 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Slang Words in e-Data using semi-Supervised Learning
Nov 19, 2015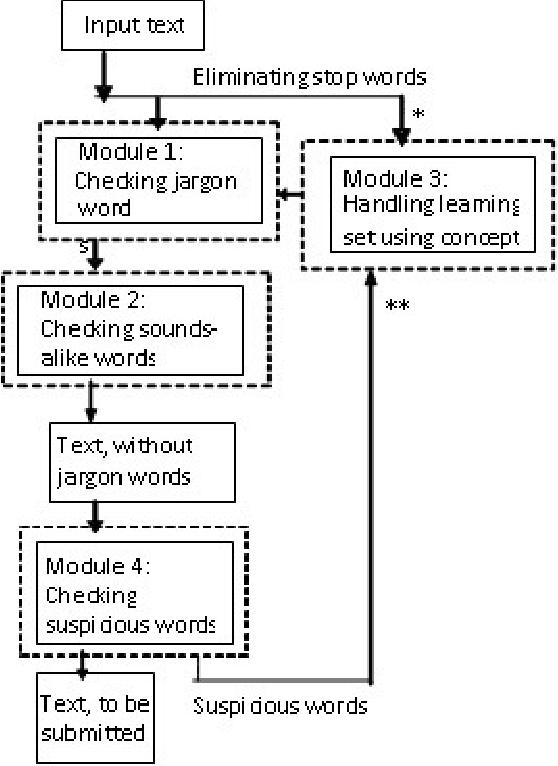
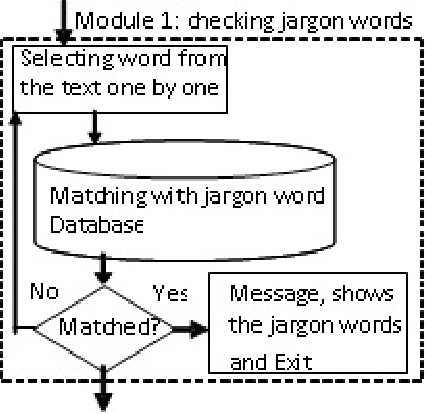
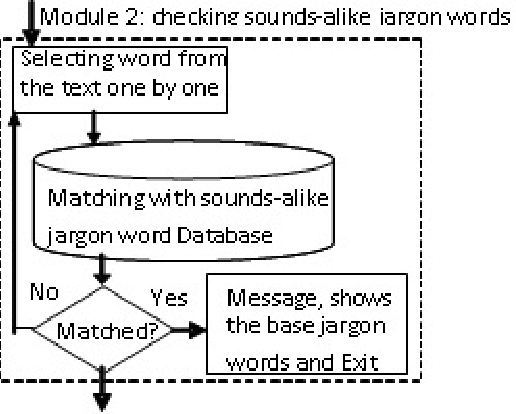
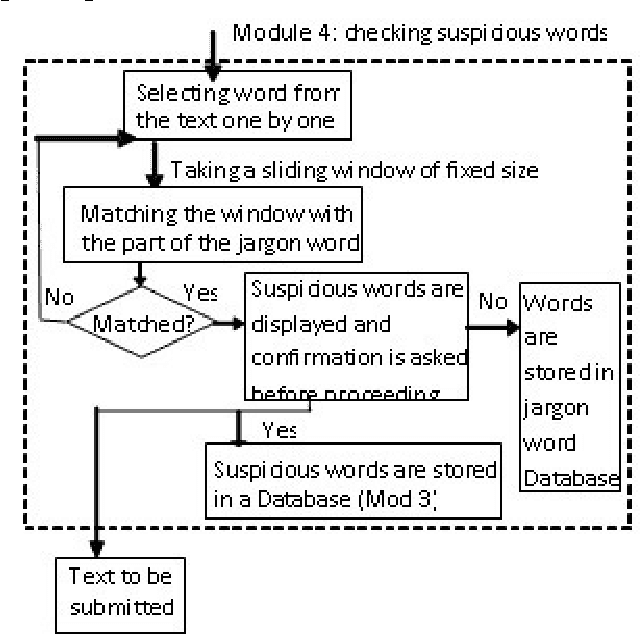
The proposed algorithmic approach deals with finding the sense of a word in an electronic data. Now a day,in different communication mediums like internet, mobile services etc. people use few words, which are slang in nature. This approach detects those abusive words using supervised learning procedure. But in the real life scenario, the slang words are not used in complete word forms always. Most of the times, those words are used in different abbreviated forms like sounds alike forms, taboo morphemes etc. This proposed approach can detect those abbreviated forms also using semi supervised learning procedure. Using the synset and concept analysis of the text, the probability of a suspicious word to be a slang word is also evaluated.
