 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge Proposal Sets for Link Prediction
Jun 30, 2021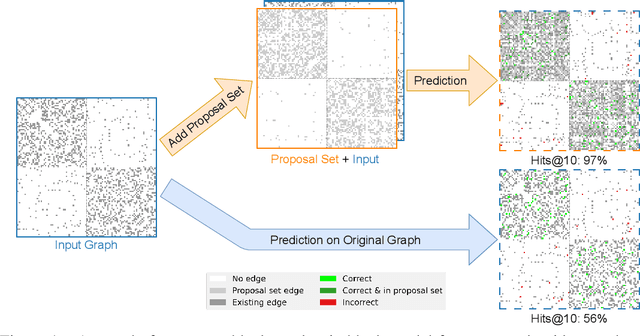
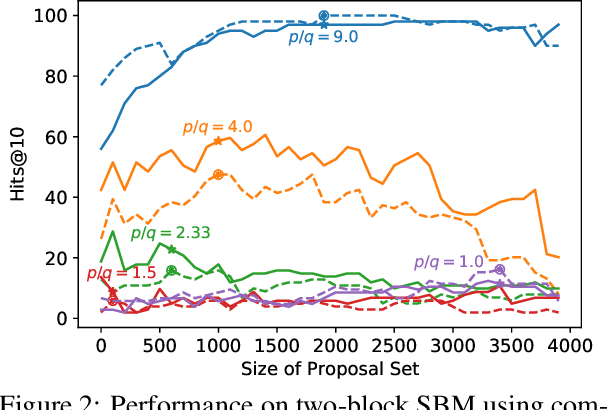
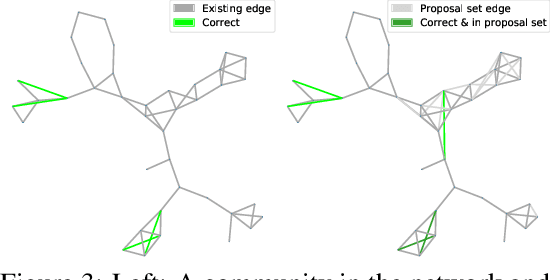
Graphs are a common model for complex relational data such as social networks and protein interactions, and such data can evolve over time (e.g., new friendships) and be noisy (e.g., unmeasured interactions). Link prediction aims to predict future edges or infer missing edges in the graph, and has diverse applications in recommender systems, experimental design, and complex systems. Even though link prediction algorithms strongly depend on the set of edges in the graph, existing approaches typically do not modify the graph topology to improve performance. Here, we demonstrate how simply adding a set of edges, which we call a \emph{proposal set}, to the graph as a pre-processing step can improve the performance of several link prediction algorithms. The underlying idea is that if the edges in the proposal set generally align with the structure of the graph, link prediction algorithms are further guided towards predicting the right edges; in other words, adding a proposal set of edges is a signal-boosting pre-processing step. We show how to use existing link prediction algorithms to generate effective proposal sets and evaluate this approach on various synthetic and empirical datasets. We find that proposal sets meaningfully improve the accuracy of link prediction algorithms based on both neighborhood heuristics and graph neural networks. Code is available at \url{https://github.com/CUAI/Edge-Proposal-Sets}.
