 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Parameter Space Symmetries for Reasoning Skill Transfer in LLMs
Nov 13, 2025Task arithmetic is a powerful technique for transferring skills between Large Language Models (LLMs), but it often suffers from negative interference when models have diverged during training. We address this limitation by first aligning the models' parameter spaces, leveraging the inherent permutation, rotation, and scaling symmetries of Transformer architectures. We adapt parameter space alignment for modern Grouped-Query Attention (GQA) and SwiGLU layers, exploring both weight-based and activation-based approaches. Using this alignment-first strategy, we successfully transfer advanced reasoning skills to a non-reasoning model. Experiments on challenging reasoning benchmarks show that our method consistently outperforms standard task arithmetic. This work provides an effective approach for merging and transferring specialized skills across evolving LLM families, reducing redundant fine-tuning and enhancing model adaptability.
Less is More: Undertraining Experts Improves Model Upcycling
Jun 17, 2025Modern deep learning is increasingly characterized by the use of open-weight foundation models that can be fine-tuned on specialized datasets. This has led to a proliferation of expert models and adapters, often shared via platforms like HuggingFace and AdapterHub. To leverage these resources, numerous model upcycling methods have emerged, enabling the reuse of fine-tuned models in multi-task systems. A natural pipeline has thus formed to harness the benefits of transfer learning and amortize sunk training costs: models are pre-trained on general data, fine-tuned on specific tasks, and then upcycled into more general-purpose systems. A prevailing assumption is that improvements at one stage of this pipeline propagate downstream, leading to gains at subsequent steps. In this work, we challenge that assumption by examining how expert fine-tuning affects model upcycling. We show that long fine-tuning of experts that optimizes for their individual performance leads to degraded merging performance, both for fully fine-tuned and LoRA-adapted models, and to worse downstream results when LoRA adapters are upcycled into MoE layers. We trace this degradation to the memorization of a small set of difficult examples that dominate late fine-tuning steps and are subsequently forgotten during merging. Finally, we demonstrate that a task-dependent aggressive early stopping strategy can significantly improve upcycling performance.
Non-Uniform Parameter-Wise Model Merging
Dec 20, 2024Combining multiple machine learning models has long been a technique for enhancing performance, particularly in distributed settings. Traditional approaches, such as model ensembles, work well, but are expensive in terms of memory and compute. Recently, methods based on averaging model parameters have achieved good results in some settings and have gained popularity. However, merging models initialized differently that do not share a part of their training trajectories can yield worse results than simply using the base models, even after aligning their neurons. In this paper, we introduce a novel approach, Non-uniform Parameter-wise Model Merging, or NP Merge, which merges models by learning the contribution of each parameter to the final model using gradient-based optimization. We empirically demonstrate the effectiveness of our method for merging models of various architectures in multiple settings, outperforming past methods. We also extend NP Merge to handle the merging of multiple models, showcasing its scalability and robustness.
Harmony in Diversity: Merging Neural Networks with Canonical Correlation Analysis
Jul 07, 2024Combining the predictions of multiple trained models through ensembling is generally a good way to improve accuracy by leveraging the different learned features of the models, however it comes with high computational and storage costs. Model fusion, the act of merging multiple models into one by combining their parameters reduces these costs but doesn't work as well in practice. Indeed, neural network loss landscapes are high-dimensional and non-convex and the minima found through learning are typically separated by high loss barriers. Numerous recent works have been focused on finding permutations matching one network features to the features of a second one, lowering the loss barrier on the linear path between them in parameter space. However, permutations are restrictive since they assume a one-to-one mapping between the different models' neurons exists. We propose a new model merging algorithm, CCA Merge, which is based on Canonical Correlation Analysis and aims to maximize the correlations between linear combinations of the model features. We show that our alignment method leads to better performances than past methods when averaging models trained on the same, or differing data splits. We also extend this analysis into the harder setting where more than 2 models are merged, and we find that CCA Merge works significantly better than past methods. Our code is publicly available at https://github.com/shoroi/align-n-merge
Reliability of CKA as a Similarity Measure in Deep Learning
Nov 16, 2022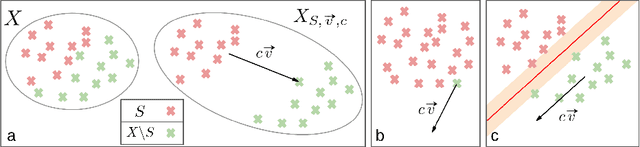

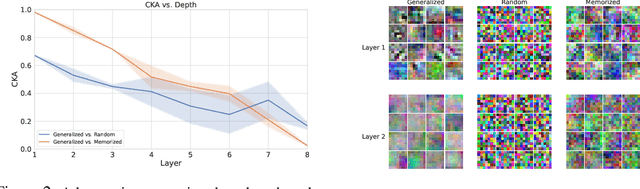
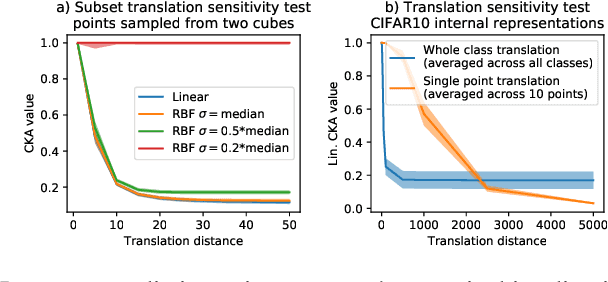
Comparing learned neural representations in neural networks is a challenging but important problem, which has been approached in different ways. The Centered Kernel Alignment (CKA) similarity metric, particularly its linear variant, has recently become a popular approach and has been widely used to compare representations of a network's different layers, of architecturally similar networks trained differently, or of models with different architectures trained on the same data. A wide variety of conclusions about similarity and dissimilarity of these various representations have been made using CKA. In this work we present analysis that formally characterizes CKA sensitivity to a large class of simple transformations, which can naturally occur in the context of modern machine learning. This provides a concrete explanation of CKA sensitivity to outliers, which has been observed in past works, and to transformations that preserve the linear separability of the data, an important generalization attribute. We empirically investigate several weaknesses of the CKA similarity metric, demonstrating situations in which it gives unexpected or counter-intuitive results. Finally we study approaches for modifying representations to maintain functional behaviour while changing the CKA value. Our results illustrate that, in many cases, the CKA value can be easily manipulated without substantial changes to the functional behaviour of the models, and call for caution when leveraging activation alignment metrics.
