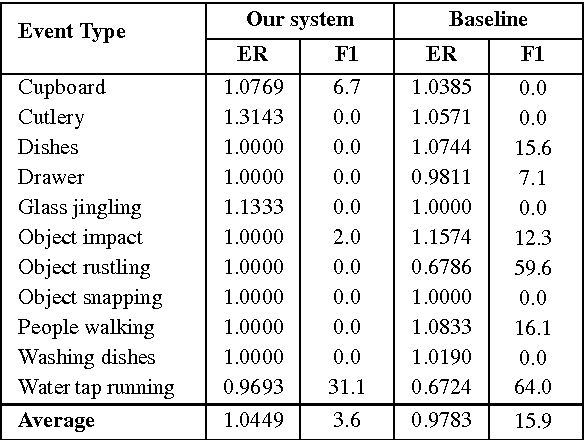
This report describes our submissions to Task2 and Task3 of the DCASE 2016 challenge. The systems aim at dealing with the detection of overlapping audio events in continuous streams, where the detectors are based on random decision forests. The proposed forests are jointly trained for classification and regression simultaneously. Initially, the training is classification-oriented to encourage the trees to select discriminative features from overlapping mixtures to separate positive audio segments from the negative ones. The regression phase is then carried out to let the positive audio segments vote for the event onsets and offsets, and therefore model the temporal structure of audio events. One random decision forest is specifically trained for each event category of interest. Experimental results on the development data show that our systems significantly outperform the baseline on the Task2 evaluation while they are inferior to the baseline in the Task3 evaluation.
Label Tree Embeddings for Acoustic Scene Classification
Jul 26, 2016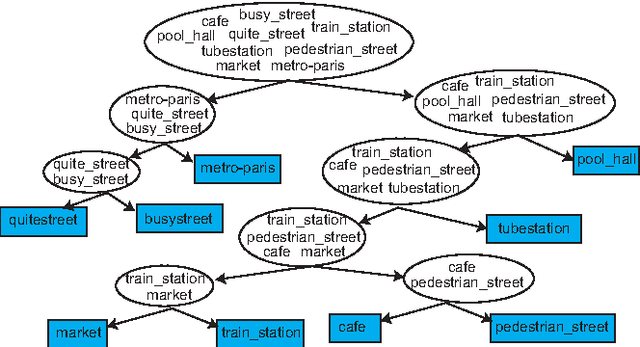

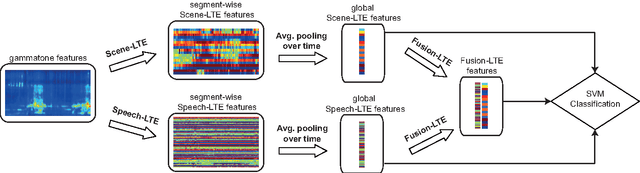
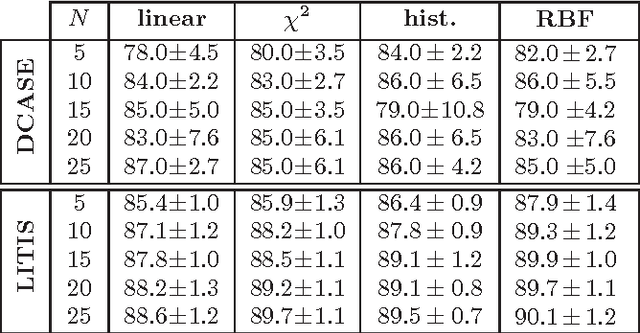
We present in this paper an efficient approach for acoustic scene classification by exploring the structure of class labels. Given a set of class labels, a category taxonomy is automatically learned by collectively optimizing a clustering of the labels into multiple meta-classes in a tree structure. An acoustic scene instance is then embedded into a low-dimensional feature representation which consists of the likelihoods that it belongs to the meta-classes. We demonstrate state-of-the-art results on two different datasets for the acoustic scene classification task, including the DCASE 2013 and LITIS Rouen datasets.
Robust Audio Event Recognition with 1-Max Pooling Convolutional Neural Networks
Jun 22, 2016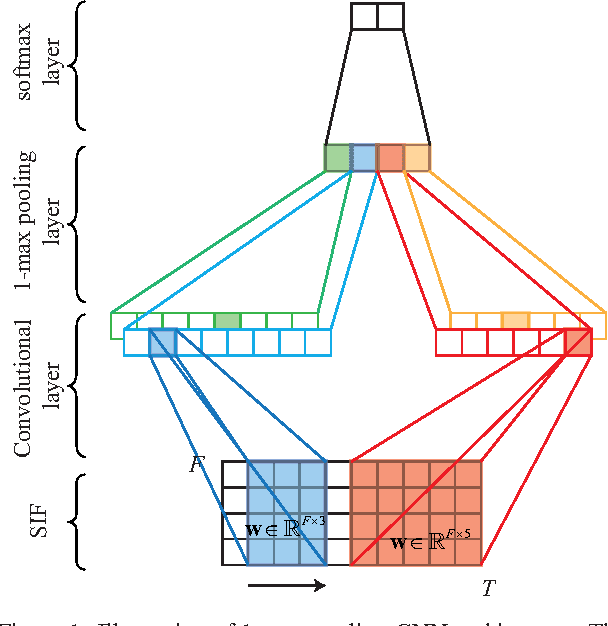

