 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Bartering Behaviour in Multi-Agent Reinforcement Learning
May 13, 2022
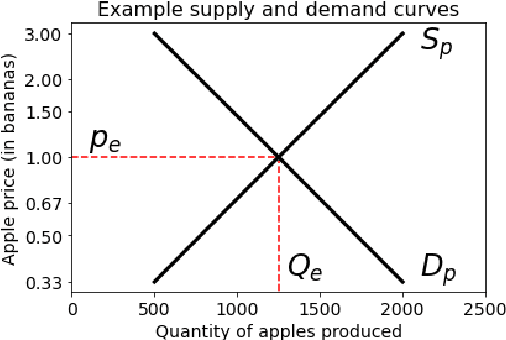
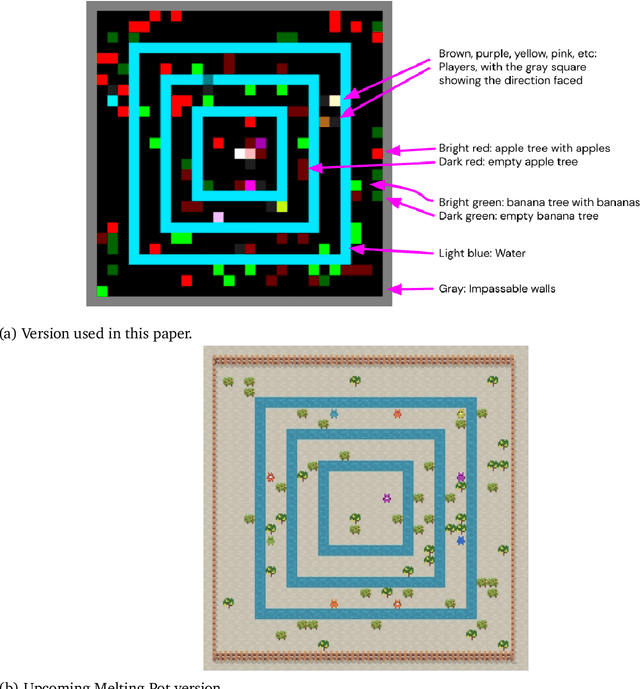

Advances in artificial intelligence often stem from the development of new environments that abstract real-world situations into a form where research can be done conveniently. This paper contributes such an environment based on ideas inspired by elementary Microeconomics. Agents learn to produce resources in a spatially complex world, trade them with one another, and consume those that they prefer. We show that the emergent production, consumption, and pricing behaviors respond to environmental conditions in the directions predicted by supply and demand shifts in Microeconomics. We also demonstrate settings where the agents' emergent prices for goods vary over space, reflecting the local abundance of goods. After the price disparities emerge, some agents then discover a niche of transporting goods between regions with different prevailing prices -- a profitable strategy because they can buy goods where they are cheap and sell them where they are expensive. Finally, in a series of ablation experiments, we investigate how choices in the environmental rewards, bartering actions, agent architecture, and ability to consume tradable goods can either aid or inhibit the emergence of this economic behavior. This work is part of the environment development branch of a research program that aims to build human-like artificial general intelligence through multi-agent interactions in simulated societies. By exploring which environment features are needed for the basic phenomena of elementary microeconomics to emerge automatically from learning, we arrive at an environment that differs from those studied in prior multi-agent reinforcement learning work along several dimensions. For example, the model incorporates heterogeneous tastes and physical abilities, and agents negotiate with one another as a grounded form of communication.
