 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical and Comparative Analysis of Data Valuation with Scalable Algorithms
Nov 17, 2019

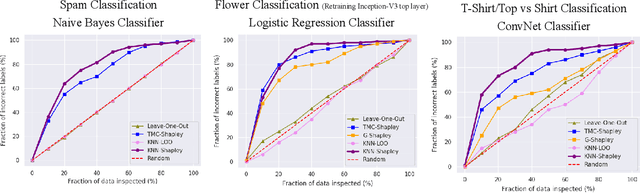

This paper focuses on valuating training data for supervised learning tasks and studies the Shapley value, a data value notion originated in cooperative game theory. The Shapley value defines a unique value distribution scheme that satisfies a set of appealing properties desired by a data value notion. However, the Shapley value requires exponential complexity to calculate exactly. Existing approximation algorithms, although achieving great improvement over the exact algorithm, relies on retraining models for multiple times, thus remaining limited when applied to larger-scale learning tasks and real-world datasets. In this work, we develop a simple and efficient heuristic for data valuation based on the Shapley value with complexity independent with the model size. The key idea is to approximate the model via a $K$-nearest neighbor ($K$NN) classifier, which has a locality structure that can lead to efficient Shapley value calculation. We evaluate the utility of the values produced by the $K$NN proxies in various settings, including label noise correction, watermark detection, data summarization, active data acquisition, and domain adaption. Extensive experiments demonstrate that our algorithm achieves at least comparable utility to the values produced by existing algorithms while significant efficiency improvement. Moreover, we theoretically analyze the Shapley value and justify its advantage over the leave-one-out error as a data value measure.
Image Based Review Text Generation with Emotional Guidance
Jan 14, 2019
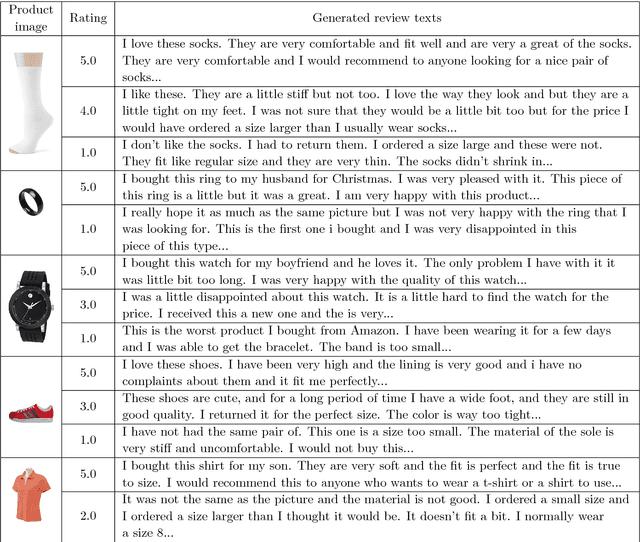
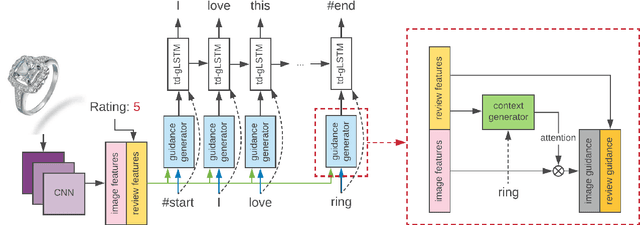
In the current field of computer vision, automatically generating texts from given images has been a fully worked technique. Up till now, most works of this area focus on image content describing, namely image-captioning. However, rare researches focus on generating product review texts, which is ubiquitous in the online shopping malls and is crucial for online shopping selection and evaluation. Different from content describing, review texts include more subjective information of customers, which may bring difference to the results. Therefore, we aimed at a new field concerning generating review text from customers based on images together with the ratings of online shopping products, which appear as non-image attributes. We made several adjustments to the existing image-captioning model to fit our task, in which we should also take non-image features into consideration. We also did experiments based on our model and get effective primary results.