 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROGRESSLM: Towards Progress Reasoning in Vision-Language Models
Jan 21, 2026Estimating task progress requires reasoning over long-horizon dynamics rather than recognizing static visual content. While modern Vision-Language Models (VLMs) excel at describing what is visible, it remains unclear whether they can infer how far a task has progressed from partial observations. To this end, we introduce Progress-Bench, a benchmark for systematically evaluating progress reasoning in VLMs. Beyond benchmarking, we further explore a human-inspired two-stage progress reasoning paradigm through both training-free prompting and training-based approach based on curated dataset ProgressLM-45K. Experiments on 14 VLMs show that most models are not yet ready for task progress estimation, exhibiting sensitivity to demonstration modality and viewpoint changes, as well as poor handling of unanswerable cases. While training-free prompting that enforces structured progress reasoning yields limited and model-dependent gains, the training-based ProgressLM-3B achieves consistent improvements even at a small model scale, despite being trained on a task set fully disjoint from the evaluation tasks. Further analyses reveal characteristic error patterns and clarify when and why progress reasoning succeeds or fails.
DVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Jun 16, 2025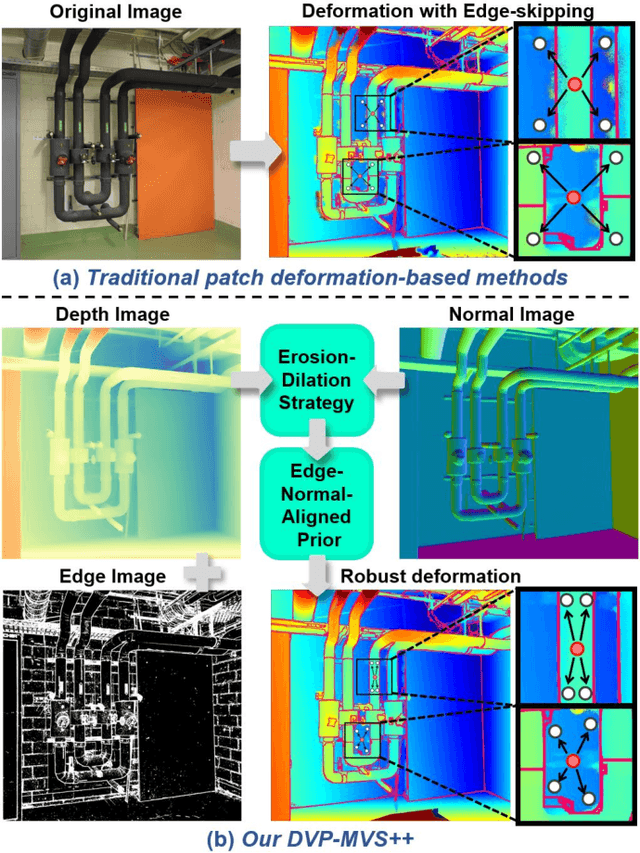
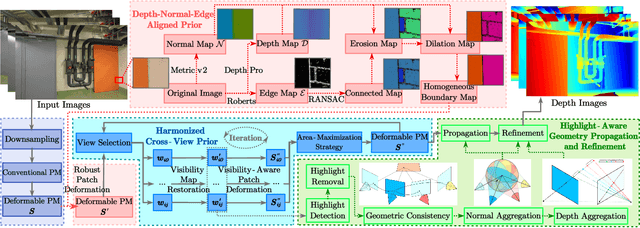
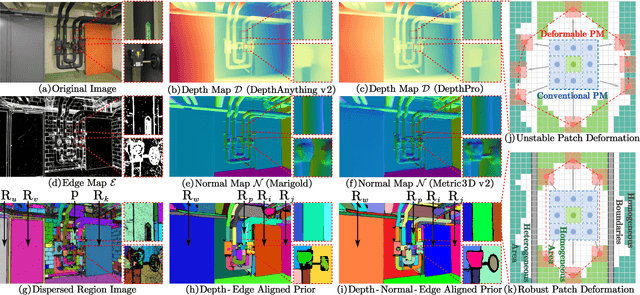
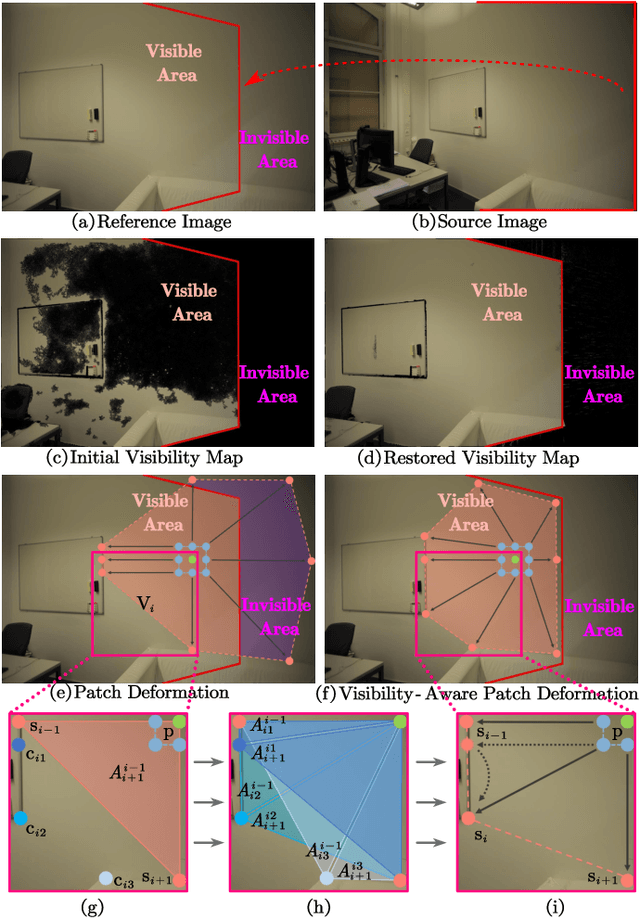
Recently, patch deformation-based methods have demonstrated significant effectiveness in multi-view stereo due to their incorporation of deformable and expandable perception for reconstructing textureless areas. However, these methods generally focus on identifying reliable pixel correlations to mitigate matching ambiguity of patch deformation, while neglecting the deformation instability caused by edge-skipping and visibility occlusions, which may cause potential estimation deviations. To address these issues, we propose DVP-MVS++, an innovative approach that synergizes both depth-normal-edge aligned and harmonized cross-view priors for robust and visibility-aware patch deformation. Specifically, to avoid edge-skipping, we first apply DepthPro, Metric3Dv2 and Roberts operator to generate coarse depth maps, normal maps and edge maps, respectively. These maps are then aligned via an