 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal representation dynamics and geometry in recurrent neural networks
Paper and Code
Jan 14, 2020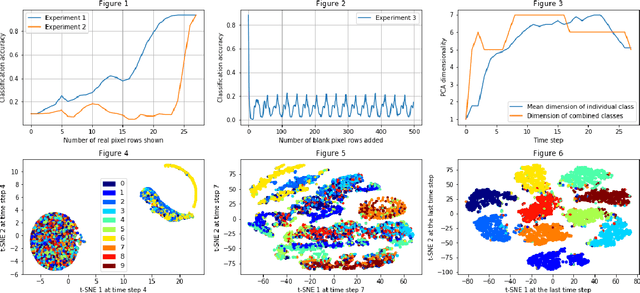
The efficiency of recurrent neural networks (RNNs) in dealing with sequential data has long been established. However, unlike deep, and convolution networks where we can attribute the recognition of a certain feature to every layer, it is unclear what "sub-task" a single recurrent step or layer accomplishes. Our work seeks to shed light onto how a vanilla RNN implements a simple classification task by analysing the dynamics of the network and the geometric properties of its hidden states. We find that early internal representations are evocative of the real labels of the data but this information is not directly accessible to the output layer. Furthermore the network's dynamics and the sequence length are both critical to correct classifications even when there is no additional task relevant information provided.