 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Scene Classification with Deep Recurrent Neural Networks
Jun 05, 2017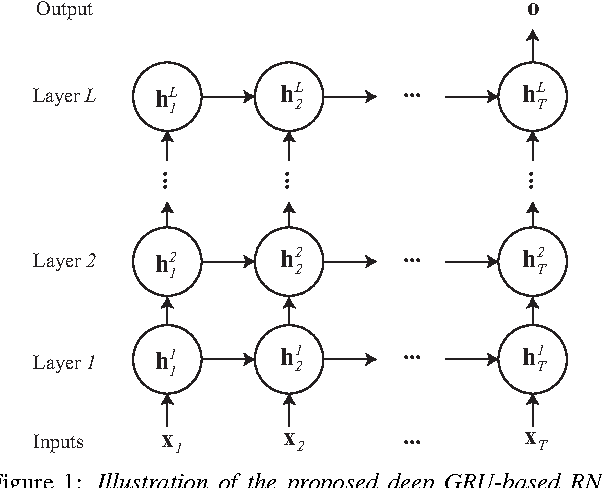

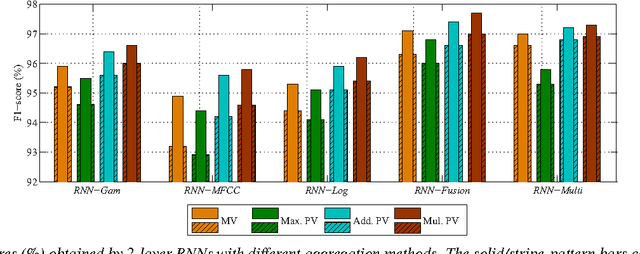
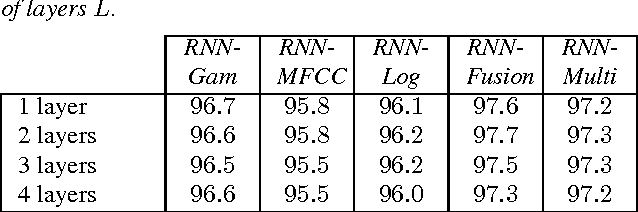
We introduce in this work an efficient approach for audio scene classification using deep recurrent neural networks. An audio scene is firstly transformed into a sequence of high-level label tree embedding feature vectors. The vector sequence is then divided into multiple subsequences on which a deep GRU-based recurrent neural network is trained for sequence-to-label classification. The global predicted label for the entire sequence is finally obtained via aggregation of subsequence classification outputs. We will show that our approach obtains an F1-score of 97.7% on the LITIS Rouen dataset, which is the largest dataset publicly available for the task. Compared to the best previously reported result on the dataset, our approach is able to reduce the relative classification error by 35.3%.