erosion-dilation strategy to produce fine-grained homogeneous boundaries for facilitating robust patch deformation. Moreover, we reformulate view selection weights as visibility maps, and then implement both an enhanced cross-view depth reprojection and an area-maximization strategy to help reliably restore visible areas and effectively balance deformed patch, thus acquiring harmonized cross-view priors for visibility-aware patch deformation. Additionally, we obtain geometry consistency by adopting both aggregated normals via view selection and projection depth differences via epipolar lines, and then employ SHIQ for highlight correction to enable geometry consistency with highlight-aware perception, thus improving reconstruction quality during propagation and refinement stage. Evaluation results on ETH3D, Tanks & Temples and Strecha datasets exhibit the state-of-the-art performance and robust generalization capability of our proposed method.
HAIF-GS: Hierarchical and Induced Flow-Guided Gaussian Splatting for Dynamic Scene
Jun 11, 2025Reconstructing dynamic 3D scenes from monocular videos remains a fundamental challenge in 3D vision. While 3D Gaussian Splatting (3DGS) achieves real-time rendering in static settings, extending it to dynamic scenes is challenging due to the difficulty of learning structured and temporally consistent motion representations. This challenge often manifests as three limitations in existing methods: redundant Gaussian updates, insufficient motion supervision, and weak modeling of complex non-rigid deformations. These issues collectively hinder coherent and efficient dynamic reconstruction. To address these limitations, we propose HAIF-GS, a unified framework that enables structured and consistent dynamic modeling through sparse anchor-driven deformation. It first identifies motion-relevant regions via an Anchor Filter to suppresses redundant updates in static areas. A self-supervised Induced Flow-Guided Deformation module induces anchor motion using multi-frame feature aggregation, eliminating the need for explicit flow labels. To further handle fine-grained deformations, a Hierarchical Anchor Propagation mechanism increases anchor resolution based on motion complexity and propagates multi-level transformations. Extensive experiments on synthetic and real-world benchmarks validate that HAIF-GS significantly outperforms prior dynamic 3DGS methods in rendering quality, temporal coherence, and reconstruction efficiency.
