 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Auto-Encoders with Sequential Learning for Multimodal Dimensional Emotion Recognition
Paper and Code
Apr 28, 2020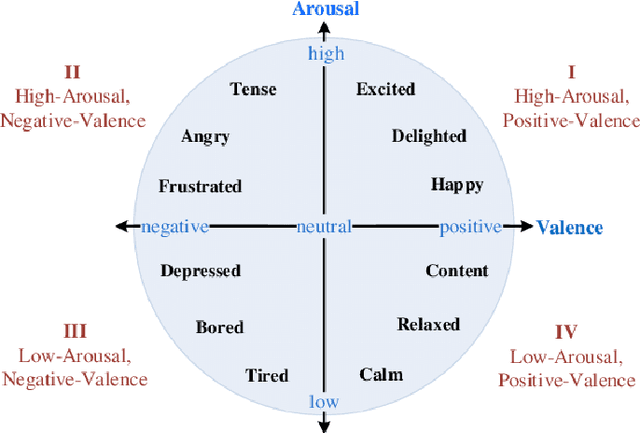
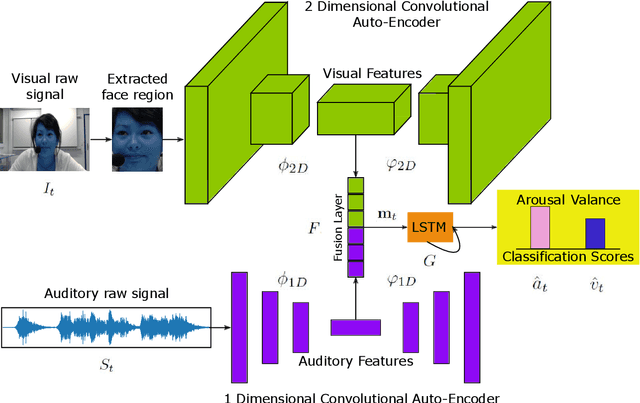
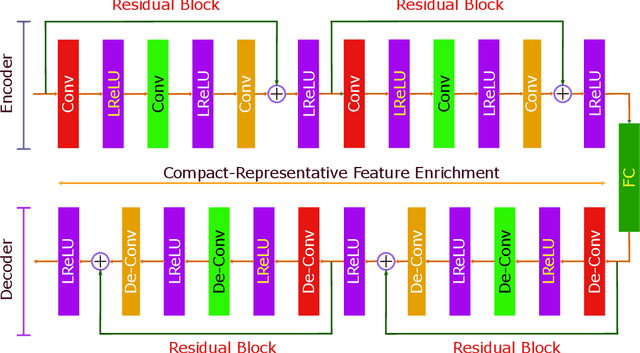
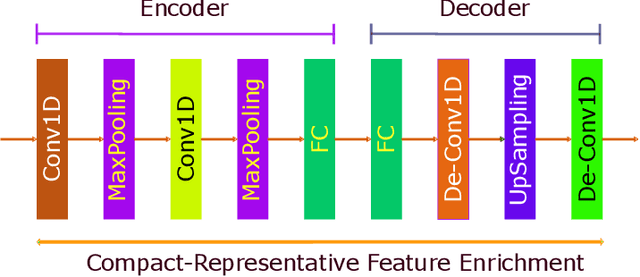
Multimodal dimensional emotion recognition has drawn a great attention from the affective computing community and numerous schemes have been extensively investigated, making a significant progress in this area. However, several questions still remain unanswered for most of existing approaches including: (i) how to simultaneously learn compact yet representative features from multimodal data, (ii) how to effectively capture complementary features from multimodal streams, and (iii) how to perform all the tasks in an end-to-end manner. To address these challenges, in this paper, we propose a novel deep neural network architecture consisting of a two-stream auto-encoder and a long short term memory for effectively integrating visual and audio signal streams for emotion recognition. To validate the robustness of our proposed architecture, we carry out extensive experiments on the multimodal emotion in the wild dataset: RECOLA. Experimental results show that the proposed method achieves state-of-the-art recognition performance and surpasses existing schemes by a significant margin.