 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Label Attention Model for ICD Coding from Clinical Text
Paper and Code
Jul 13, 2020


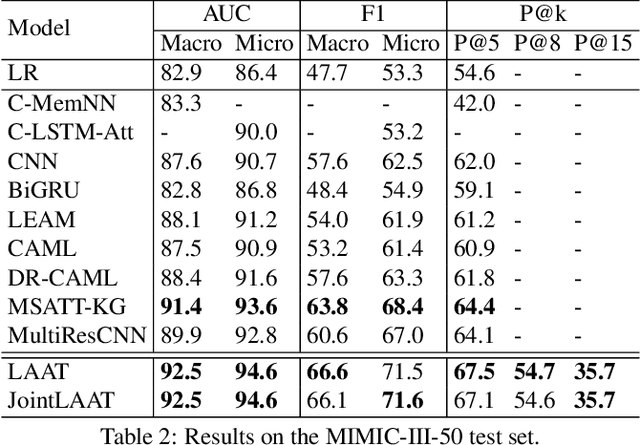
ICD coding is a process of assigning the International Classification of Disease diagnosis codes to clinical/medical notes documented by health professionals (e.g. clinicians). This process requires significant human resources, and thus is costly and prone to error. To handle the problem, machine learning has been utilized for automatic ICD coding. Previous state-of-the-art models were based on convolutional neural networks, using a single/several fixed window sizes. However, the lengths and interdependence between text fragments related to ICD codes in clinical text vary significantly, leading to the difficulty of deciding what the best window sizes are. In this paper, we propose a new label attention model for automatic ICD coding, which can handle both the various lengths and the interdependence of the ICD code related text fragments. Furthermore, as the majority of ICD codes are not frequently used, leading to the extremely imbalanced data issue, we additionally propose a hierarchical joint learning mechanism extending our label attention model to handle the issue, using the hierarchical relationships among the codes. Our label attention model achieves new state-of-the-art results on three benchmark MIMIC datasets, and the joint learning mechanism helps improve the performances for infrequent codes.