Adaptive Label Correction for Robust Medical Image Segmentation with Noisy Labels
Mar 15, 2025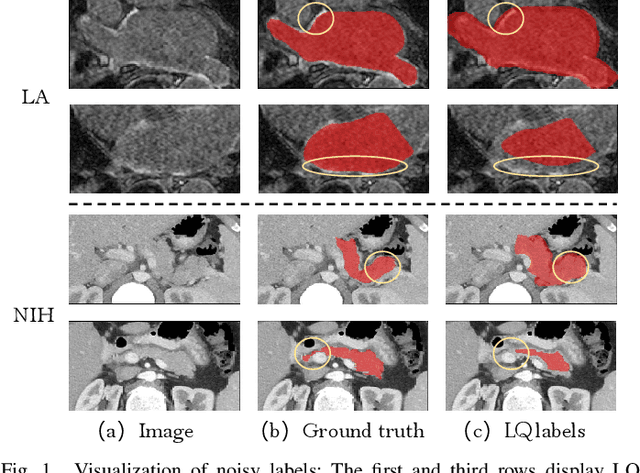
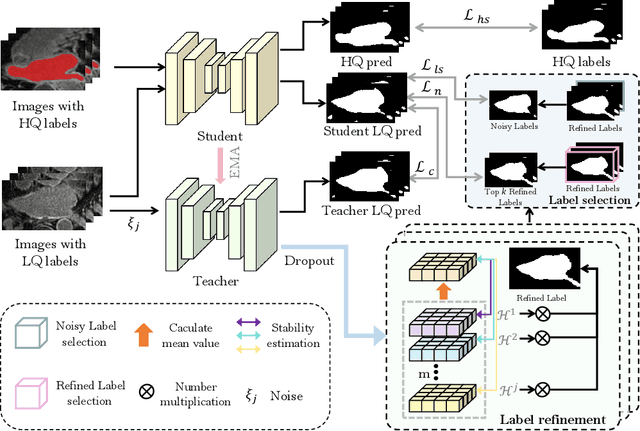
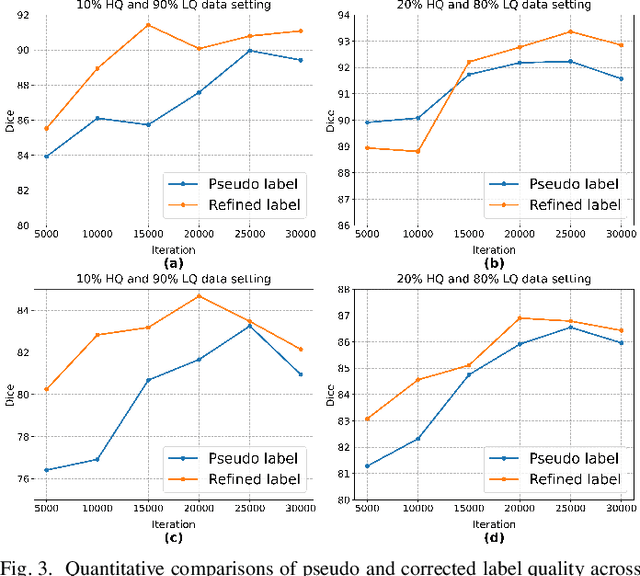

Deep learning has shown remarkable success in medical image analysis, but its reliance on large volumes of high-quality labeled data limits its applicability. While noisy labeled data are easier to obtain, directly incorporating them into training can degrade model performance. To address this challenge, we propose a Mean Teacher-based Adaptive Label Correction (ALC) self-ensemble framework for robust medical image segmentation with noisy labels. The framework leverages the Mean Teacher architecture to ensure consistent learning under noise perturbations. It includes an adaptive label refinement mechanism that dynamically captures and weights differences across multiple disturbance versions to enhance the quality of noisy labels. Additionally, a sample-level uncertainty-based label selection algorithm is introduced to prioritize high-confidence samples for network updates, mitigating the impact of noisy annotations. Consistency learning is integrated to align the predictions of the student and teacher networks, further enhancing model robustness. Extensive experiments on two public datasets demonstrate the effectiveness of the proposed framework, showing significant improvements in segmentation performance. By fully exploiting the strengths of the Mean Teacher structure, the ALC framework effectively processes noisy labels, adapts to challenging scenarios, and achieves competitive results compared to state-of-the-art methods.
