 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging neuroscience and AI: adaptive, culturally sensitive technologies transforming aphasia rehabilitation
Mar 22, 2026Aphasia, a language impairment primarily resulting from stroke or brain injury, profoundly disrupts communication and everyday functioning. Despite advances in speech therapy, barriers such as limited therapist availability and the scarcity of personalized, culturally relevant tools continue to hinder optimal rehabilitation outcomes. This paper reviews recent developments in neurocognitive research and language technologies that contribute to the diagnosis and therapy of aphasia. Drawing on findings from our ethnographic field study, we introduce two digital therapy prototypes designed to reflect local linguistic diversity and enhance patient engagement. We also show how insights from neuroscience and the local context guided the design of these tools to better meet patient and therapist needs. Our work highlights the potential of adaptive, AI-enhanced assistive technologies to complement conventional therapy and broaden access to therapy. We conclude by outlining future research directions for advancing personalized and scalable aphasia rehabilitation.
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge: Tasks, Results and Findings
Oct 31, 2024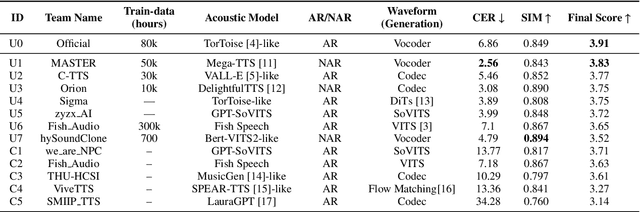
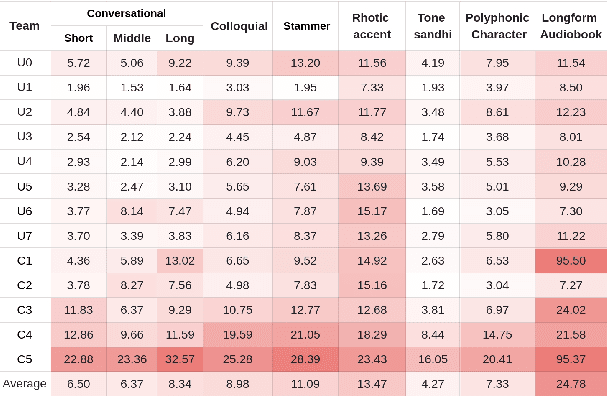
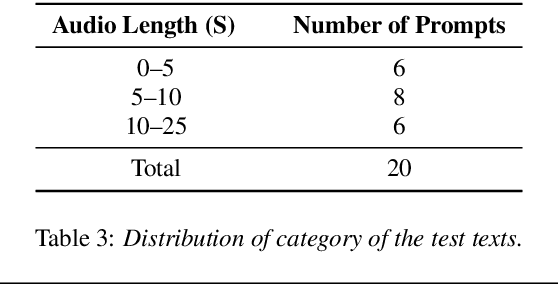
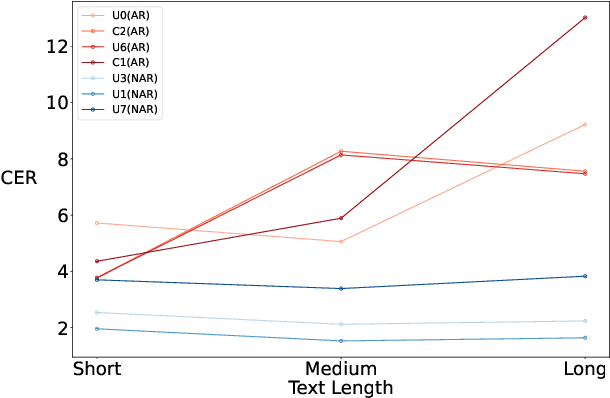
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge aims to benchmark and advance zero-shot spontaneous style voice cloning, particularly focusing on generating spontaneous behaviors in conversational speech. The challenge comprises two tracks: an unconstrained track without limitation on data and model usage, and a constrained track only allowing the use of constrained open-source datasets. A 100-hour high-quality conversational speech dataset is also made available with the challenge. This paper details the data, tracks, submitted systems, evaluation results, and findings.
Towards Good Practices for Video Object Segmentation
Sep 30, 2019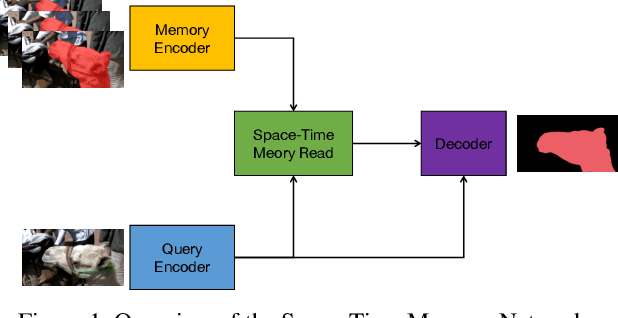

