Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Slang Words in e-Data using semi-Supervised Learning
Paper and Code
Nov 19, 2015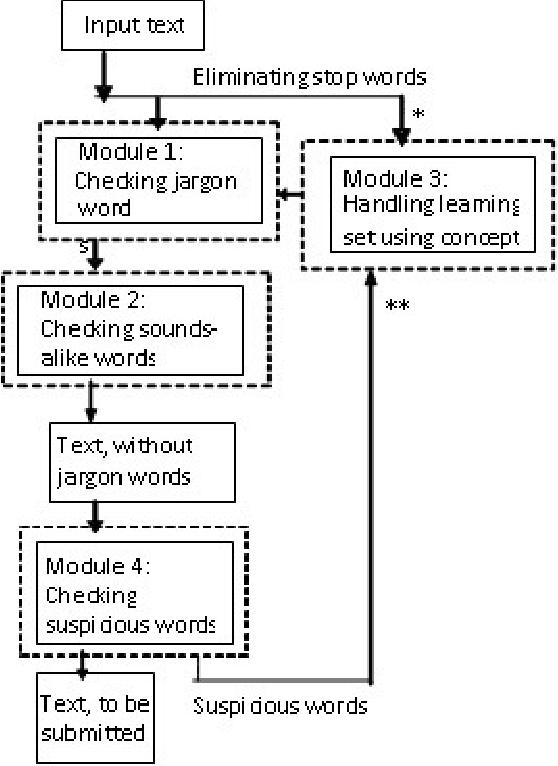
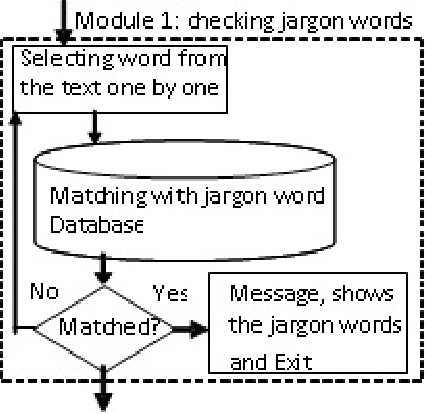
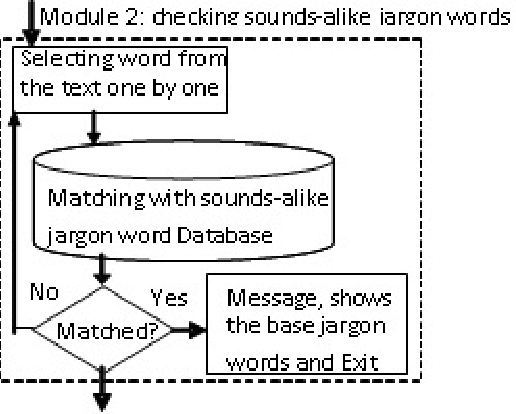
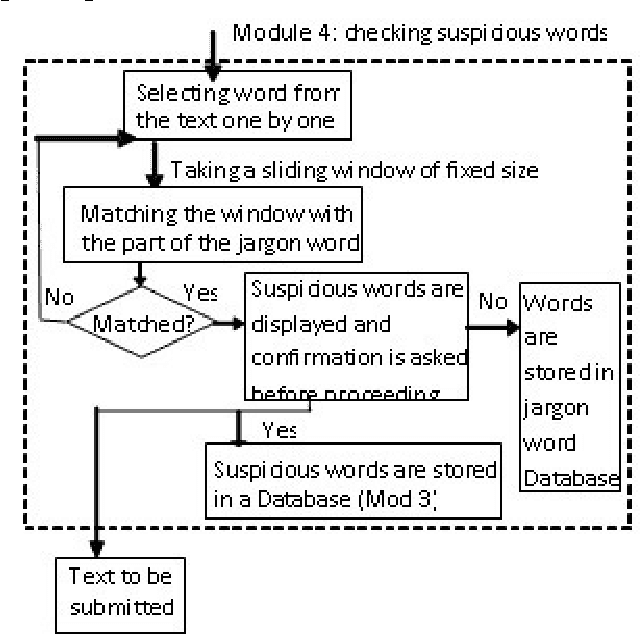
The proposed algorithmic approach deals with finding the sense of a word in an electronic data. Now a day,in different communication mediums like internet, mobile services etc. people use few words, which are slang in nature. This approach detects those abusive words using supervised learning procedure. But in the real life scenario, the slang words are not used in complete word forms always. Most of the times, those words are used in different abbreviated forms like sounds alike forms, taboo morphemes etc. This proposed approach can detect those abbreviated forms also using semi supervised learning procedure. Using the synset and concept analysis of the text, the probability of a suspicious word to be a slang word is also evaluated.
* 13 pages in International Journal of Artificial Intelligence &
Applications (IJAIA), Vol. 4, No. 5, September 2013
View paper on