 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecipitation Nowcasting Using Diffusion Transformer with Causal Attention
Oct 17, 2024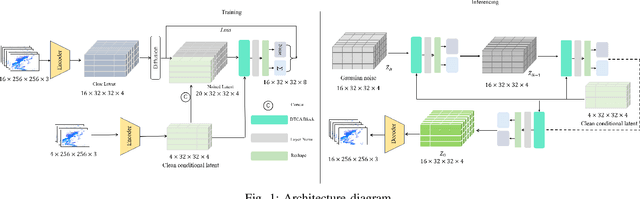
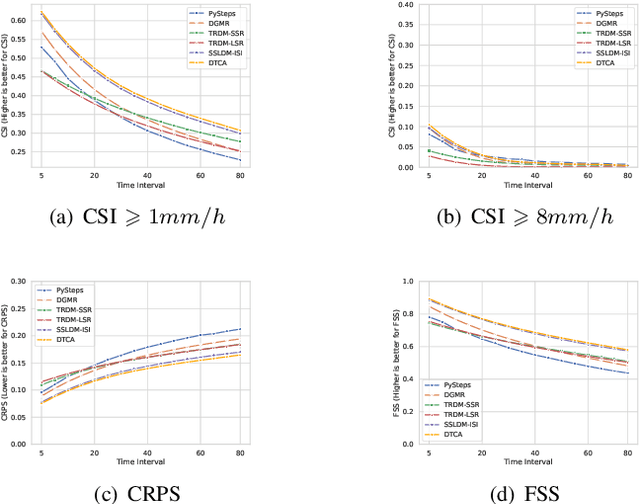
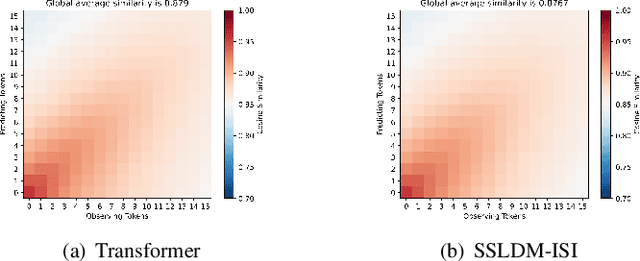

Short-term precipitation forecasting remains challenging due to the difficulty in capturing long-term spatiotemporal dependencies. Current deep learning methods fall short in establishing effective dependencies between conditions and forecast results, while also lacking interpretability. To address this issue, we propose a Precipitation Nowcasting Using Diffusion Transformer with Causal Attention model. Our model leverages Transformer and combines causal attention mechanisms to establish spatiotemporal queries between conditional information (causes) and forecast results (results). This design enables the model to effectively capture long-term dependencies, allowing forecast results to maintain strong causal relationships with input conditions over a wide range of time and space. We explore four variants of spatiotemporal information interactions for DTCA, demonstrating that global spatiotemporal labeling interactions yield the best performance. In addition, we introduce a Channel-To-Batch shift operation to further enhance the model's ability to represent complex rainfall dynamics. We conducted experiments on two datasets. Compared to state-of-the-art U-Net-based methods, our approach improved the CSI (Critical Success Index) for predicting heavy precipitation by approximately 15% and 8% respectively, achieving state-of-the-art performance.
SRNDiff: Short-term Rainfall Nowcasting with Condition Diffusion Model
Feb 21, 2024Diffusion models are widely used in image generation because they can generate high-quality and realistic samples. This is in contrast to generative adversarial networks (GANs) and variational autoencoders (VAEs), which have some limitations in terms of image quality.We introduce the diffusion model to the precipitation forecasting task and propose a short-term precipitation nowcasting with condition diffusion model based on historical observational data, which is referred to as SRNDiff. By incorporating an additional conditional decoder module in the denoising process, SRNDiff achieves end-to-end conditional rainfall prediction. SRNDiff is composed of two networks: a denoising network and a conditional Encoder network. The conditional network is composed of multiple independent UNet networks. These networks extract conditional feature maps at different resolutions, providing accurate conditional information that guides the diffusion model for conditional generation.SRNDiff surpasses GANs in terms of prediction accuracy, although it requires more computational resources.The SRNDiff model exhibits higher stability and efficiency during training than GANs-based approaches, and generates high-quality precipitation distribution samples that better reflect future actual precipitation conditions. This fully validates the advantages and potential of diffusion models in precipitation forecasting, providing new insights for enhancing rainfall prediction.
