 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomCAM: Advancing Beyond Saliency Maps through Decomposition and Integration
May 29, 2024Interpreting complex deep networks, notably pre-trained vision-language models (VLMs), is a formidable challenge. Current Class Activation Map (CAM) methods highlight regions revealing the model's decision-making basis but lack clear saliency maps and detailed interpretability. To bridge this gap, we propose DecomCAM, a novel decomposition-and-integration method that distills shared patterns from channel activation maps. Utilizing singular value decomposition, DecomCAM decomposes class-discriminative activation maps into orthogonal sub-saliency maps (OSSMs), which are then integrated together based on their contribution to the target concept. Extensive experiments on six benchmarks reveal that DecomCAM not only excels in locating accuracy but also achieves an optimizing balance between interpretability and computational efficiency. Further analysis unveils that OSSMs correlate with discernible object components, facilitating a granular understanding of the model's reasoning. This positions DecomCAM as a potential tool for fine-grained interpretation of advanced deep learning models. The code is avaible at https://github.com/CapricornGuang/DecomCAM.
Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models
May 08, 2024



Predicting the future trajectories of dynamic traffic actors is a cornerstone task in autonomous driving. Though existing notable efforts have resulted in impressive performance improvements, a gap persists in scene cognitive and understanding of the complex traffic semantics. This paper proposes Traj-LLM, the first to investigate the potential of using Large Language Models (LLMs) without explicit prompt engineering to generate future motion from agents' past/observed trajectories and scene semantics. Traj-LLM starts with sparse context joint coding to dissect the agent and scene features into a form that LLMs understand. On this basis, we innovatively explore LLMs' powerful comprehension abilities to capture a spectrum of high-level scene knowledge and interactive information. Emulating the human-like lane focus cognitive function and enhancing Traj-LLM's scene comprehension, we introduce lane-aware probabilistic learning powered by the pioneering Mamba module. Finally, a multi-modal Laplace decoder is designed to achieve scene-compliant multi-modal predictions. Extensive experiments manifest that Traj-LLM, fortified by LLMs' strong prior knowledge and understanding prowess, together with lane-aware probability learning, outstrips state-of-the-art methods across evaluation metrics. Moreover, the few-shot analysis further substantiates Traj-LLM's performance, wherein with just 50% of the dataset, it outperforms the majority of benchmarks relying on complete data utilization. This study explores equipping the trajectory prediction task with advanced capabilities inherent in LLMs, furnishing a more universal and adaptable solution for forecasting agent motion in a new way.
A Waveform Representation Framework for High-quality Statistical Parametric Speech Synthesis
Oct 06, 2015
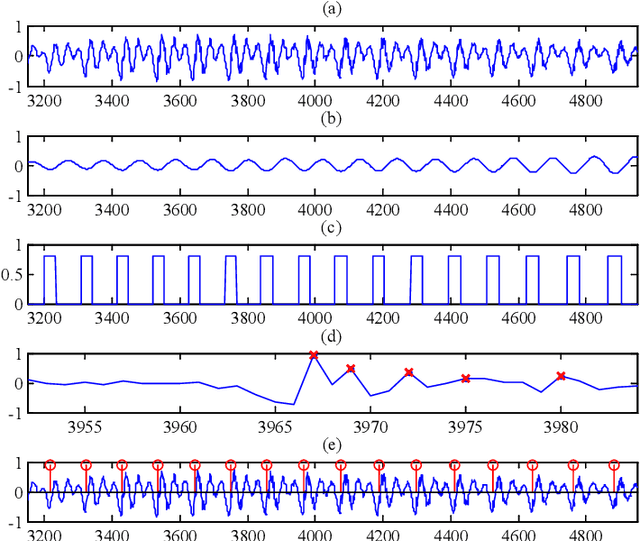
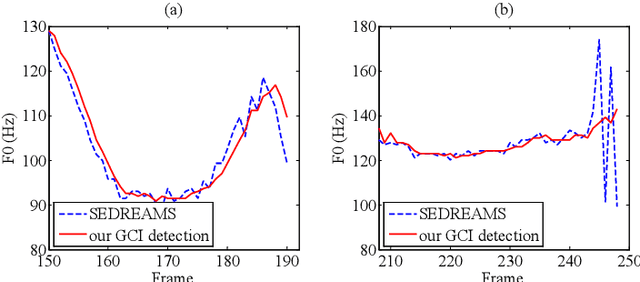
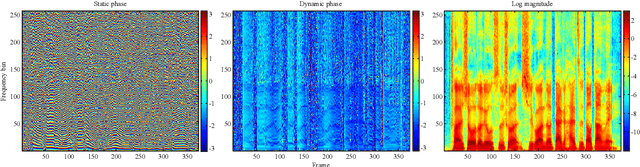
State-of-the-art statistical parametric speech synthesis (SPSS) generally uses a vocoder to represent speech signals and parameterize them into features for subsequent modeling. Magnitude spectrum has been a dominant feature over the years. Although perceptual studies have shown that phase spectrum is essential to the quality of synthesized speech, it is often ignored by using a minimum phase filter during synthesis and the speech quality suffers. To bypass this bottleneck in vocoded speech, this paper proposes a phase-embedded waveform representation framework and establishes a magnitude-phase joint modeling platform for high-quality SPSS. Our experiments on waveform reconstruction show that the performance is better than that of the widely-used STRAIGHT. Furthermore, the proposed modeling and synthesis platform outperforms a leading-edge, vocoded, deep bidirectional long short-term memory recurrent neural network (DBLSTM-RNN)-based baseline system in various objective evaluation metrics conducted.