Combining Label Propagation and Simple Models Out-performs Graph Neural Networks
Nov 02, 2020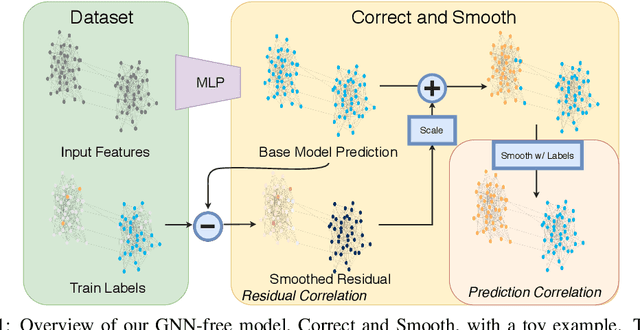
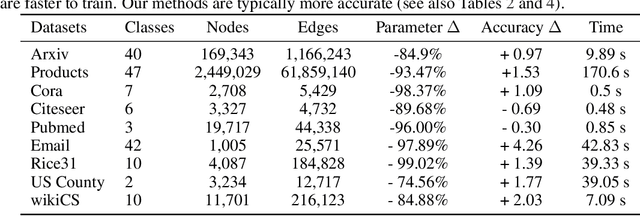
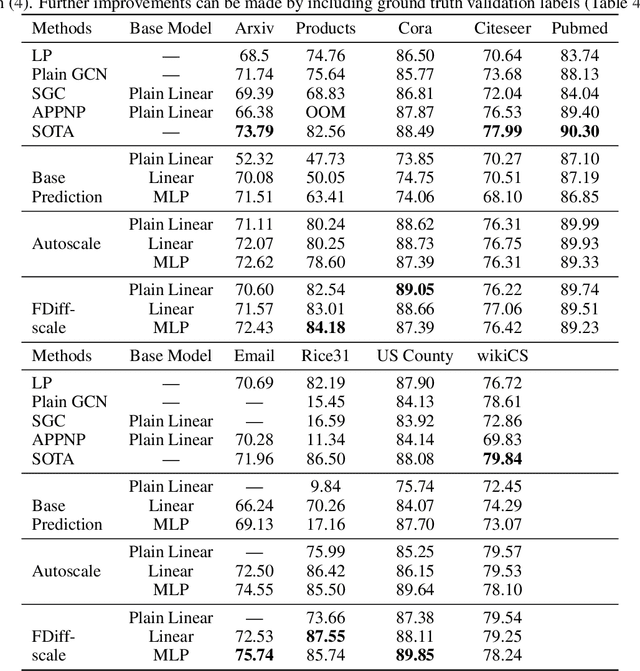
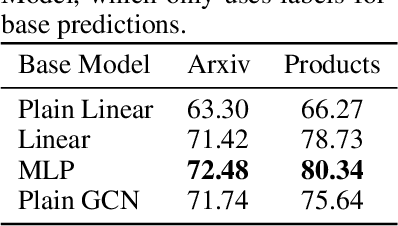
Graph Neural Networks (GNNs) are the predominant technique for learning over graphs. However, there is relatively little understanding of why GNNs are successful in practice and whether they are necessary for good performance. Here, we show that for many standard transductive node classification benchmarks, we can exceed or match the performance of state-of-the-art GNNs by combining shallow models that ignore the graph structure with two simple post-processing steps that exploit correlation in the label structure: (i) an "error correlation" that spreads residual errors in training data to correct errors in test data and (ii) a "prediction correlation" that smooths the predictions on the test data. We call this overall procedure Correct and Smooth (C&S), and the post-processing steps are implemented via simple modifications to standard label propagation techniques from early graph-based semi-supervised learning methods. Our approach exceeds or nearly matches the performance of state-of-the-art GNNs on a wide variety of benchmarks, with just a small fraction of the parameters and orders of magnitude faster runtime. For instance, we exceed the best known GNN performance on the OGB-Products dataset with 137 times fewer parameters and greater than 100 times less training time. The performance of our methods highlights how directly incorporating label information into the learning algorithm (as was done in traditional techniques) yields easy and substantial performance gains. We can also incorporate our techniques into big GNN models, providing modest gains. Our code for the OGB results is at https://github.com/Chillee/CorrectAndSmooth.