Visualizing High-Dimensional Trajectories on the Loss-Landscape of ANNs
Jan 31, 2021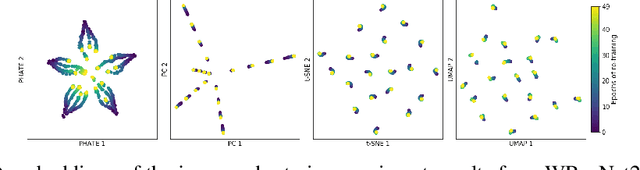
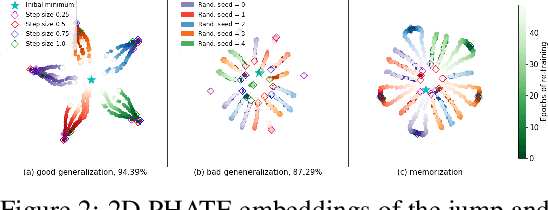
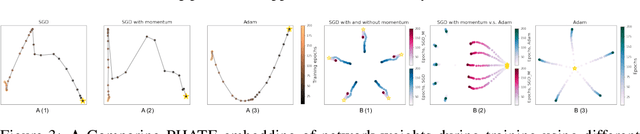
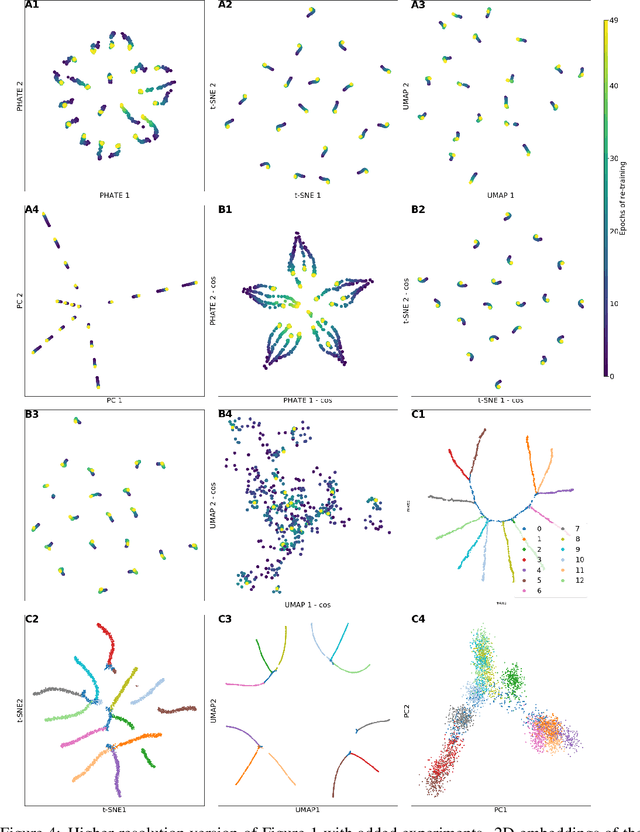
Training artificial neural networks requires the optimization of highly non-convex loss functions. Throughout the years, the scientific community has developed an extensive set of tools and architectures that render this optimization task tractable and a general intuition has been developed for choosing hyper parameters that help the models reach minima that generalize well to unseen data. However, for the most part, the difference in trainability in between architectures, tasks and even the gap in network generalization abilities still remain unexplained. Visualization tools have played a key role in uncovering key geometric characteristics of the loss-landscape of ANNs and how they impact trainability and generalization capabilities. However, most visualizations methods proposed so far have been relatively limited in their capabilities since they are of linear nature and only capture features in a limited number of dimensions. We propose the use of the modern dimensionality reduction method PHATE which represents the SOTA in terms of capturing both global and local structures of high-dimensional data. We apply this method to visualize the loss landscape during and after training. Our visualizations reveal differences in training trajectories and generalization capabilities when used to make comparisons between optimization methods, initializations, architectures, and datasets. Given this success we anticipate this method to be used in making informed choices about these aspects of neural networks.