Two-stage Rainfall-Forecasting Diffusion Model
Feb 20, 2024Deep neural networks have made great achievements in rainfall prediction.However, the current forecasting methods have certain limitations, such as with blurry generated images and incorrect spatial positions. To overcome these challenges, we propose a Two-stage Rainfall-Forecasting Diffusion Model (TRDM) aimed at improving the accuracy of long-term rainfall forecasts and addressing the imbalance in performance between temporal and spatial modeling. TRDM is a two-stage method for rainfall prediction tasks. The task of the first stage is to capture robust temporal information while preserving spatial information under low-resolution conditions. The task of the second stage is to reconstruct the low-resolution images generated in the first stage into high-resolution images. We demonstrate state-of-the-art results on the MRMS and Swedish radar datasets. Our project is open source and available on GitHub at: \href{https://github.com/clearlyzerolxd/TRDM}{https://github.com/clearlyzerolxd/TRDM}.
Sequential Random Network for Fine-grained Image Classification
Mar 12, 2021
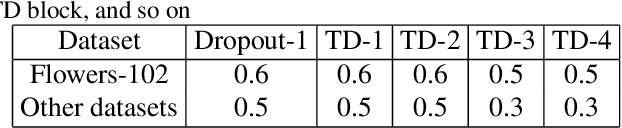
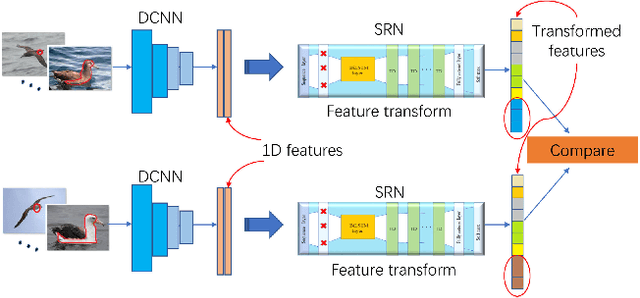
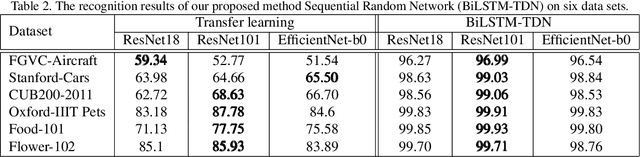
Deep Convolutional Neural Network (DCNN) and Transformer have achieved remarkable successes in image recognition. However, their performance in fine-grained image recognition is still difficult to meet the requirements of actual needs. This paper proposes a Sequence Random Network (SRN) to enhance the performance of DCNN. The output of DCNN is one-dimensional features. This one-dimensional feature abstractly represents image information, but it does not express well the detailed information of image. To address this issue, we use the proposed SRN which composed of BiLSTM and several Tanh-Dropout blocks (called BiLSTM-TDN), to further process DCNN one-dimensional features for highlighting the detail information of image. After the feature transform by BiLSTM-TDN, the recognition performance has been greatly improved. We conducted the experiments on six fine-grained image datasets. Except for FGVC-Aircraft, the accuracies of the proposed methods on the other datasets exceeded 99%. Experimental results show that BiLSTM-TDN is far superior to the existing state-of-the-art methods. In addition to DCNN, BiLSTM-TDN can also be extended to other models, such as Transformer.
Towards Good Practices for Video Object Segmentation
Sep 30, 2019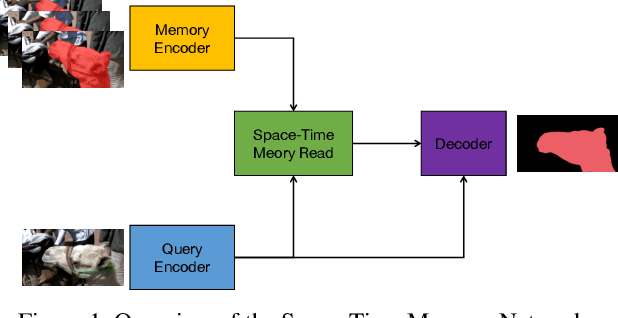

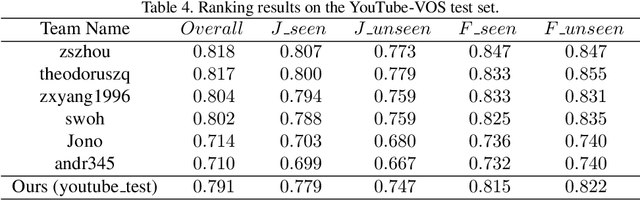
Semi-supervised video object segmentation is an interesting yet challenging task in machine learning. In this work, we conduct a series of refinements with the propagation-based video object segmentation method and empirically evaluate their impact on the final model performance through ablation study. By taking all the refinements, we improve the space-time memory networks to achieve a Overall of 79.1 on the Youtube-VOS Challenge 2019.