Set-Structured Latent Representations
Mar 09, 2020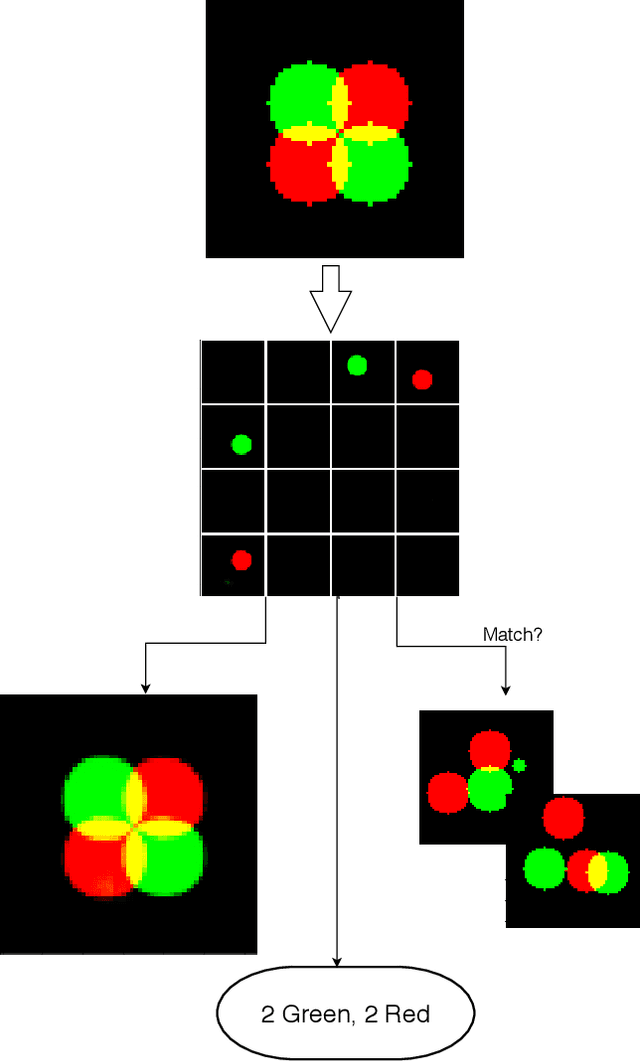
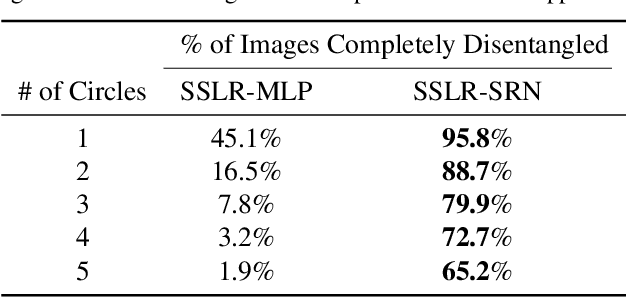

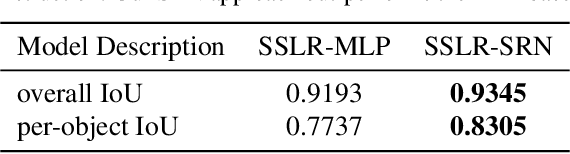
Unstructured data often has latent component structure, such as the objects in an image of a scene. In these situations, the relevant latent structure is an unordered collection or \emph{set}. However, learning such representations directly from data is difficult due to the discrete and unordered structure. Here, we develop a framework for differentiable learning of set-structured latent representations. We show how to use this framework to naturally decompose data such as images into sets of interpretable and meaningful components and demonstrate how existing techniques cannot properly disentangle relevant structure. We also show how to extend our methodology to downstream tasks such as set matching, which uses set-specific operations. Our code is available at https://github.com/CUVL/SSLR.
A Hierarchical Network for Diverse Trajectory Proposals
Jun 09, 2019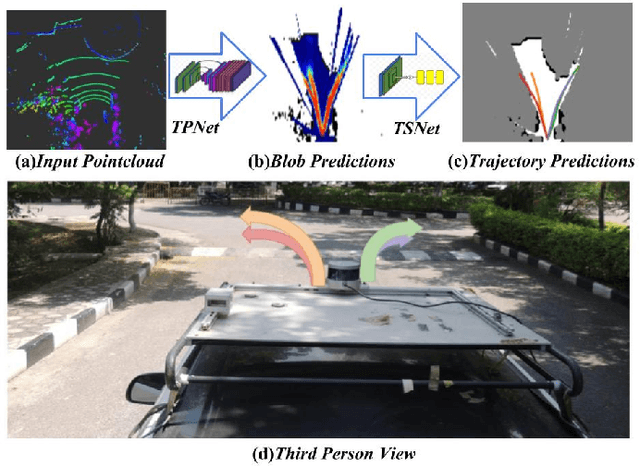
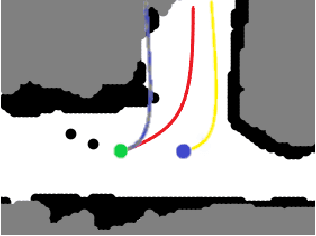
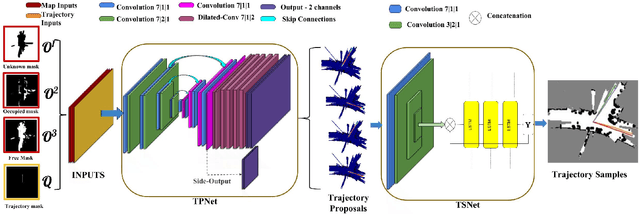

Autonomous explorative robots frequently encounter scenarios where multiple future trajectories can be pursued. Often these are cases with multiple paths around an obstacle or trajectory options towards various frontiers. Humans in such situations can inherently perceive and reason about the surrounding environment to identify several possibilities of either manoeuvring around the obstacles or moving towards various frontiers. In this work, we propose a 2 stage Convolutional Neural Network architecture which mimics such an ability to map the perceived surroundings to multiple trajectories that a robot can choose to traverse. The first stage is a Trajectory Proposal Network which suggests diverse regions in the environment which can be occupied in the future. The second stage is a Trajectory Sampling network which provides a finegrained trajectory over the regions proposed by Trajectory Proposal Network. We evaluate our framework in diverse and complicated real life settings. For the outdoor case, we use the KITTI dataset and our own outdoor driving dataset. In the indoor setting, we use an autonomous drone to navigate various scenarios and also a ground robot which can explore the environment using the trajectories proposed by our framework. Our experiments suggest that the framework is able to develop a semantic understanding of the obstacles, open regions and identify diverse trajectories that a robot can traverse. Our comparisons portray the performance gain of the proposed architecture over a diverse set of methods against which it is compared.
