 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromoting Non-Cooperation Through Ordering
Mar 31, 2023



In many real world situations, like minor traffic offenses in big cities, a central authority is tasked with periodic administering punishments to a large number of individuals. Common practice is to give each individual a chance to suffer a smaller fine and be guaranteed to avoid the legal process with probable considerably larger punishment. However, thanks to the large number of offenders and a limited capacity of the central authority, the individual risk is typically small and a rational individual will not choose to pay the fine. Here we show that if the central authority processes the offenders in a publicly known order, it properly incentives the offenders to pay the fine. We show analytically and on realistic experiments that our mechanism promotes non-cooperation and incentives individuals to pay. Moreover, the same holds for an arbitrary coalition. We quantify the expected total payment the central authority receives, and show it increases considerably.
Learning not to Regret
Mar 02, 2023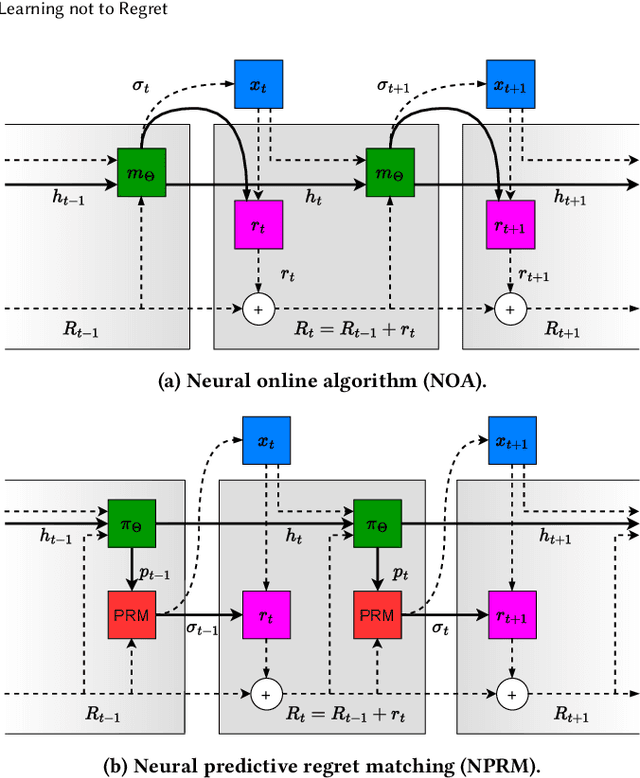
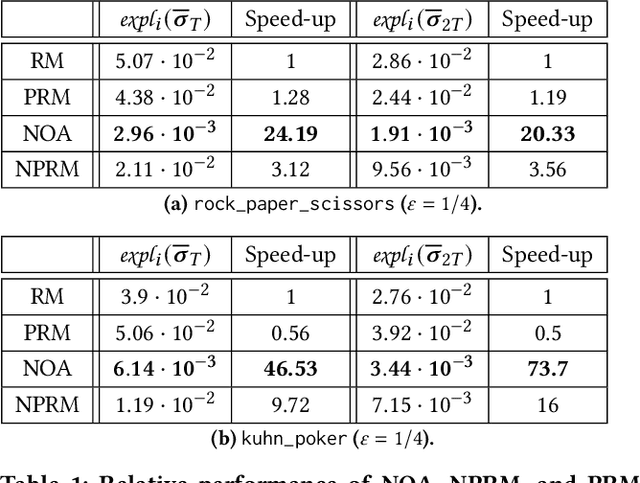
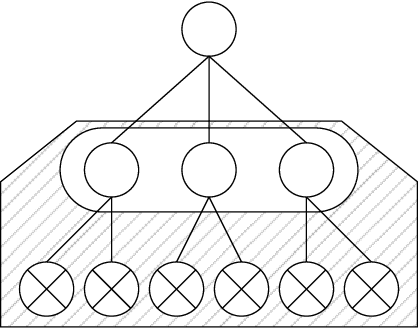
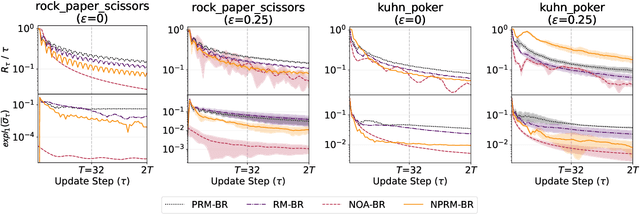
Regret minimization is a key component of many algorithms for finding Nash equilibria in imperfect-information games. To scale to games that cannot fit in memory, we can use search with value functions. However, calling the value functions repeatedly in search can be expensive. Therefore, it is desirable to minimize regret in the search tree as fast as possible. We propose to accelerate the regret minimization by introducing a general ``learning not to regret'' framework, where we meta-learn the regret minimizer. The resulting algorithm is guaranteed to minimize regret in arbitrary settings and is (meta)-learned to converge fast on a selected distribution of games. Our experiments show that meta-learned algorithms converge substantially faster than prior regret minimization algorithms.