An Approach to Speed-up the Word Sense Disambiguation Procedure through Sense Filtering
Nov 19, 2015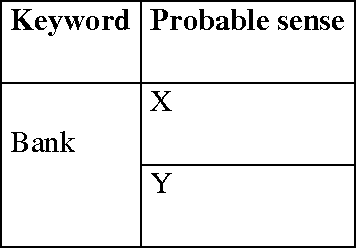
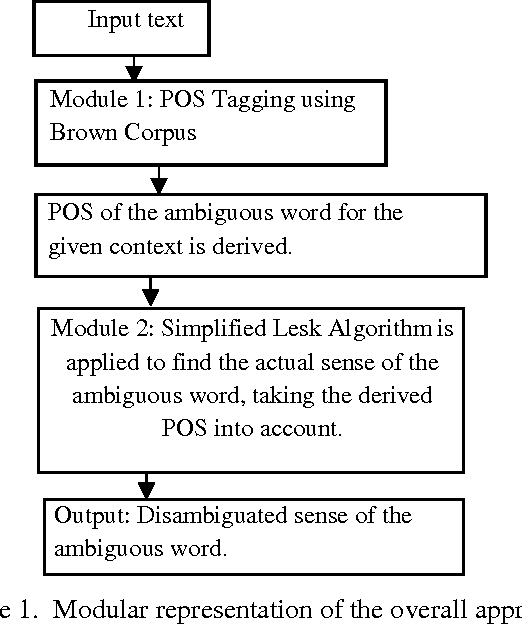
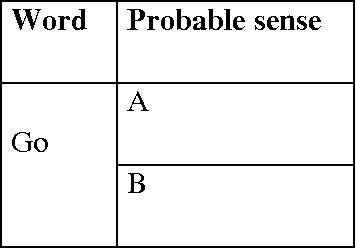
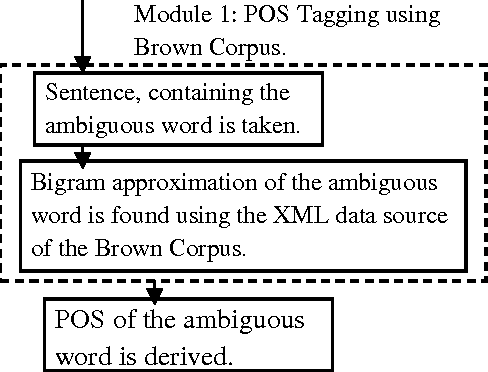
In this paper, we are going to focus on speed up of the Word Sense Disambiguation procedure by filtering the relevant senses of an ambiguous word through Part-of-Speech Tagging. First, this proposed approach performs the Part-of-Speech Tagging operation before the disambiguation procedure using Bigram approximation. As a result, the exact Part-of-Speech of the ambiguous word at a particular text instance is derived. In the next stage, only those dictionary definitions (glosses) are retrieved from an online dictionary, which are associated with that particular Part-of-Speech to disambiguate the exact sense of the ambiguous word. In the training phase, we have used Brown Corpus for Part-of-Speech Tagging and WordNet as an online dictionary. The proposed approach reduces the execution time upto half (approximately) of the normal execution time for a text, containing around 200 sentences. Not only that, we have found several instances, where the correct sense of an ambiguous word is found for using the Part-of-Speech Tagging before the Disambiguation procedure.
