 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3-VAE: Reference Vector-Guided Rating Residual Quantization VAE for Generative Recommendation
Apr 14, 2026Generative Recommendation (GR) has gained traction for its merits of superior performance and cold-start capability. As the vital role in GR, Semantic Identifiers (SIDs) represent item semantics through discrete tokens. However, current techniques for SID generation based on vector quantization face two main challenges: (i) training instability, stemming from insufficient gradient propagation through the straight-through estimator and sensitivity to initialization; and (ii) inefficient SID quality assessment, where industrial practice still depends on costly GR training and A/B testing. To address these challenges, we propose Reference Vector-Guided Rating Residual Quantization VAE (R3-VAE). This framework incorporates three key innovations: (i) a reference vector that functions as a semantic anchor for the initial features, thereby mitigating sensitivity to initialization; (ii) a dot product-based rating mechanism designed to stabilize the training process and prevent codebook collapse; and (iii) two SID evaluation metrics, Semantic Cohesion and Preference Discrimination, serving as regularization terms during training. Empirical results on six benchmarks demonstrate that R3-VAE outperforms state-of-the-art methods, achieving an average improvement of 14.2% in Recall@10 and 15.5% in NDCG@10 across three Amazon datasets. Furthermore, we perform GR training and online A/B tests on Toutiao. Our method achieves a 1.62% improvement in MRR and a 0.83% gain in StayTime/U versus baselines. Additionally, we employ R3-VAE to replace the item ID of CTR model, resulting in significant improvements in content cold start by 15.36%, corroborating the strong applicability and business value in industry-scale recommendation scenarios.
VersaPRM: Multi-Domain Process Reward Model via Synthetic Reasoning Data
Feb 10, 2025



Process Reward Models (PRMs) have proven effective at enhancing mathematical reasoning for Large Language Models (LLMs) by leveraging increased inference-time computation. However, they are predominantly trained on mathematical data and their generalizability to non-mathematical domains has not been rigorously studied. In response, this work first shows that current PRMs have poor performance in other domains. To address this limitation, we introduce VersaPRM, a multi-domain PRM trained on synthetic reasoning data generated using our novel data generation and annotation method. VersaPRM achieves consistent performance gains across diverse domains. For instance, in the MMLU-Pro category of Law, VersaPRM via weighted majority voting, achieves a 7.9% performance gain over the majority voting baseline -- surpassing Qwen2.5-Math-PRM's gain of 1.3%. We further contribute to the community by open-sourcing all data, code and models for VersaPRM.
How to Solve Contextual Goal-Oriented Problems with Offline Datasets?
Aug 14, 2024



We present a novel method, Contextual goal-Oriented Data Augmentation (CODA), which uses commonly available unlabeled trajectories and context-goal pairs to solve Contextual Goal-Oriented (CGO) problems. By carefully constructing an action-augmented MDP that is equivalent to the original MDP, CODA creates a fully labeled transition dataset under training contexts without additional approximation error. We conduct a novel theoretical analysis to demonstrate CODA's capability to solve CGO problems in the offline data setup. Empirical results also showcase the effectiveness of CODA, which outperforms other baseline methods across various context-goal relationships of CGO problem. This approach offers a promising direction to solving CGO problems using offline datasets.
DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models
May 25, 2023



Learning from human feedback has been shown to improve text-to-image models. These techniques first learn a reward function that captures what humans care about in the task and then improve the models based on the learned reward function. Even though relatively simple approaches (e.g., rejection sampling based on reward scores) have been investigated, fine-tuning text-to-image models with the reward function remains challenging. In this work, we propose using online reinforcement learning (RL) to fine-tune text-to-image models. We focus on diffusion models, defining the fine-tuning task as an RL problem, and updating the pre-trained text-to-image diffusion models using policy gradient to maximize the feedback-trained reward. Our approach, coined DPOK, integrates policy optimization with KL regularization. We conduct an analysis of KL regularization for both RL fine-tuning and supervised fine-tuning. In our experiments, we show that DPOK is generally superior to supervised fine-tuning with respect to both image-text alignment and image quality.
Domain Generalization via Nuclear Norm Regularization
Mar 13, 2023