A Hybrid Approach to Word Sense Disambiguation Combining Supervised and Unsupervised Learning
Nov 19, 2015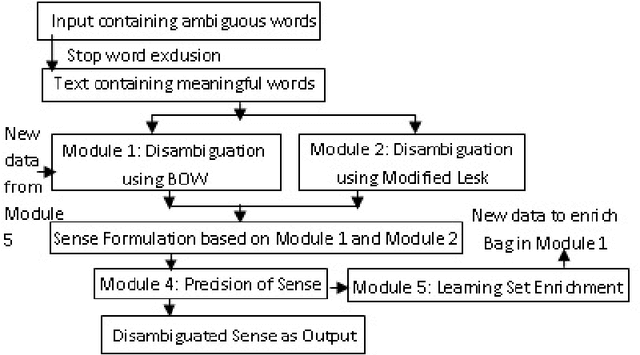
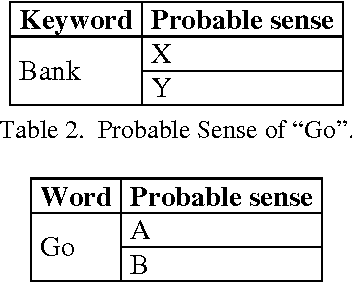
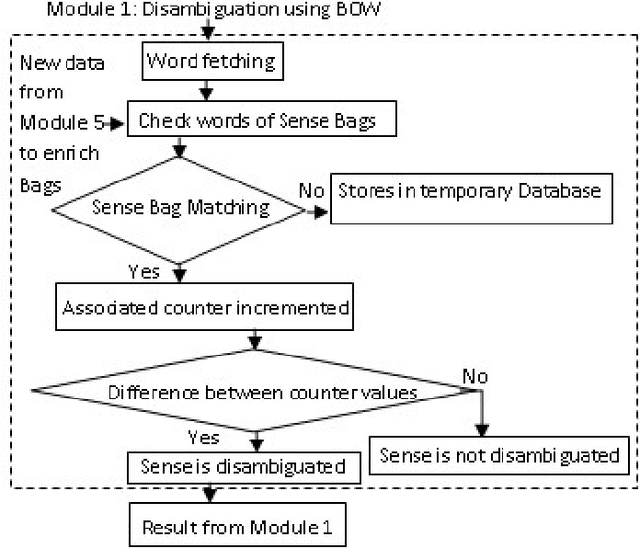
In this paper, we are going to find meaning of words based on distinct situations. Word Sense Disambiguation is used to find meaning of words based on live contexts using supervised and unsupervised approaches. Unsupervised approaches use online dictionary for learning, and supervised approaches use manual learning sets. Hand tagged data are populated which might not be effective and sufficient for learning procedure. This limitation of information is main flaw of the supervised approach. Our proposed approach focuses to overcome the limitation using learning set which is enriched in dynamic way maintaining new data. Trivial filtering method is utilized to achieve appropriate training data. We introduce a mixed methodology having Modified Lesk approach and Bag-of-Words having enriched bags using learning methods. Our approach establishes the superiority over individual Modified Lesk and Bag-of-Words approaches based on experimentation.