Advantages of biologically-inspired adaptive neural activation in RNNs during learning
Jun 22, 2020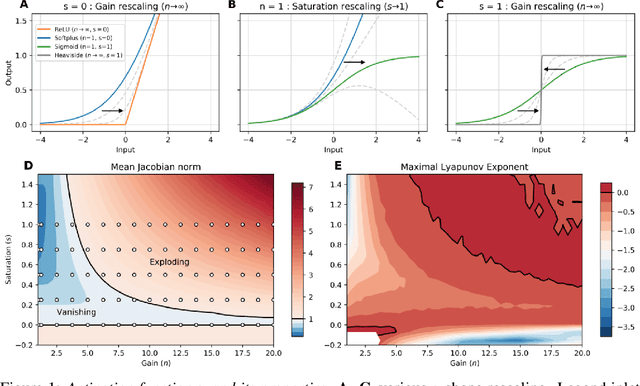
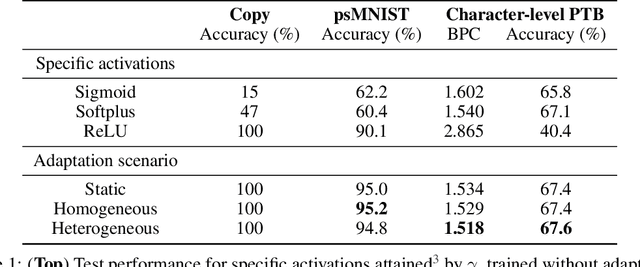
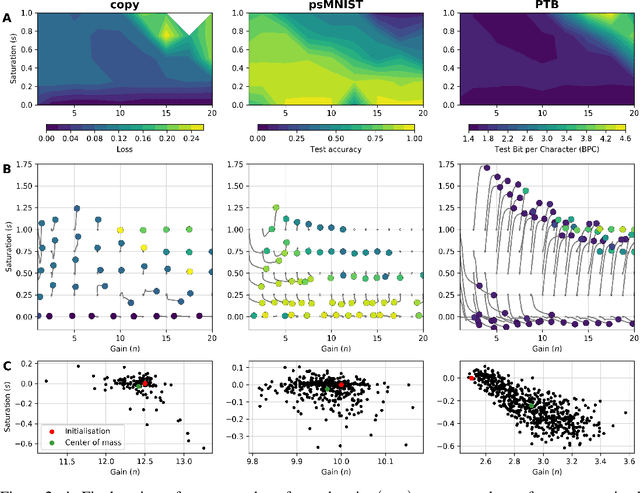

Dynamic adaptation in single-neuron response plays a fundamental role in neural coding in biological neural networks. Yet, most neural activation functions used in artificial networks are fixed and mostly considered as an inconsequential architecture choice. In this paper, we investigate nonlinear activation function adaptation over the large time scale of learning, and outline its impact on sequential processing in recurrent neural networks. We introduce a novel parametric family of nonlinear activation functions, inspired by input-frequency response curves of biological neurons, which allows interpolation between well-known activation functions such as ReLU and sigmoid. Using simple numerical experiments and tools from dynamical systems and information theory, we study the role of neural activation features in learning dynamics. We find that activation adaptation provides distinct task-specific solutions and in some cases, improves both learning speed and performance. Importantly, we find that optimal activation features emerging from our parametric family are considerably different from typical functions used in the literature, suggesting that exploiting the gap between these usual configurations can help learning. Finally, we outline situations where neural activation adaptation alone may help mitigate changes in input statistics in a given task, suggesting mechanisms for transfer learning optimization.
Internal representation dynamics and geometry in recurrent neural networks
Jan 14, 2020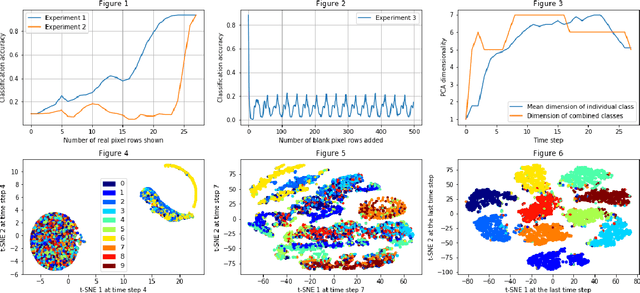
The efficiency of recurrent neural networks (RNNs) in dealing with sequential data has long been established. However, unlike deep, and convolution networks where we can attribute the recognition of a certain feature to every layer, it is unclear what "sub-task" a single recurrent step or layer accomplishes. Our work seeks to shed light onto how a vanilla RNN implements a simple classification task by analysing the dynamics of the network and the geometric properties of its hidden states. We find that early internal representations are evocative of the real labels of the data but this information is not directly accessible to the output layer. Furthermore the network's dynamics and the sequence length are both critical to correct classifications even when there is no additional task relevant information provided.