The Frost Hollow Experiments: Pavlovian Signalling as a Path to Coordination and Communication Between Agents
Mar 17, 2022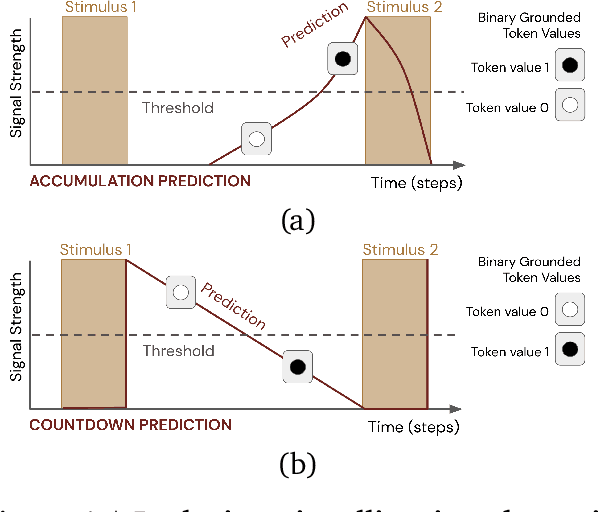

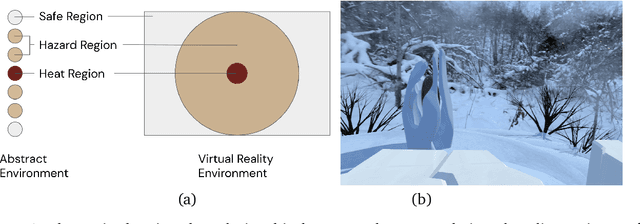
Learned communication between agents is a powerful tool when approaching decision-making problems that are hard to overcome by any single agent in isolation. However, continual coordination and communication learning between machine agents or human-machine partnerships remains a challenging open problem. As a stepping stone toward solving the continual communication learning problem, in this paper we contribute a multi-faceted study into what we term Pavlovian signalling -- a process by which learned, temporally extended predictions made by one agent inform decision-making by another agent with different perceptual access to their shared environment. We seek to establish how different temporal processes and representational choices impact Pavlovian signalling between learning agents. To do so, we introduce a partially observable decision-making domain we call the Frost Hollow. In this domain a prediction learning agent and a reinforcement learning agent are coupled into a two-part decision-making system that seeks to acquire sparse reward while avoiding time-conditional hazards. We evaluate two domain variations: 1) machine prediction and control learning in a linear walk, and 2) a prediction learning machine interacting with a human participant in a virtual reality environment. Our results showcase the speed of learning for Pavlovian signalling, the impact that different temporal representations do (and do not) have on agent-agent coordination, and how temporal aliasing impacts agent-agent and human-agent interactions differently. As a main contribution, we establish Pavlovian signalling as a natural bridge between fixed signalling paradigms and fully adaptive communication learning. Our results therefore point to an actionable, constructivist path towards continual communication learning between reinforcement learning agents, with potential impact in a range of real-world settings.