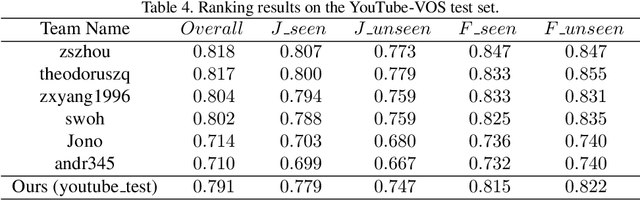
Semi-supervised video object segmentation is an interesting yet challenging task in machine learning. In this work, we conduct a series of refinements with the propagation-based video object segmentation method and empirically evaluate their impact on the final model performance through ablation study. By taking all the refinements, we improve the space-time memory networks to achieve a Overall of 79.1 on the Youtube-VOS Challenge 2019.
Transition-based Parsing with Context Enhancement and Future Reward Reranking
Dec 15, 2016

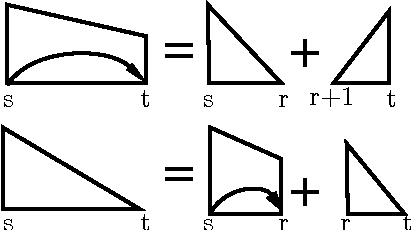

This paper presents a novel reranking model, future reward reranking, to re-score the actions in a transition-based parser by using a global scorer. Different to conventional reranking parsing, the model searches for the best dependency tree in all feasible trees constraining by a sequence of actions to get the future reward of the sequence. The scorer is based on a first-order graph-based parser with bidirectional LSTM, which catches different parsing view compared with the transition-based parser. Besides, since context enhancement has shown substantial improvement in the arc-stand transition-based parsing over the parsing accuracy, we implement context enhancement on an arc-eager transition-base parser with stack LSTMs, the dynamic oracle and dropout supporting and achieve further improvement. With the global scorer and context enhancement, the results show that UAS of the parser increases as much as 1.20% for English and 1.66% for Chinese, and LAS increases as much as 1.32% for English and 1.63% for Chinese. Moreover, we get state-of-the-art LASs, achieving 87.58% for Chinese and 93.37% for English.
A Waveform Representation Framework for High-quality Statistical Parametric Speech Synthesis
Oct 06, 2015
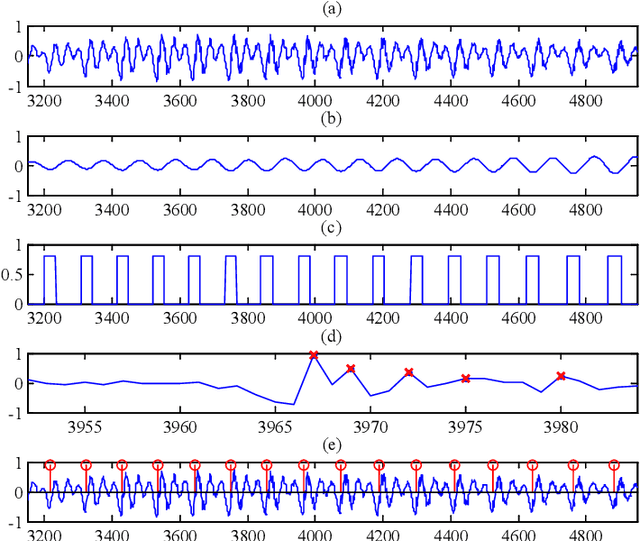
State-of-the-art statistical parametric speech synthesis (SPSS) generally uses a vocoder to represent speech signals and parameterize them into features for subsequent modeling. Magnitude spectrum has been a dominant feature over the years. Although perceptual studies have shown that phase spectrum is essential to the quality of synthesized speech, it is often ignored by using a minimum phase filter during synthesis and the speech quality suffers. To bypass this bottleneck in vocoded speech, this paper proposes a phase-embedded waveform representation framework and establishes a magnitude-phase joint modeling platform for high-quality SPSS. Our experiments on waveform reconstruction show that the performance is better than that of the widely-used STRAIGHT. Furthermore, the proposed modeling and synthesis platform outperforms a leading-edge, vocoded, deep bidirectional long short-term memory recurrent neural network (DBLSTM-RNN)-based baseline system in various objective evaluation metrics conducted.