 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Ranking Consistency of Pre-ranking Stage
May 11, 2022


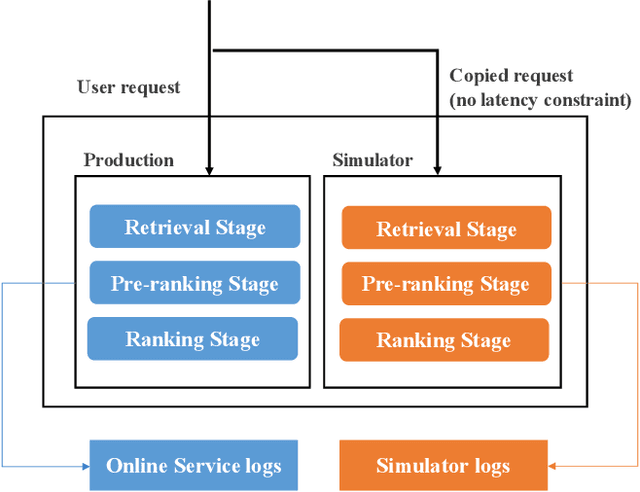
Industrial ranking systems, such as advertising systems, rank items by aggregating multiple objectives into one final objective to satisfy user demand and commercial intent. Cascade architecture, composed of retrieval, pre-ranking, and ranking stages, is usually adopted to reduce the computational cost. Each stage may employ various models for different objectives and calculate the final objective by aggregating these models' outputs. The multi-stage ranking strategy causes a new problem - the ranked lists of the ranking stage and previous stages may be inconsistent. For example, items that should be ranked at the top of the ranking stage may be ranked at the bottom of previous stages. In this paper, we focus on the ranking consistency between the pre-ranking and ranking stages. Specifically, we formally define the problem of ranking consistency and propose the Ranking Consistency Score (RCS) metric for evaluation. We demonstrate that ranking consistency has a direct impact on online performance. Compared with the traditional evaluation manner that mainly focuses on the individual ranking quality of every objective, RCS considers the ranking consistency of the fused final objective, which is more proper for evaluation. Finally, to improve the ranking consistency, we propose several methods from the perspective of sample selection and learning algorithms. Experimental results on industrial datasets validate the efficacy of the proposed metrics and methods. increase on RPM (Revenue Per Mille).
Real Negatives Matter: Continuous Training with Real Negatives for Delayed Feedback Modeling
Apr 29, 2021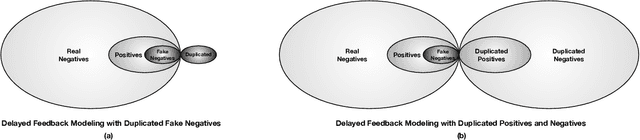

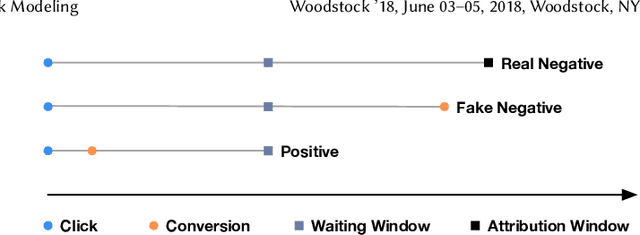
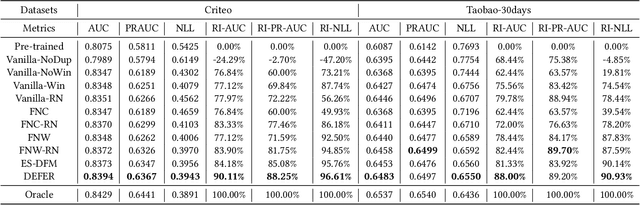
One of the difficulties of conversion rate (CVR) prediction is that the conversions can delay and take place long after the clicks. The delayed feedback poses a challenge: fresh data are beneficial to continuous training but may not have complete label information at the time they are ingested into the training pipeline. To balance model freshness and label certainty, previous methods set a short waiting window or even do not wait for the conversion signal. If conversion happens outside the waiting window, this sample will be duplicated and ingested into the training pipeline with a positive label. However, these methods have some issues. First, they assume the observed feature distribution remains the same as the actual distribution. But this assumption does not hold due to the ingestion of duplicated samples. Second, the certainty of the conversion action only comes from the positives. But the positives are scarce as conversions are sparse in commercial systems. These issues induce bias during the modeling of delayed feedback. In this paper, we propose DElayed FEedback modeling with Real negatives (DEFER) method to address these issues. The proposed method ingests real negative samples into the training pipeline. The ingestion of real negatives ensures the observed feature distribution is equivalent to the actual distribution, thus reducing the bias. The ingestion of real negatives also brings more certainty information of the conversion. To correct the distribution shift, DEFER employs importance sampling to weigh the loss function. Experimental results on industrial datasets validate the superiority of DEFER. DEFER have been deployed in the display advertising system of Alibaba, obtaining over 6.0% improvement on CVR in several scenarios. The code and data in this paper are now open-sourced {https://github.com/gusuperstar/defer.git}.