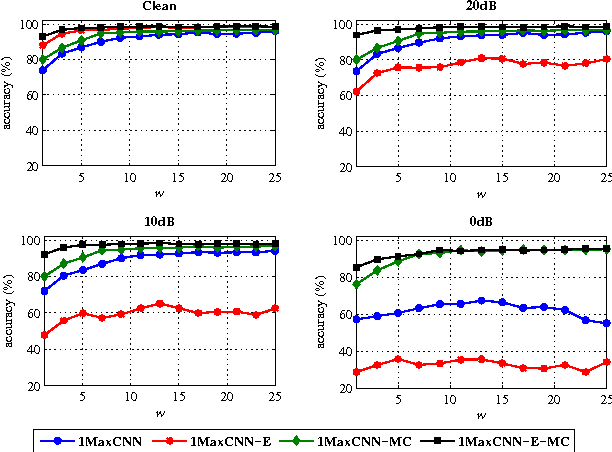
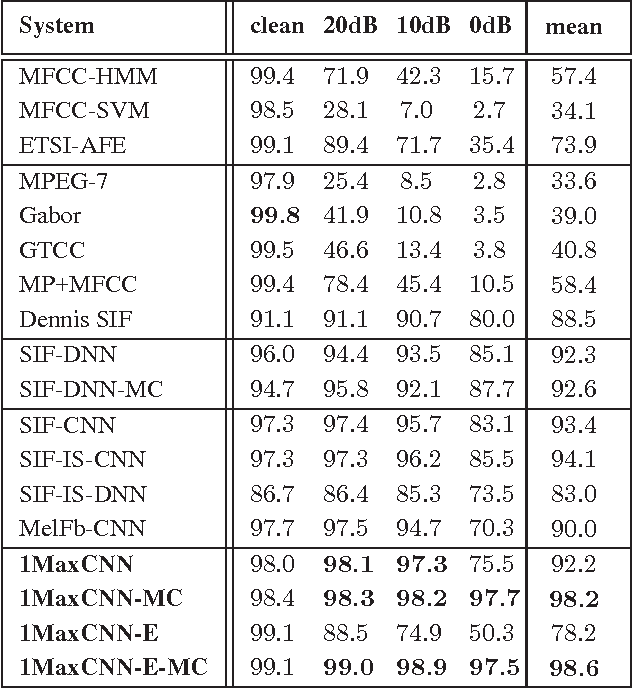
We present in this paper a simple, yet efficient convolutional neural network (CNN) architecture for robust audio event recognition. Opposing to deep CNN architectures with multiple convolutional and pooling layers topped up with multiple fully connected layers, the proposed network consists of only three layers: convolutional, pooling, and softmax layer. Two further features distinguish it from the deep architectures that have been proposed for the task: varying-size convolutional filters at the convolutional layer and 1-max pooling scheme at the pooling layer. In intuition, the network tends to select the most discriminative features from the whole audio signals for recognition. Our proposed CNN not only shows state-of-the-art performance on the standard task of robust audio event recognition but also outperforms other deep architectures up to 4.5% in terms of recognition accuracy, which is equivalent to 76.3% relative error reduction.
Learning Compact Structural Representations for Audio Events Using Regressor Banks
Apr 29, 2016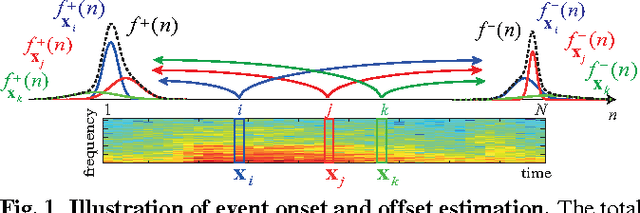

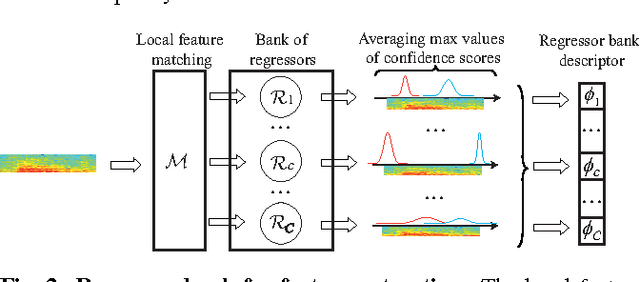
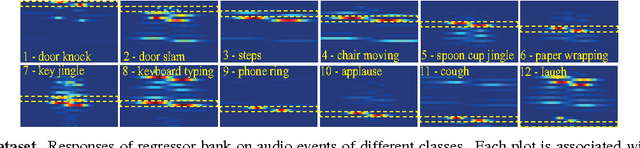
We introduce a new learned descriptor for audio signals which is efficient for event representation. The entries of the descriptor are produced by evaluating a set of regressors on the input signal. The regressors are class-specific and trained using the random regression forests framework. Given an input signal, each regressor estimates the onset and offset positions of the target event. The estimation confidence scores output by a regressor are then used to quantify how the target event aligns with the temporal structure of the corresponding category. Our proposed descriptor has two advantages. First, it is compact, i.e. the dimensionality of the descriptor is equal to the number of event classes. Second, we show that even simple linear classification models, trained on our descriptor, yield better accuracies on audio event classification task than not only the nonlinear baselines but also the state-of-the-art results.