 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Post-training Quantization for Reparameterized Models
Feb 25, 2024



Model reparameterization is a widely accepted technique for improving inference speed without compromising performance. However, current Post-training Quantization (PTQ) methods often lead to significant accuracy degradation when applied to reparameterized models. This is primarily caused by channel-specific and sample-specific outliers, which appear only at specific samples and channels and impact on the selection of quantization parameters. To address this issue, we propose RepAPQ, a novel framework that preserves the accuracy of quantized reparameterization models. Different from previous frameworks using Mean Squared Error (MSE) as a measurement, we utilize Mean Absolute Error (MAE) to mitigate the influence of outliers on quantization parameters. Our framework comprises two main components: Quantization Protecting Reparameterization and Across-block Calibration. For effective calibration, Quantization Protecting Reparameterization combines multiple branches into a single convolution with an affine layer. During training, the affine layer accelerates convergence and amplifies the output of the convolution to better accommodate samples with outliers. Additionally, Across-block Calibration leverages the measurement of stage output as supervision to address the gradient problem introduced by MAE and enhance the interlayer correlation with quantization parameters. Comprehensive experiments demonstrate the effectiveness of RepAPQ across various models and tasks. Our framework outperforms previous methods by approximately 1\% for 8-bit PTQ and 2\% for 6-bit PTQ, showcasing its superior performance. The code is available at \url{https://github.com/ilur98/DLMC-QUANT}.
Dual Grained Quantization: Efficient Fine-Grained Quantization for LLM
Oct 07, 2023Large Language Models (LLMs) pose significant hardware challenges related to memory requirements and computational ability. There are two mainstream quantization schemes for LLMs: coarse-grained ($\textit{e.g.,}$ channel-wise) quantization and fine-grained ($\textit{e.g.,}$ group-wise) quantization. Fine-grained quantization has smaller quantization loss, consequently achieving superior performance. However, when applied to weight-activation quantization, it disrupts continuous integer matrix multiplication, leading to inefficient inference. In this paper, we introduce Dual Grained Quantization (DGQ), a novel A8W4 quantization for LLM that maintains superior performance while ensuring fast inference speed. DSQ dequantizes the fine-grained INT4 weight into coarse-grained INT8 representation and preform matrix multiplication using INT8 kernels. Besides, we develop a two-phase grid search algorithm to simplify the determination of fine-grained and coarse-grained quantization scales. We also devise a percentile clipping schema for smoothing the activation outliers without the need for complex optimization techniques. Experimental results demonstrate that DGQ consistently outperforms prior methods across various LLM architectures and a wide range of tasks. Remarkably, by our implemented efficient CUTLASS kernel, we achieve $\textbf{1.12}$ $\times$ memory reduction and $\textbf{3.24}$ $\times$ speed gains comparing A16W4 implementation. These advancements enable efficient deployment of A8W4 LLMs for real-world applications.
GEmo-CLAP: Gender-Attribute-Enhanced Contrastive Language-Audio Pretraining for Speech Emotion Recognition
Jun 16, 2023



Contrastive learning based pretraining methods have recently exhibited impressive success in diverse fields. In this paper, we propose GEmo-CLAP, a kind of efficient gender-attribute-enhanced contrastive language-audio pretraining (CLAP) model for speech emotion recognition. To be specific, we first build an effective emotion CLAP model Emo-CLAP for emotion recognition, utilizing various self-supervised learning based pre-trained models. Then, considering the importance of the gender attribute in speech emotion modeling, two GEmo-CLAP approaches are further proposed to integrate the emotion and gender information of speech signals, forming more reasonable objectives. Extensive experiments on the IEMOCAP corpus demonstrate that our proposed two GEmo-CLAP approaches consistently outperform the baseline Emo-CLAP with different pre-trained models, while also achieving superior recognition performance compared with other state-of-the-art methods.
MimicNorm: Weight Mean and Last BN Layer Mimic the Dynamic of Batch Normalization
Oct 24, 2020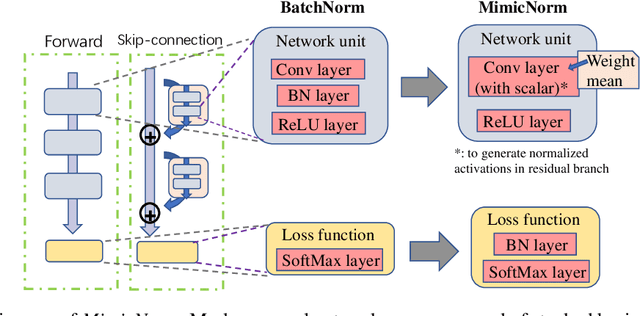


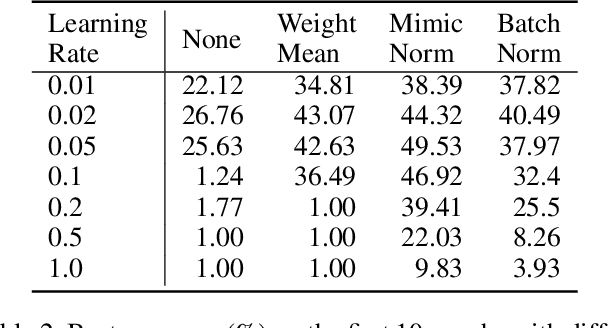
Substantial experiments have validated the success of Batch Normalization (BN) Layer in benefiting convergence and generalization. However, BN requires extra memory and float-point calculation. Moreover, BN would be inaccurate on micro-batch, as it depends on batch statistics. In this paper, we address these problems by simplifying BN regularization while keeping two fundamental impacts of BN layers, i.e., data decorrelation and adaptive learning rate. We propose a novel normalization method, named MimicNorm, to improve the convergence and efficiency in network training. MimicNorm consists of only two light operations, including modified weight mean operations (subtract mean values from weight parameter tensor) and one BN layer before loss function (last BN layer). We leverage the neural tangent kernel (NTK) theory to prove that our weight mean operation whitens activations and transits network into the chaotic regime like BN layer, and consequently, leads to an enhanced convergence. The last BN layer provides autotuned learning rates and also improves accuracy. Experimental results show that MimicNorm achieves similar accuracy for various network structures, including ResNets and lightweight networks like ShuffleNet, with a reduction of about 20% memory consumption. The code is publicly available at https://github.com/Kid-key/MimicNorm.