A Hybrid Approach to Word Sense Disambiguation Combining Supervised and Unsupervised Learning
Nov 19, 2015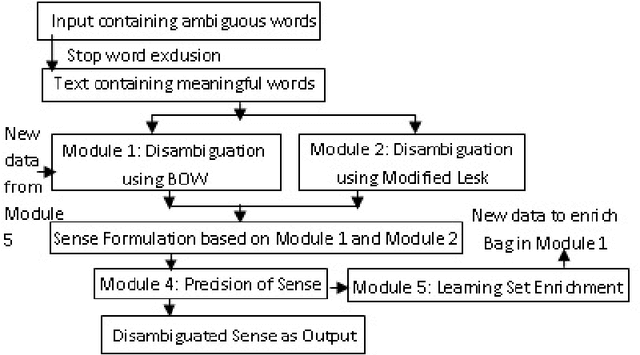
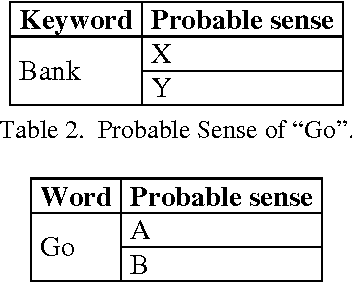
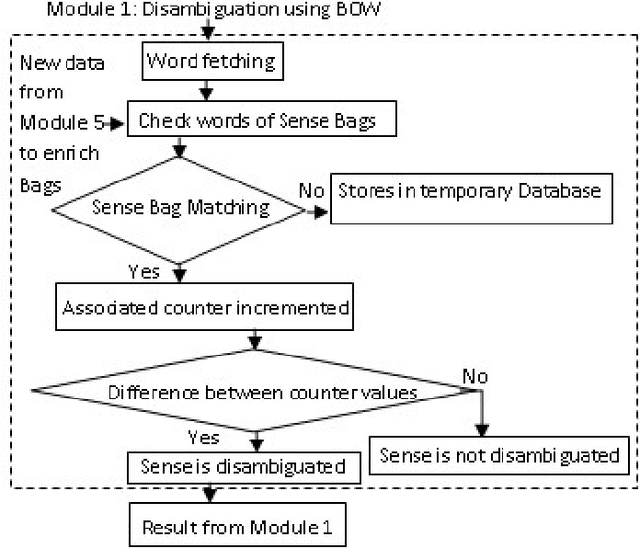
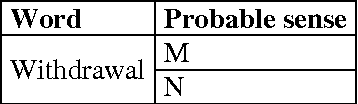
In this paper, we are going to find meaning of words based on distinct situations. Word Sense Disambiguation is used to find meaning of words based on live contexts using supervised and unsupervised approaches. Unsupervised approaches use online dictionary for learning, and supervised approaches use manual learning sets. Hand tagged data are populated which might not be effective and sufficient for learning procedure. This limitation of information is main flaw of the supervised approach. Our proposed approach focuses to overcome the limitation using learning set which is enriched in dynamic way maintaining new data. Trivial filtering method is utilized to achieve appropriate training data. We introduce a mixed methodology having Modified Lesk approach and Bag-of-Words having enriched bags using learning methods. Our approach establishes the superiority over individual Modified Lesk and Bag-of-Words approaches based on experimentation.
Automatic classification of bengali sentences based on sense definitions present in bengali wordnet
Aug 06, 2015
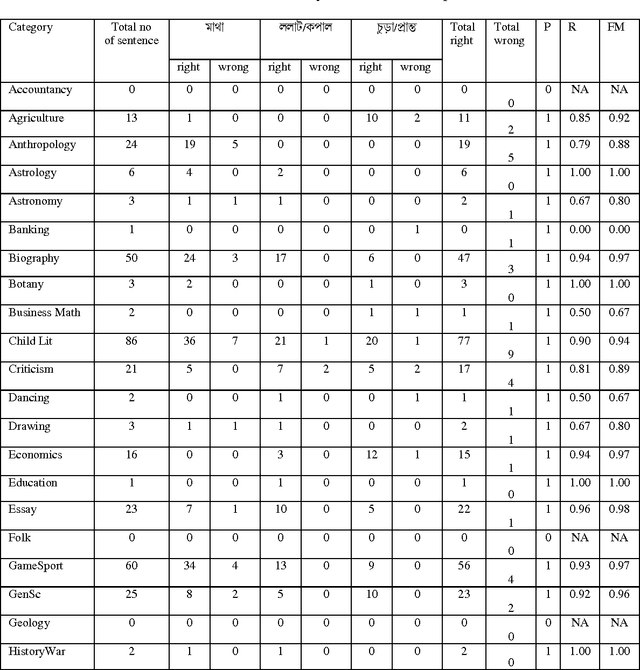

Based on the sense definition of words available in the Bengali WordNet, an attempt is made to classify the Bengali sentences automatically into different groups in accordance with their underlying senses. The input sentences are collected from 50 different categories of the Bengali text corpus developed in the TDIL project of the Govt. of India, while information about the different senses of particular ambiguous lexical item is collected from Bengali WordNet. In an experimental basis we have used Naive Bayes probabilistic model as a useful classifier of sentences. We have applied the algorithm over 1747 sentences that contain a particular Bengali lexical item which, because of its ambiguous nature, is able to trigger different senses that render sentences in different meanings. In our experiment we have achieved around 84% accurate result on the sense classification over the total input sentences. We have analyzed those residual sentences that did not comply with our experiment and did affect the results to note that in many cases, wrong syntactic structures and less semantic information are the main hurdles in semantic classification of sentences. The applicational relevance of this study is attested in automatic text classification, machine learning, information extraction, and word sense disambiguation.