DecAlign: Hierarchical Cross-Modal Alignment for Decoupled Multimodal Representation Learning
Mar 14, 2025Multimodal representation learning aims to capture both shared and complementary semantic information across multiple modalities. However, the intrinsic heterogeneity of diverse modalities presents substantial challenges to achieve effective cross-modal collaboration and integration. To address this, we introduce DecAlign, a novel hierarchical cross-modal alignment framework designed to decouple multimodal representations into modality-unique (heterogeneous) and modality-common (homogeneous) features. For handling heterogeneity, we employ a prototype-guided optimal transport alignment strategy leveraging gaussian mixture modeling and multi-marginal transport plans, thus mitigating distribution discrepancies while preserving modality-unique characteristics. To reinforce homogeneity, we ensure semantic consistency across modalities by aligning latent distribution matching with Maximum Mean Discrepancy regularization. Furthermore, we incorporate a multimodal transformer to enhance high-level semantic feature fusion, thereby further reducing cross-modal inconsistencies. Our extensive experiments on four widely used multimodal benchmarks demonstrate that DecAlign consistently outperforms existing state-of-the-art methods across five metrics. These results highlight the efficacy of DecAlign in enhancing superior cross-modal alignment and semantic consistency while preserving modality-unique features, marking a significant advancement in multimodal representation learning scenarios. Our project page is at https://taco-group.github.io/DecAlign and the code is available at https://github.com/taco-group/DecAlign.
DynCIM: Dynamic Curriculum for Imbalanced Multimodal Learning
Mar 09, 2025Multimodal learning integrates complementary information from diverse modalities to enhance the decision-making process. However, the potential of multimodal collaboration remains under-exploited due to disparities in data quality and modality representation capabilities. To address this, we introduce DynCIM, a novel dynamic curriculum learning framework designed to quantify the inherent imbalances from both sample and modality perspectives. DynCIM employs a sample-level curriculum to dynamically assess each sample's difficulty according to prediction deviation, consistency, and stability, while a modality-level curriculum measures modality contributions from global and local. Furthermore, a gating-based dynamic fusion mechanism is introduced to adaptively adjust modality contributions, minimizing redundancy and optimizing fusion effectiveness. Extensive experiments on six multimodal benchmarking datasets, spanning both bimodal and trimodal scenarios, demonstrate that DynCIM consistently outperforms state-of-the-art methods. Our approach effectively mitigates modality and sample imbalances while enhancing adaptability and robustness in multimodal learning tasks. Our code is available at https://github.com/Raymond-Qiancx/DynCIM.
Re-Align: Aligning Vision Language Models via Retrieval-Augmented Direct Preference Optimization
Feb 18, 2025



The emergence of large Vision Language Models (VLMs) has broadened the scope and capabilities of single-modal Large Language Models (LLMs) by integrating visual modalities, thereby unlocking transformative cross-modal applications in a variety of real-world scenarios. Despite their impressive performance, VLMs are prone to significant hallucinations, particularly in the form of cross-modal inconsistencies. Building on the success of Reinforcement Learning from Human Feedback (RLHF) in aligning LLMs, recent advancements have focused on applying direct preference optimization (DPO) on carefully curated datasets to mitigate these issues. Yet, such approaches typically introduce preference signals in a brute-force manner, neglecting the crucial role of visual information in the alignment process. In this paper, we introduce Re-Align, a novel alignment framework that leverages image retrieval to construct a dual-preference dataset, effectively incorporating both textual and visual preference signals. We further introduce rDPO, an extension of the standard direct preference optimization that incorporates an additional visual preference objective during fine-tuning. Our experimental results demonstrate that Re-Align not only mitigates hallucinations more effectively than previous methods but also yields significant performance gains in general visual question-answering (VQA) tasks. Moreover, we show that Re-Align maintains robustness and scalability across a wide range of VLM sizes and architectures. This work represents a significant step forward in aligning multimodal LLMs, paving the way for more reliable and effective cross-modal applications. We release all the code in https://github.com/taco-group/Re-Align.