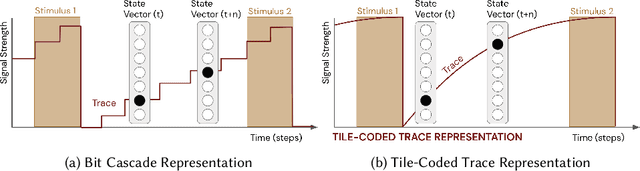
Pavlovian Signalling with General Value Functions in Agent-Agent Temporal Decision Making
Jan 11, 2022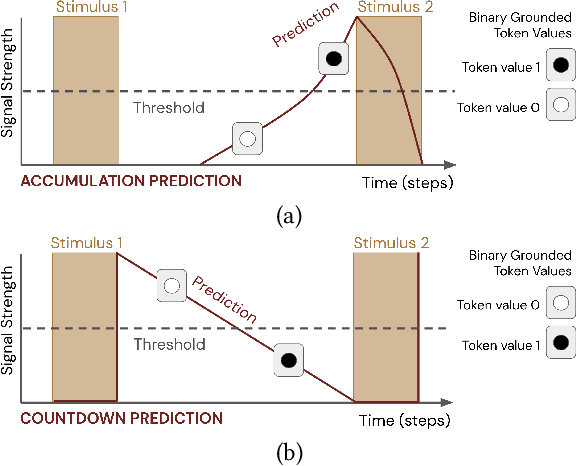
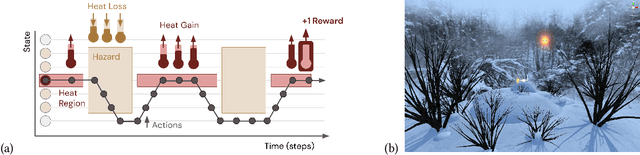
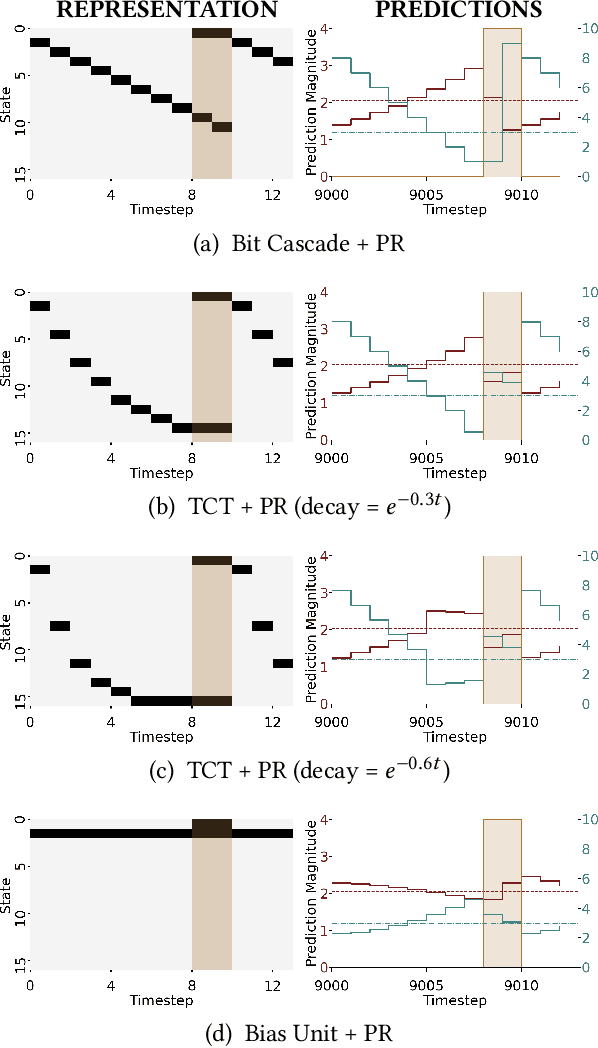
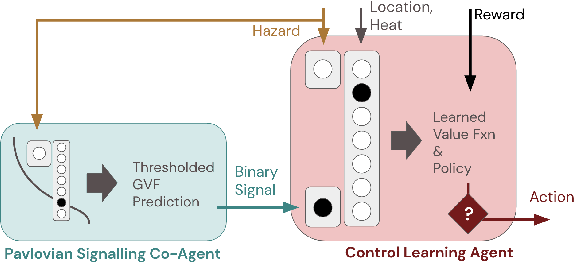
In this paper, we contribute a multi-faceted study into Pavlovian signalling -- a process by which learned, temporally extended predictions made by one agent inform decision-making by another agent. Signalling is intimately connected to time and timing. In service of generating and receiving signals, humans and other animals are known to represent time, determine time since past events, predict the time until a future stimulus, and both recognize and generate patterns that unfold in time. We investigate how different temporal processes impact coordination and signalling between learning agents by introducing a partially observable decision-making domain we call the Frost Hollow. In this domain, a prediction learning agent and a reinforcement learning agent are coupled into a two-part decision-making system that works to acquire sparse reward while avoiding time-conditional hazards. We evaluate two domain variations: machine agents interacting in a seven-state linear walk, and human-machine interaction in a virtual-reality environment. Our results showcase the speed of learning for Pavlovian signalling, the impact that different temporal representations do (and do not) have on agent-agent coordination, and how temporal aliasing impacts agent-agent and human-agent interactions differently. As a main contribution, we establish Pavlovian signalling as a natural bridge between fixed signalling paradigms and fully adaptive communication learning between two agents. We further show how to computationally build this adaptive signalling process out of a fixed signalling process, characterized by fast continual prediction learning and minimal constraints on the nature of the agent receiving signals. Our results therefore suggest an actionable, constructivist path towards communication learning between reinforcement learning agents.
