 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4KLSDB: A Large-Scale Dataset for 4K Image Restoration and Generation
May 23, 2026High-resolution datasets are essential for advancing super-resolution (SR) and text-to-image (T2I) diffusion research. However, current publicly available datasets lack both the native 4K resolution and the extensive scale necessary for training state-of-the-art models. To address this gap, we introduce a 4K Large Scale Dataset and Benchmark (4KLSDB), a large-scale, diverse dataset consisting of 129,484 carefully curated 4K resolution images spanning multiple categories such as nature, urban scenes, people, food, artwork, and CGI, alongside distinct validation and test sets containing 2,000 and 1,984 images respectively. Images were sourced from established open datasets including Photo Concept Bucket, Laion2B, and PD12M. 4KLSDB underwent rigorous multi-stage automated filtering and annotation pipelines involving both human annotators and Large Multimodal Models (LMMs) to ensure high aesthetic quality and dataset consistency. We demonstrate 4KLSDB's effectiveness by training representative super-resolution and diffusion models, observing significant improvements in performance on native 4K benchmarks. Comprehensive experiments illustrate a positive correlation between training on true 4K resolution data and improved fidelity in image restoration task, especially on 4K resolution. We provide the research community a valuable resource to drive progress toward genuinely high-fidelity image synthesis and restoration by providing 4KLSDB. Our project page is available at: https://4klsdb.github.io/.
GuideSR: Rethinking Guidance for One-Step High-Fidelity Diffusion-Based Super-Resolution
May 01, 2025In this paper, we propose GuideSR, a novel single-step diffusion-based image super-resolution (SR) model specifically designed to enhance image fidelity. Existing diffusion-based SR approaches typically adapt pre-trained generative models to image restoration tasks by adding extra conditioning on a VAE-downsampled representation of the degraded input, which often compromises structural fidelity. GuideSR addresses this limitation by introducing a dual-branch architecture comprising: (1) a Guidance Branch that preserves high-fidelity structures from the original-resolution degraded input, and (2) a Diffusion Branch, which a pre-trained latent diffusion model to enhance perceptual quality. Unlike conventional conditioning mechanisms, our Guidance Branch features a tailored structure for image restoration tasks, combining Full Resolution Blocks (FRBs) with channel attention and an Image Guidance Network (IGN) with guided attention. By embedding detailed structural information directly into the restoration pipeline, GuideSR produces sharper and more visually consistent results. Extensive experiments on benchmark datasets demonstrate that GuideSR achieves state-of-the-art performance while maintaining the low computational cost of single-step approaches, with up to 1.39dB PSNR gain on challenging real-world datasets. Our approach consistently outperforms existing methods across various reference-based metrics including PSNR, SSIM, LPIPS, DISTS and FID, further representing a practical advancement for real-world image restoration.
Re-Align: Aligning Vision Language Models via Retrieval-Augmented Direct Preference Optimization
Feb 18, 2025



The emergence of large Vision Language Models (VLMs) has broadened the scope and capabilities of single-modal Large Language Models (LLMs) by integrating visual modalities, thereby unlocking transformative cross-modal applications in a variety of real-world scenarios. Despite their impressive performance, VLMs are prone to significant hallucinations, particularly in the form of cross-modal inconsistencies. Building on the success of Reinforcement Learning from Human Feedback (RLHF) in aligning LLMs, recent advancements have focused on applying direct preference optimization (DPO) on carefully curated datasets to mitigate these issues. Yet, such approaches typically introduce preference signals in a brute-force manner, neglecting the crucial role of visual information in the alignment process. In this paper, we introduce Re-Align, a novel alignment framework that leverages image retrieval to construct a dual-preference dataset, effectively incorporating both textual and visual preference signals. We further introduce rDPO, an extension of the standard direct preference optimization that incorporates an additional visual preference objective during fine-tuning. Our experimental results demonstrate that Re-Align not only mitigates hallucinations more effectively than previous methods but also yields significant performance gains in general visual question-answering (VQA) tasks. Moreover, we show that Re-Align maintains robustness and scalability across a wide range of VLM sizes and architectures. This work represents a significant step forward in aligning multimodal LLMs, paving the way for more reliable and effective cross-modal applications. We release all the code in https://github.com/taco-group/Re-Align.
Edit Away and My Face Will not Stay: Personal Biometric Defense against Malicious Generative Editing
Nov 25, 2024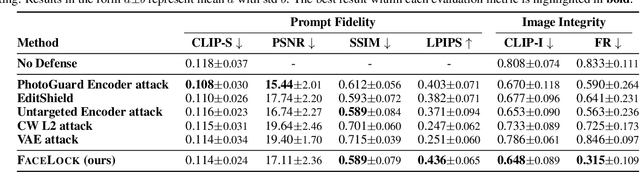
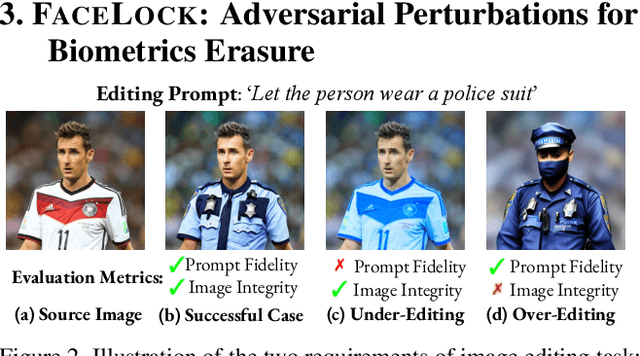
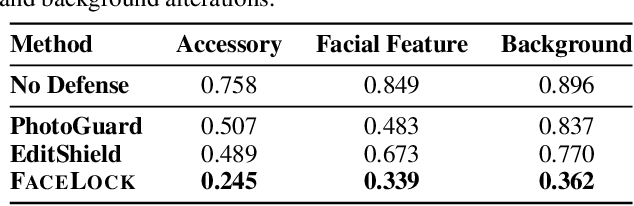

Recent advancements in diffusion models have made generative image editing more accessible, enabling creative edits but raising ethical concerns, particularly regarding malicious edits to human portraits that threaten privacy and identity security. Existing protection methods primarily rely on adversarial perturbations to nullify edits but often fail against diverse editing requests. We propose FaceLock, a novel approach to portrait protection that optimizes adversarial perturbations to destroy or significantly alter biometric information, rendering edited outputs biometrically unrecognizable. FaceLock integrates facial recognition and visual perception into perturbation optimization to provide robust protection against various editing attempts. We also highlight flaws in commonly used evaluation metrics and reveal how they can be manipulated, emphasizing the need for reliable assessments of protection. Experiments show FaceLock outperforms baselines in defending against malicious edits and is robust against purification techniques. Ablation studies confirm its stability and broad applicability across diffusion-based editing algorithms. Our work advances biometric defense and sets the foundation for privacy-preserving practices in image editing. The code is available at: https://github.com/taco-group/FaceLock.