Word sense disambiguation: a survey
Aug 06, 2015

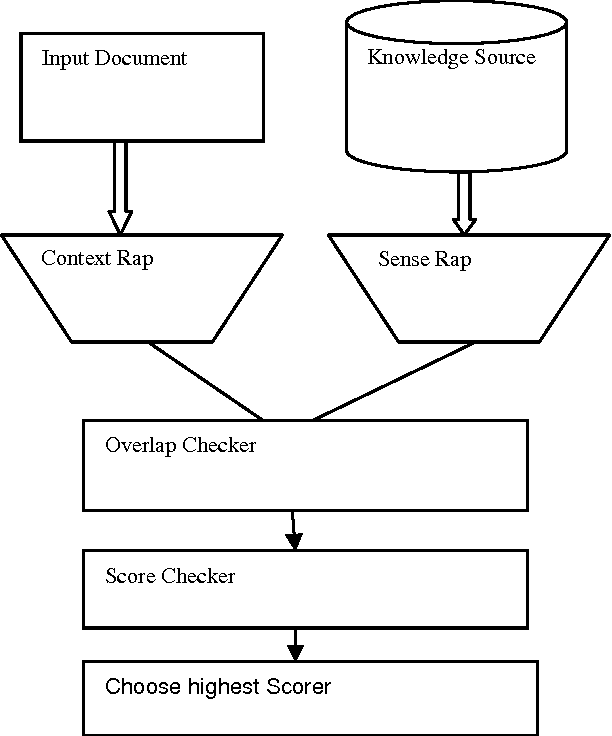
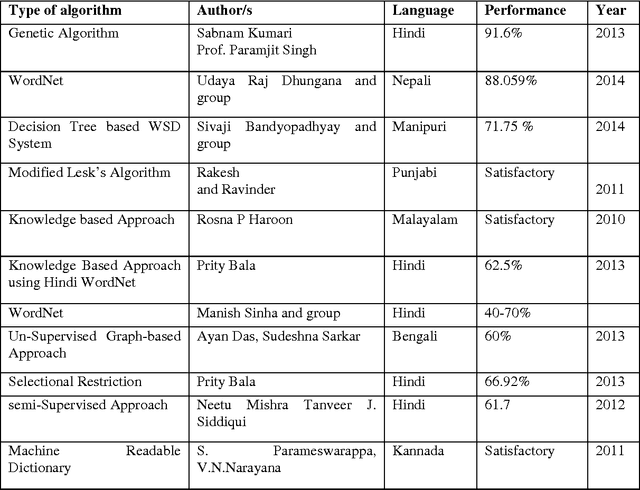
In this paper, we made a survey on Word Sense Disambiguation (WSD). Near about in all major languages around the world, research in WSD has been conducted upto different extents. In this paper, we have gone through a survey regarding the different approaches adopted in different research works, the State of the Art in the performance in this domain, recent works in different Indian languages and finally a survey in Bengali language. We have made a survey on different competitions in this field and the bench mark results, obtained from those competitions.