 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Multitask Curriculum for Neural Machine Translation
Paper and Code


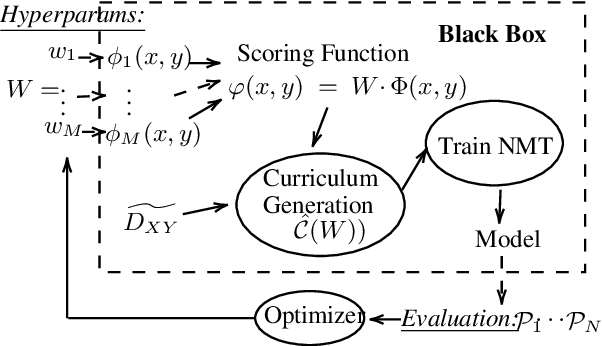

Existing curriculum learning research in neural machine translation (NMT) mostly focuses on a single final task such as selecting data for a domain or for denoising, and considers in-task example selection. This paper studies the data selection problem in multitask setting. We present a method to learn a multitask curriculum on a single, diverse, potentially noisy training dataset. It computes multiple data selection scores for each training example, each score measuring how useful the example is to a certain task. It uses Bayesian optimization to learn a linear weighting of these per-instance scores, and then sorts the data to form a curriculum. We experiment with three domain translation tasks: two specific domains and the general domain, and demonstrate that the learned multitask curriculum delivers results close to individually optimized models and brings solid gains over no curriculum training, across all test sets.