 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Good Enough Is Optimal: Multiplication-Only Matrix Inversion Approximation for Quantized Gated DeltaNet
Jun 04, 2026Matrix inversion in chunk-wise parallel linear attention is a major bottleneck for long-context modeling, particularly on NPUs, where forward-substitution-based methods exhibit limited parallelism and poor hardware utilization. We propose a fast, Matrix Multiplication (MatMul)-based algorithm tailored for strictly lower-triangular matrices arising in chunk-wise linear attention. Motivated by the rapid growth of Neumann-series terms and the diagonal concentration of the inverse matrix, we employ a truncated Neumann expansion with structural masking and parallel residual correction to eliminate sequential dependencies. We further extend our method to low-bits INT by mitigating the dynamic range expansion arising from repeated matrix power operations, and adapt the approximation order and residual step to the chunk size to minimize computational cost while preserving the model's accuracy. Experiments on Qwen3.5-family models demonstrate up to 5$\times$ kernel-level speedup and a 20% reduction in decode-layer overhead, while preserving accuracy under both floating-point and low-precision inference. Our method offers an efficient and hardware-friendly solution for scalable linear attention.
ZipCache: Accurate and Efficient KV Cache Quantization with Salient Token Identification
May 23, 2024



KV cache stores key and value states from previous tokens to avoid re-computation, yet it demands substantial storage space, especially for long sequences. Adaptive KV cache compression seeks to discern the saliency of tokens, preserving vital information while aggressively compressing those of less importance. However, previous methods of this approach exhibit significant performance degradation at high compression ratios due to inaccuracies in identifying salient tokens. In this paper, we present ZipCache, an accurate and efficient KV cache quantization method for LLMs. First, we construct a strong baseline for quantizing KV cache. Through the proposed channel-separable tokenwise quantization scheme, the memory overhead of quantization parameters are substantially reduced compared to fine-grained groupwise quantization. To enhance the compression ratio, we propose normalized attention score as an effective metric for identifying salient tokens by considering the lower triangle characteristics of the attention matrix. Moreover, we develop an efficient approximation method that decouples the saliency metric from full attention scores, enabling compatibility with fast attention implementations like FlashAttention. Extensive experiments demonstrate that ZipCache achieves superior compression ratios, fast generation speed and minimal performance losses compared with previous KV cache compression methods. For instance, when evaluating Mistral-7B model on GSM8k dataset, ZipCache is capable of compressing the KV cache by $4.98\times$, with only a $0.38\%$ drop in accuracy. In terms of efficiency, ZipCache also showcases a $37.3\%$ reduction in prefill-phase latency, a $56.9\%$ reduction in decoding-phase latency, and a $19.8\%$ reduction in GPU memory usage when evaluating LLaMA3-8B model with a input length of $4096$.
Towards Accurate Post-training Quantization for Reparameterized Models
Feb 25, 2024



Model reparameterization is a widely accepted technique for improving inference speed without compromising performance. However, current Post-training Quantization (PTQ) methods often lead to significant accuracy degradation when applied to reparameterized models. This is primarily caused by channel-specific and sample-specific outliers, which appear only at specific samples and channels and impact on the selection of quantization parameters. To address this issue, we propose RepAPQ, a novel framework that preserves the accuracy of quantized reparameterization models. Different from previous frameworks using Mean Squared Error (MSE) as a measurement, we utilize Mean Absolute Error (MAE) to mitigate the influence of outliers on quantization parameters. Our framework comprises two main components: Quantization Protecting Reparameterization and Across-block Calibration. For effective calibration, Quantization Protecting Reparameterization combines multiple branches into a single convolution with an affine layer. During training, the affine layer accelerates convergence and amplifies the output of the convolution to better accommodate samples with outliers. Additionally, Across-block Calibration leverages the measurement of stage output as supervision to address the gradient problem introduced by MAE and enhance the interlayer correlation with quantization parameters. Comprehensive experiments demonstrate the effectiveness of RepAPQ across various models and tasks. Our framework outperforms previous methods by approximately 1\% for 8-bit PTQ and 2\% for 6-bit PTQ, showcasing its superior performance. The code is available at \url{https://github.com/ilur98/DLMC-QUANT}.
DSText V2: A Comprehensive Video Text Spotting Dataset for Dense and Small Text
Nov 29, 2023



