 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Coding Challenge Competence With APPS
May 27, 2021



While programming is one of the most broadly applicable skills in modern society, modern machine learning models still cannot code solutions to basic problems. Despite its importance, there has been surprisingly little work on evaluating code generation, and it can be difficult to accurately assess code generation performance rigorously. To meet this challenge, we introduce APPS, a benchmark for code generation. Unlike prior work in more restricted settings, our benchmark measures the ability of models to take an arbitrary natural language specification and generate satisfactory Python code. Similar to how companies assess candidate software developers, we then evaluate models by checking their generated code on test cases. Our benchmark includes 10,000 problems, which range from having simple one-line solutions to being substantial algorithmic challenges. We fine-tune large language models on both GitHub and our training set, and we find that the prevalence of syntax errors is decreasing exponentially as models improve. Recent models such as GPT-Neo can pass approximately 20% of the test cases of introductory problems, so we find that machine learning models are now beginning to learn how to code. As the social significance of automatic code generation increases over the coming years, our benchmark can provide an important measure for tracking advancements.
Measuring Mathematical Problem Solving With the MATH Dataset
Mar 05, 2021
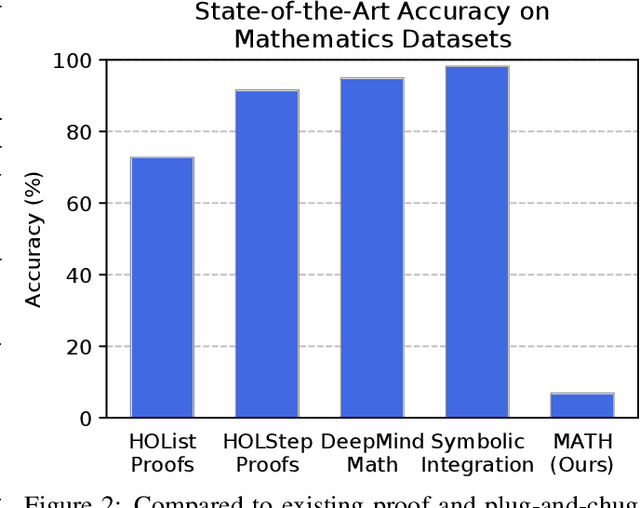
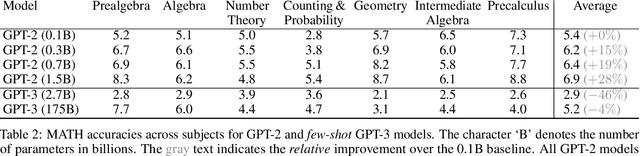
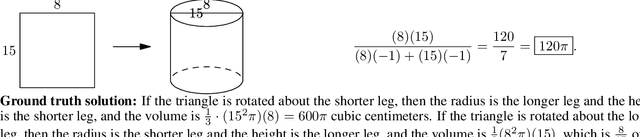
Many intellectual endeavors require mathematical problem solving, but this skill remains beyond the capabilities of computers. To measure this ability in machine learning models, we introduce MATH, a new dataset of 12,500 challenging competition mathematics problems. Each problem in MATH has a full step-by-step solution which can be used to teach models to generate answer derivations and explanations. To facilitate future research and increase accuracy on MATH, we also contribute a large auxiliary pretraining dataset which helps teach models the fundamentals of mathematics. Even though we are able to increase accuracy on MATH, our results show that accuracy remains relatively low, even with enormous Transformer models. Moreover, we find that simply increasing budgets and model parameter counts will be impractical for achieving strong mathematical reasoning if scaling trends continue. While scaling Transformers is automatically solving most other text-based tasks, scaling is not currently solving MATH. To have more traction on mathematical problem solving we will likely need new algorithmic advancements from the broader research community.