Assessing Human Interaction in Virtual Reality With Continually Learning Prediction Agents Based on Reinforcement Learning Algorithms: A Pilot Study
Dec 14, 2021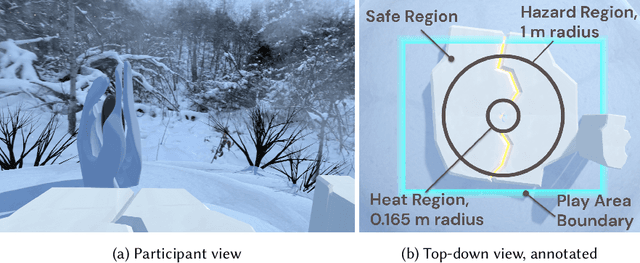
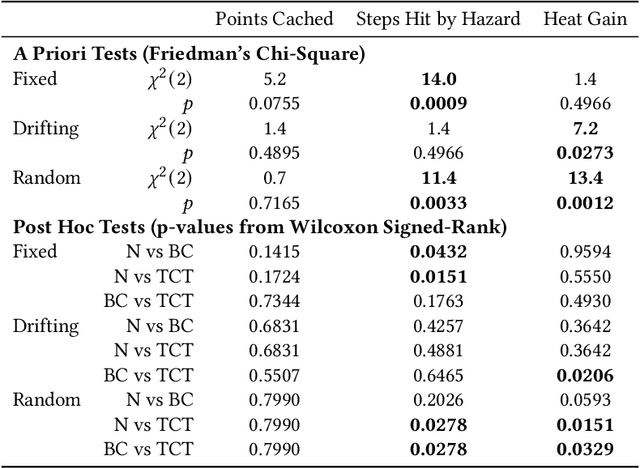
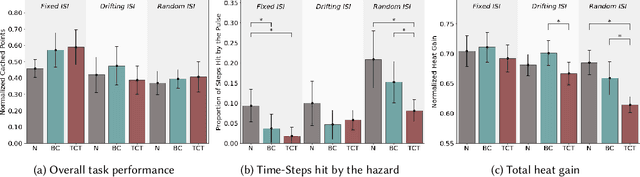
Artificial intelligence systems increasingly involve continual learning to enable flexibility in general situations that are not encountered during system training. Human interaction with autonomous systems is broadly studied, but research has hitherto under-explored interactions that occur while the system is actively learning, and can noticeably change its behaviour in minutes. In this pilot study, we investigate how the interaction between a human and a continually learning prediction agent develops as the agent develops competency. Additionally, we compare two different agent architectures to assess how representational choices in agent design affect the human-agent interaction. We develop a virtual reality environment and a time-based prediction task wherein learned predictions from a reinforcement learning (RL) algorithm augment human predictions. We assess how a participant's performance and behaviour in this task differs across agent types, using both quantitative and qualitative analyses. Our findings suggest that human trust of the system may be influenced by early interactions with the agent, and that trust in turn affects strategic behaviour, but limitations of the pilot study rule out any conclusive statement. We identify trust as a key feature of interaction to focus on when considering RL-based technologies, and make several recommendations for modification to this study in preparation for a larger-scale investigation. A video summary of this paper can be found at https://youtu.be/oVYJdnBqTwQ .