Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLaC at SemEval-2016 Task 11: Exploring linguistic and psycho-linguistic Features for Complex Word Identification
Paper and Code
Sep 08, 2017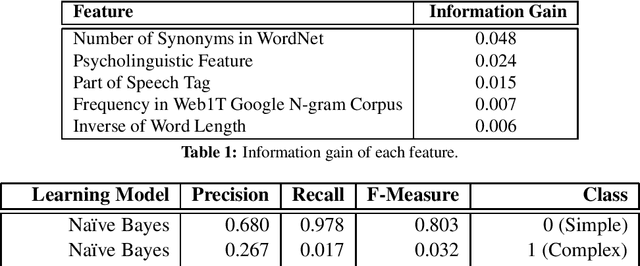

This paper describes the system deployed by the CLaC-EDLK team to the "SemEval 2016, Complex Word Identification task". The goal of the task is to identify if a given word in a given context is "simple" or "complex". Our system relies on linguistic features and cognitive complexity. We used several supervised models, however the Random Forest model outperformed the others. Overall our best configuration achieved a G-score of 68.8% in the task, ranking our system 21 out of 45.
* In Proceedings of the International Workshop on Semantic Evaluation
(SemEval-2016), a workshop of the 15th Annual Conference of the North
American Chapter of the Association for Computational Linguistics: Human
Language Technologies (NAACL-2016) pp 982-985. June 16-17, San Diego,
California
View paper on