 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConDense: Consistent 2D/3D Pre-training for Dense and Sparse Features from Multi-View Images
Paper and Code
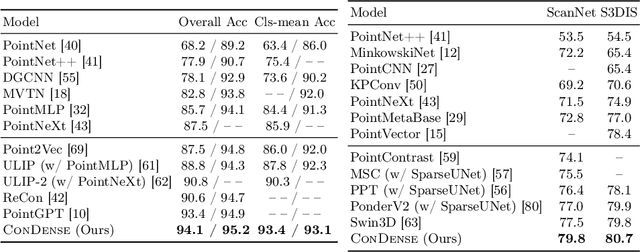
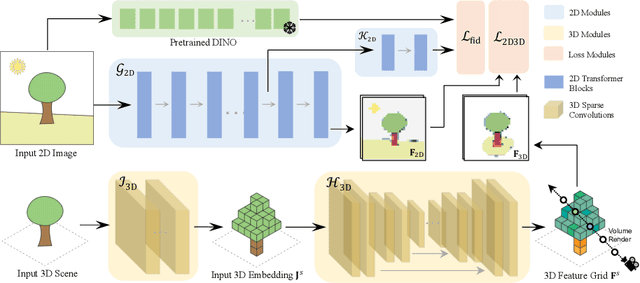
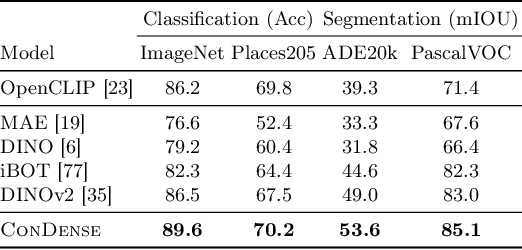
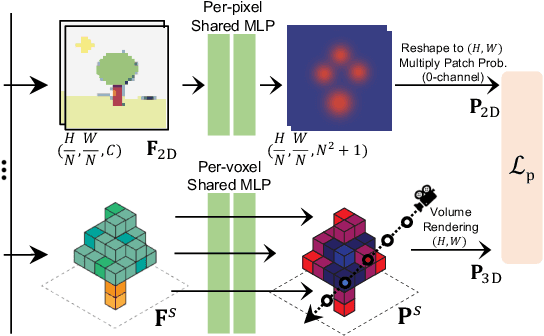
To advance the state of the art in the creation of 3D foundation models, this paper introduces the ConDense framework for 3D pre-training utilizing existing pre-trained 2D networks and large-scale multi-view datasets. We propose a novel 2D-3D joint training scheme to extract co-embedded 2D and 3D features in an end-to-end pipeline, where 2D-3D feature consistency is enforced through a volume rendering NeRF-like ray marching process. Using dense per pixel features we are able to 1) directly distill the learned priors from 2D models to 3D models and create useful 3D backbones, 2) extract more consistent and less noisy 2D features, 3) formulate a consistent embedding space where 2D, 3D, and other modalities of data (e.g., natural language prompts) can be jointly queried. Furthermore, besides dense features, ConDense can be trained to extract sparse features (e.g., key points), also with 2D-3D consistency -- condensing 3D NeRF representations into compact sets of decorated key points. We demonstrate that our pre-trained model provides good initialization for various 3D tasks including 3D classification and segmentation, outperforming other 3D pre-training methods by a significant margin. It also enables, by exploiting our sparse features, additional useful downstream tasks, such as matching 2D images to 3D scenes, detecting duplicate 3D scenes, and querying a repository of 3D scenes through natural language -- all quite efficiently and without any per-scene fine-tuning.