 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Waveform Representation Framework for High-quality Statistical Parametric Speech Synthesis
Oct 06, 2015
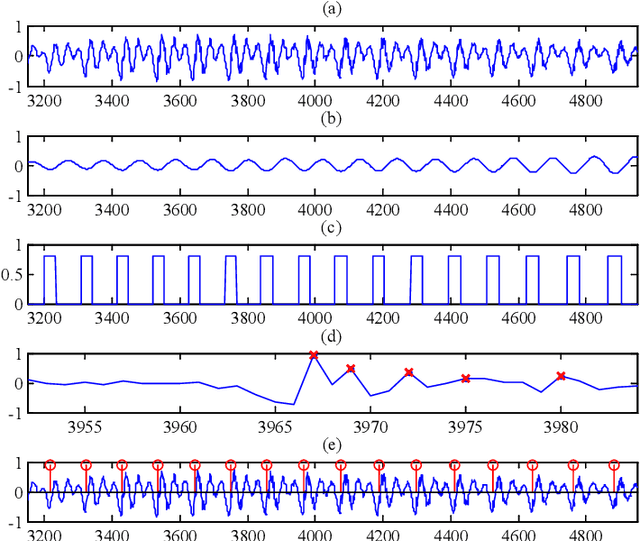
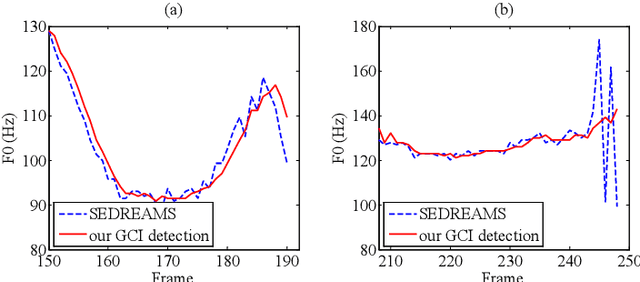
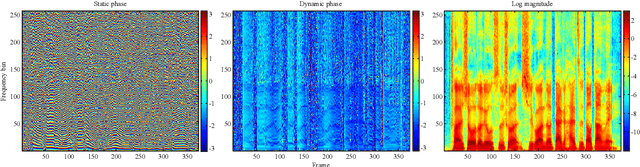
State-of-the-art statistical parametric speech synthesis (SPSS) generally uses a vocoder to represent speech signals and parameterize them into features for subsequent modeling. Magnitude spectrum has been a dominant feature over the years. Although perceptual studies have shown that phase spectrum is essential to the quality of synthesized speech, it is often ignored by using a minimum phase filter during synthesis and the speech quality suffers. To bypass this bottleneck in vocoded speech, this paper proposes a phase-embedded waveform representation framework and establishes a magnitude-phase joint modeling platform for high-quality SPSS. Our experiments on waveform reconstruction show that the performance is better than that of the widely-used STRAIGHT. Furthermore, the proposed modeling and synthesis platform outperforms a leading-edge, vocoded, deep bidirectional long short-term memory recurrent neural network (DBLSTM-RNN)-based baseline system in various objective evaluation metrics conducted.