 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFC-RFNet: A Multi-scale Guided Rectified Flow Network for Radar Sequence Prediction
Jan 07, 2026Accurate and high-resolution precipitation nowcasting from radar echo sequences is crucial for disaster mitigation and economic planning, yet it remains a significant challenge. Key difficulties include modeling complex multi-scale evolution, correcting inter-frame feature misalignment caused by displacement, and efficiently capturing long-range spatiotemporal context without sacrificing spatial fidelity. To address these issues, we present the Multi-scale Feature Communication Rectified Flow (RF) Network (MFC-RFNet), a generative framework that integrates multi-scale communication with guided feature fusion. To enhance multi-scale fusion while retaining fine detail, a Wavelet-Guided Skip Connection (WGSC) preserves high-frequency components, and a Feature Communication Module (FCM) promotes bidirectional cross-scale interaction. To correct inter-frame displacement, a Condition-Guided Spatial Transform Fusion (CGSTF) learns spatial transforms from conditioning echoes to align shallow features. The backbone adopts rectified flow training to learn near-linear probability-flow trajectories, enabling few-step sampling with stable fidelity. Additionally, lightweight Vision-RWKV (RWKV) blocks are placed at the encoder tail, the bottleneck, and the first decoder layer to capture long-range spatiotemporal dependencies at low spatial resolutions with moderate compute. Evaluations on four public datasets (SEVIR, MeteoNet, Shanghai, and CIKM) demonstrate consistent improvements over strong baselines, yielding clearer echo morphology at higher rain-rate thresholds and sustained skill at longer lead times. These results suggest that the proposed synergy of RF training with scale-aware communication, spatial alignment, and frequency-aware fusion presents an effective and robust approach for radar-based nowcasting.
LangPrecip: Language-Aware Multimodal Precipitation Nowcasting
Dec 26, 2025Short-term precipitation nowcasting is an inherently uncertain and under-constrained spatiotemporal forecasting problem, especially for rapidly evolving and extreme weather events. Existing generative approaches rely primarily on visual conditioning, leaving future motion weakly constrained and ambiguous. We propose a language-aware multimodal nowcasting framework(LangPrecip) that treats meteorological text as a semantic motion constraint on precipitation evolution. By formulating nowcasting as a semantically constrained trajectory generation problem under the Rectified Flow paradigm, our method enables efficient and physically consistent integration of textual and radar information in latent space.We further introduce LangPrecip-160k, a large-scale multimodal dataset with 160k paired radar sequences and motion descriptions. Experiments on Swedish and MRMS datasets show consistent improvements over state-of-the-art methods, achieving over 60 \% and 19\% gains in heavy-rainfall CSI at an 80-minute lead time.
SRNDiff: Short-term Rainfall Nowcasting with Condition Diffusion Model
Feb 21, 2024Diffusion models are widely used in image generation because they can generate high-quality and realistic samples. This is in contrast to generative adversarial networks (GANs) and variational autoencoders (VAEs), which have some limitations in terms of image quality.We introduce the diffusion model to the precipitation forecasting task and propose a short-term precipitation nowcasting with condition diffusion model based on historical observational data, which is referred to as SRNDiff. By incorporating an additional conditional decoder module in the denoising process, SRNDiff achieves end-to-end conditional rainfall prediction. SRNDiff is composed of two networks: a denoising network and a conditional Encoder network. The conditional network is composed of multiple independent UNet networks. These networks extract conditional feature maps at different resolutions, providing accurate conditional information that guides the diffusion model for conditional generation.SRNDiff surpasses GANs in terms of prediction accuracy, although it requires more computational resources.The SRNDiff model exhibits higher stability and efficiency during training than GANs-based approaches, and generates high-quality precipitation distribution samples that better reflect future actual precipitation conditions. This fully validates the advantages and potential of diffusion models in precipitation forecasting, providing new insights for enhancing rainfall prediction.
Sequential Random Network for Fine-grained Image Classification
Mar 12, 2021
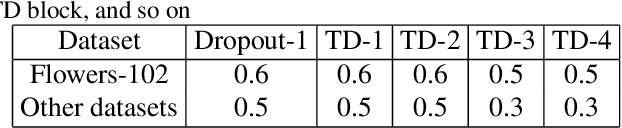
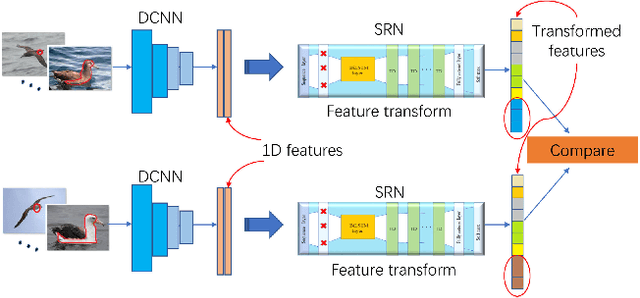
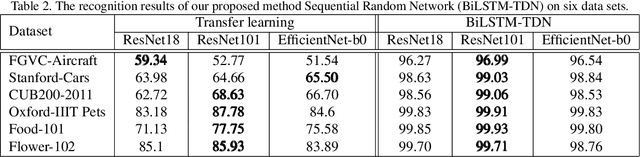
Deep Convolutional Neural Network (DCNN) and Transformer have achieved remarkable successes in image recognition. However, their performance in fine-grained image recognition is still difficult to meet the requirements of actual needs. This paper proposes a Sequence Random Network (SRN) to enhance the performance of DCNN. The output of DCNN is one-dimensional features. This one-dimensional feature abstractly represents image information, but it does not express well the detailed information of image. To address this issue, we use the proposed SRN which composed of BiLSTM and several Tanh-Dropout blocks (called BiLSTM-TDN), to further process DCNN one-dimensional features for highlighting the detail information of image. After the feature transform by BiLSTM-TDN, the recognition performance has been greatly improved. We conducted the experiments on six fine-grained image datasets. Except for FGVC-Aircraft, the accuracies of the proposed methods on the other datasets exceeded 99%. Experimental results show that BiLSTM-TDN is far superior to the existing state-of-the-art methods. In addition to DCNN, BiLSTM-TDN can also be extended to other models, such as Transformer.