The ability to generalize to unseen domains is crucial for machine learning systems deployed in the real world, especially when we only have data from limited training domains. In this paper, we propose a simple and effective regularization method based on the nuclear norm of the learned features for domain generalization. Intuitively, the proposed regularizer mitigates the impacts of environmental features and encourages learning domain-invariant features. Theoretically, we provide insights into why nuclear norm regularization is more effective compared to ERM and alternative regularization methods. Empirically, we conduct extensive experiments on both synthetic and real datasets. We show that nuclear norm regularization achieves strong performance compared to baselines in a wide range of domain generalization tasks. Moreover, our regularizer is broadly applicable with various methods such as ERM and SWAD with consistently improved performance, e.g., 1.7% and 0.9% test accuracy improvements respectively on the DomainBed benchmark.
Optimizing DDPM Sampling with Shortcut Fine-Tuning
Feb 01, 2023



In this study, we propose Shortcut Fine-Tuning (SFT), a new approach for addressing the challenge of fast sampling of pretrained Denoising Diffusion Probabilistic Models (DDPMs). SFT advocates for the fine-tuning of DDPM samplers through the direct minimization of Integral Probability Metrics (IPM), instead of learning the backward diffusion process. This enables samplers to discover an alternative and more efficient sampling shortcut, deviating from the backward diffusion process. We also propose a new algorithm that is similar to the policy gradient method for fine-tuning DDPMs by proving that under certain assumptions, the gradient descent of diffusion models is equivalent to the policy gradient approach. Through empirical evaluation, we demonstrate that our fine-tuning method can further enhance existing fast DDPM samplers, resulting in sample quality comparable to or even surpassing that of the full-step model across various datasets.
Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance
Dec 13, 2022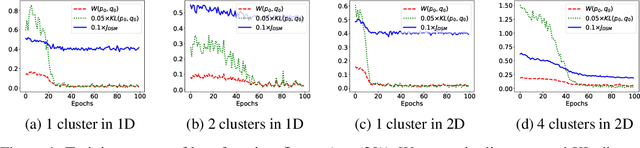
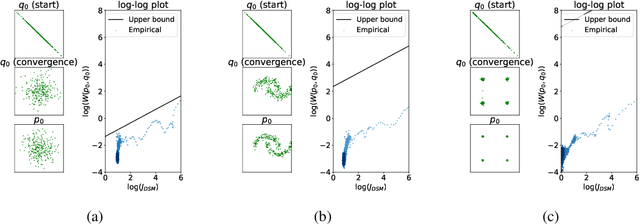
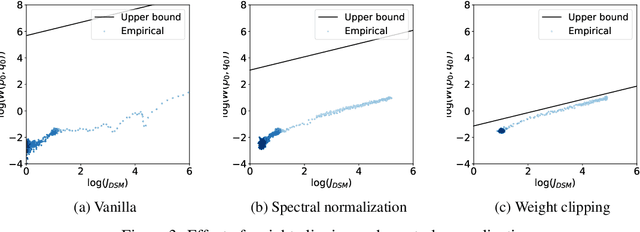
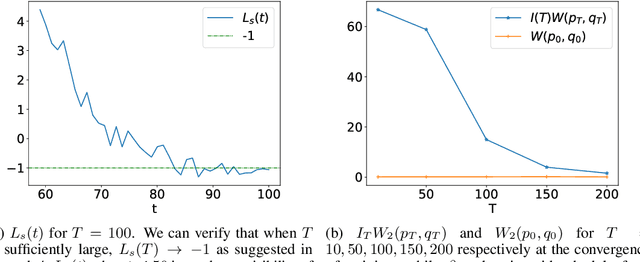
Score-based generative models are shown to achieve remarkable empirical performances in various applications such as image generation and audio synthesis. However, a theoretical understanding of score-based diffusion models is still incomplete. Recently, Song et al. showed that the training objective of score-based generative models is equivalent to minimizing the Kullback-Leibler divergence of the generated distribution from the data distribution. In this work, we show that score-based models also minimize the Wasserstein distance between them under suitable assumptions on the model. Specifically, we prove that the Wasserstein distance is upper bounded by the square root of the objective function up to multiplicative constants and a fixed constant offset. Our proof is based on a novel application of the theory of optimal transport, which can be of independent interest to the society. Our numerical experiments support our findings. By analyzing our upper bounds, we provide a few techniques to obtain tighter upper bounds.
POEM: Out-of-Distribution Detection with Posterior Sampling
Jun 28, 2022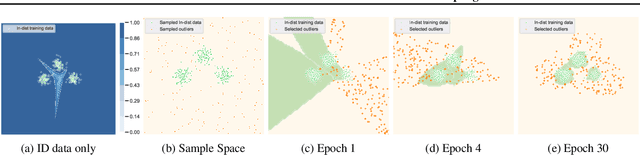
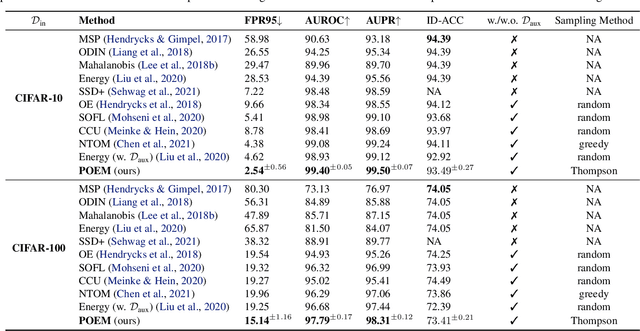
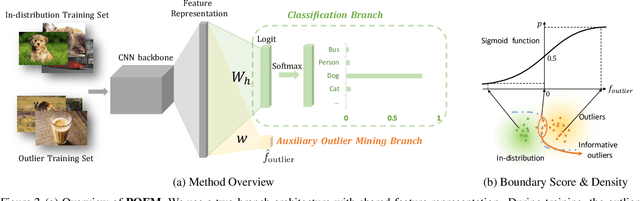