LGLG-WPCA: An Effective Texture-based Method for Face Recognition
Nov 20, 2018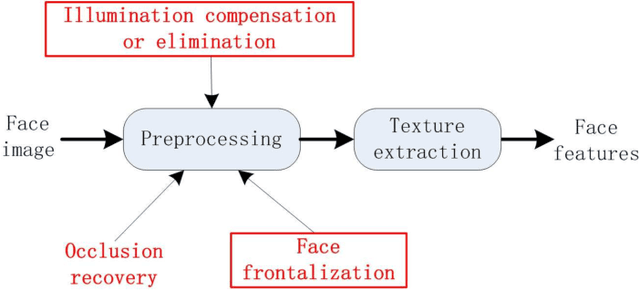
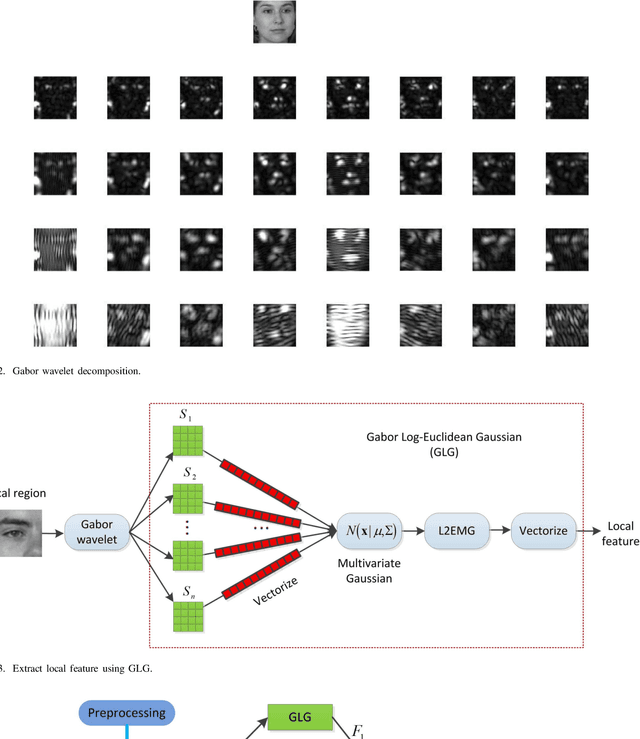
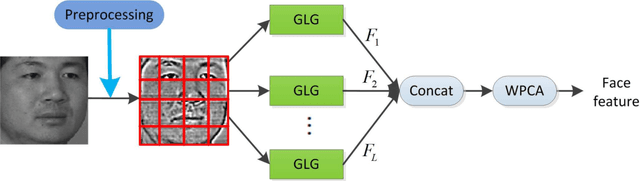
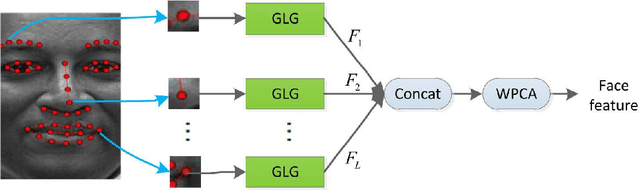
This paper proposes an effective texture-based face feature extraction method which is based on Learning Gabor Log-Euclidean Gaussian, called LGLG-WPCA. LGLG-WPCA has the robust performance for adverse conditions such as varying poses, skin aging and uneven illumination. LGLG learns face features from the embedded multivariate Gaussian in Gabor wavelet domain using Whitening Principal Component Analysis (WPCA). In LGLG, we first employ Gabor wavelet to decompose the face, and then use the multivariate Gaussian distribution to fit Gabor subbands. Because the space of Gaussian is a Riemannian manifold and it is difficult to incorporate learning mechanism in the model. To address this issue, we use L$^2$EMG\cite{Li2017Local} to map the multidimensional Gaussian model to the linear space, and then use WPCA to learn facial features. Experiments show that our proposed method is an effective and promising face texture feature extraction technique.