Out-of-distribution (OOD) detection is indispensable for machine learning models deployed in the open world. Recently, the use of an auxiliary outlier dataset during training (also known as outlier exposure) has shown promising performance. As the sample space for potential OOD data can be prohibitively large, sampling informative outliers is essential. In this work, we propose a novel posterior sampling-based outlier mining framework, POEM, which facilitates efficient use of outlier data and promotes learning a compact decision boundary between ID and OOD data for improved detection. We show that POEM establishes state-of-the-art performance on common benchmarks. Compared to the current best method that uses a greedy sampling strategy, POEM improves the relative performance by 42.0% and 24.2% (FPR95) on CIFAR-10 and CIFAR-100, respectively. We further provide theoretical insights on the effectiveness of POEM for OOD detection.
* ICML 2022 (Long Talk); First two authors contributed equally
Real Negatives Matter: Continuous Training with Real Negatives for Delayed Feedback Modeling
Apr 29, 2021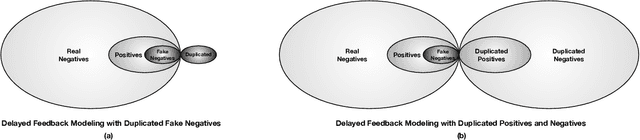

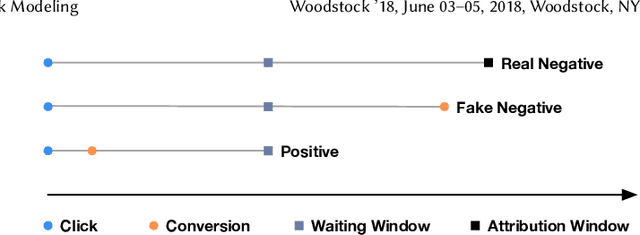
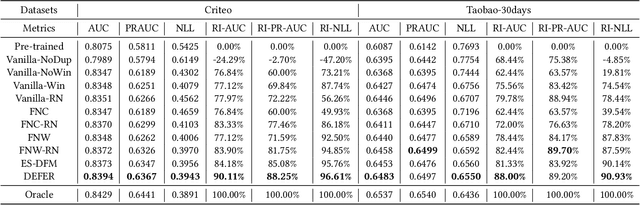
One of the difficulties of conversion rate (CVR) prediction is that the conversions can delay and take place long after the clicks. The delayed feedback poses a challenge: fresh data are beneficial to continuous training but may not have complete label information at the time they are ingested into the training pipeline. To balance model freshness and label certainty, previous methods set a short waiting window or even do not wait for the conversion signal. If conversion happens outside the waiting window, this sample will be duplicated and ingested into the training pipeline with a positive label. However, these methods have some issues. First, they assume the observed feature distribution remains the same as the actual distribution. But this assumption does not hold due to the ingestion of duplicated samples. Second, the certainty of the conversion action only comes from the positives. But the positives are scarce as conversions are sparse in commercial systems. These issues induce bias during the modeling of delayed feedback. In this paper, we propose DElayed FEedback modeling with Real negatives (DEFER) method to address these issues. The proposed method ingests real negative samples into the training pipeline. The ingestion of real negatives ensures the observed feature distribution is equivalent to the actual distribution, thus reducing the bias. The ingestion of real negatives also brings more certainty information of the conversion. To correct the distribution shift, DEFER employs importance sampling to weigh the loss function. Experimental results on industrial datasets validate the superiority of DEFER. DEFER have been deployed in the display advertising system of Alibaba, obtaining over 6.0% improvement on CVR in several scenarios. The code and data in this paper are now open-sourced {https://github.com/gusuperstar/defer.git}.
Efficient Exploration for Model-based Reinforcement Learning with Continuous States and Actions
Nov 20, 2020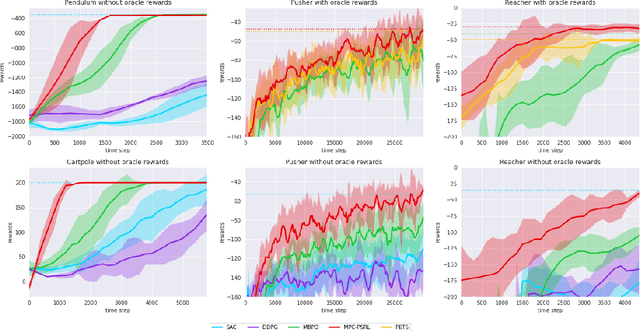
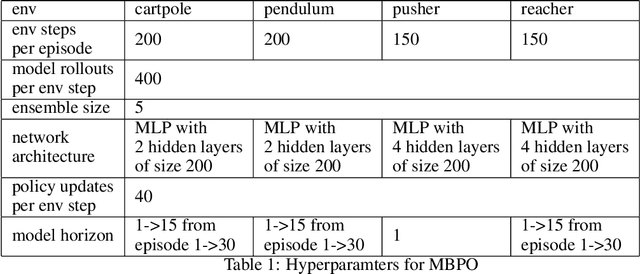
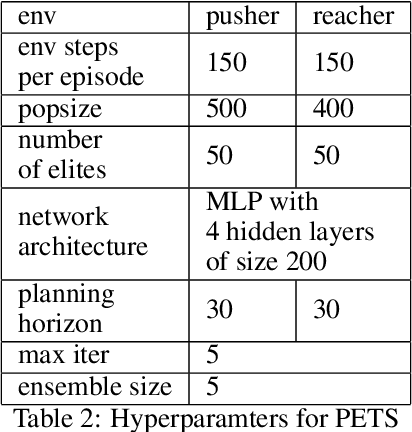
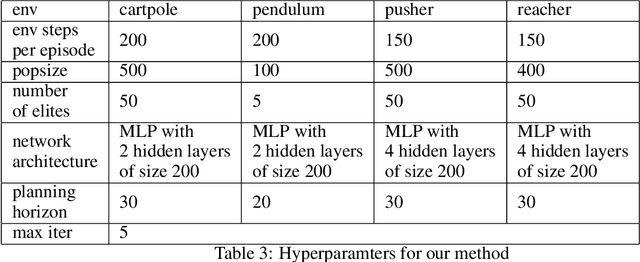
Balancing exploration and exploitation is crucial in reinforcement learning (RL). In this paper, we study the model-based posterior sampling algorithm in continuous state-action spaces theoretically and empirically. First, we improve the regret bound: with the assumption that reward and transition functions can be modeled as Gaussian Processes with linear kernels, we develop a Bayesian regret bound of $\tilde{O}(H^{3/2}d\sqrt{T})$, where $H$ is the episode length, $d$ is the dimension of the state-action space, and $T$ indicates the total time steps. Our bound can be extended to nonlinear cases as well: using linear kernels on the feature representation $\phi$, the Bayesian regret bound becomes $\tilde{O}(H^{3/2}d_{\phi}\sqrt{T})$, where $d_\phi$ is the dimension of the representation space. Moreover, we present MPC-PSRL, a model-based posterior sampling algorithm with model predictive control for action selection. To capture the uncertainty in models and realize posterior sampling, we use Bayesian linear regression on the penultimate layer (the feature representation layer $\phi$) of neural networks. Empirical results show that our algorithm achieves the best sample efficiency in benchmark control tasks compared to prior model-based algorithms, and matches the asymptotic performance of model-free algorithms.