Recently, video text detection, tracking, and recognition in natural scenes are becoming very popular in the computer vision community. However, most existing algorithms and benchmarks focus on common text cases (e.g., normal size, density) and single scenario, while ignoring extreme video text challenges, i.e., dense and small text in various scenarios. In this paper, we establish a video text reading benchmark, named DSText V2, which focuses on Dense and Small text reading challenges in the video with various scenarios. Compared with the previous datasets, the proposed dataset mainly include three new challenges: 1) Dense video texts, a new challenge for video text spotters to track and read. 2) High-proportioned small texts, coupled with the blurriness and distortion in the video, will bring further challenges. 3) Various new scenarios, e.g., Game, Sports, etc. The proposed DSText V2 includes 140 video clips from 7 open scenarios, supporting three tasks, i.e., video text detection (Task 1), video text tracking (Task 2), and end-to-end video text spotting (Task 3). In this article, we describe detailed statistical information of the dataset, tasks, evaluation protocols, and the results summaries. Most importantly, a thorough investigation and analysis targeting three unique challenges derived from our dataset are provided, aiming to provide new insights. Moreover, we hope the benchmark will promise video text research in the community. DSText v2 is built upon DSText v1, which was previously introduced to organize the ICDAR 2023 competition for dense and small video text.
* arXiv admin note: text overlap with arXiv:2304.04376
Dual Grained Quantization: Efficient Fine-Grained Quantization for LLM
Oct 07, 2023Large Language Models (LLMs) pose significant hardware challenges related to memory requirements and computational ability. There are two mainstream quantization schemes for LLMs: coarse-grained ($\textit{e.g.,}$ channel-wise) quantization and fine-grained ($\textit{e.g.,}$ group-wise) quantization. Fine-grained quantization has smaller quantization loss, consequently achieving superior performance. However, when applied to weight-activation quantization, it disrupts continuous integer matrix multiplication, leading to inefficient inference. In this paper, we introduce Dual Grained Quantization (DGQ), a novel A8W4 quantization for LLM that maintains superior performance while ensuring fast inference speed. DSQ dequantizes the fine-grained INT4 weight into coarse-grained INT8 representation and preform matrix multiplication using INT8 kernels. Besides, we develop a two-phase grid search algorithm to simplify the determination of fine-grained and coarse-grained quantization scales. We also devise a percentile clipping schema for smoothing the activation outliers without the need for complex optimization techniques. Experimental results demonstrate that DGQ consistently outperforms prior methods across various LLM architectures and a wide range of tasks. Remarkably, by our implemented efficient CUTLASS kernel, we achieve $\textbf{1.12}$ $\times$ memory reduction and $\textbf{3.24}$ $\times$ speed gains comparing A16W4 implementation. These advancements enable efficient deployment of A8W4 LLMs for real-world applications.
BiViT: Extremely Compressed Binary Vision Transformer
Nov 14, 2022



Model binarization can significantly compress model size, reduce energy consumption, and accelerate inference through efficient bit-wise operations. Although binarizing convolutional neural networks have been extensively studied, there is little work on exploring binarization on vision Transformers which underpin most recent breakthroughs in visual recognition. To this end, we propose to solve two fundamental challenges to push the horizon of Binary Vision Transformers (BiViT). First, the traditional binary method does not take the long-tailed distribution of softmax attention into consideration, bringing large binarization errors in the attention module. To solve this, we propose Softmax-aware Binarization, which dynamically adapts to the data distribution and reduces the error caused by binarization. Second, to better exploit the information of the pretrained model and restore accuracy, we propose a Cross-layer Binarization scheme and introduce learnable channel-wise scaling factors for weight binarization. The former decouples the binarization of self-attention and MLP to avoid mutual interference while the latter enhances the representation capacity of binarized models. Overall, our method performs favorably against state-of-the-arts by 19.8% on the TinyImageNet dataset. On ImageNet, BiViT achieves a competitive 70.8% Top-1 accuracy over Swin-T model, outperforming the existing SOTA methods by a clear margin.
Binarizing by Classification: Is soft function really necessary?
May 16, 2022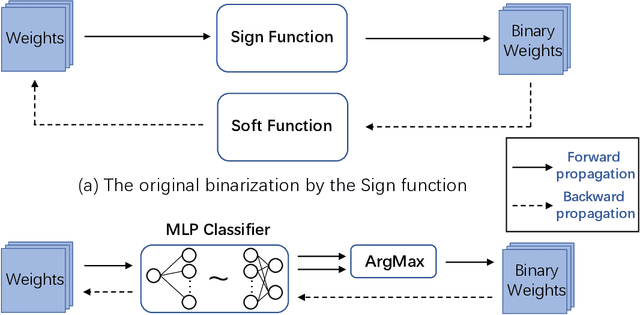

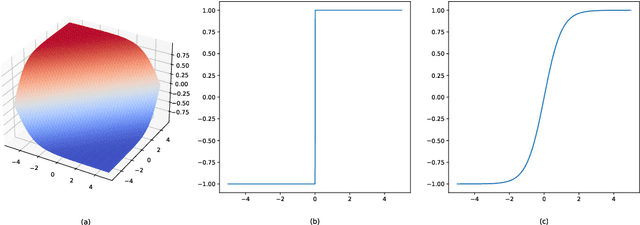

Binary neural network leverages the $Sign$ function to binarize real values, and its non-derivative property inevitably brings huge gradient errors during backpropagation. Although many hand-designed soft functions have been proposed to approximate gradients, their mechanism is not clear and there are still huge performance gaps between binary models and their full-precision counterparts. To address this, we propose to tackle network binarization as a binary classification problem and use a multi-layer perceptron (MLP) as the classifier. The MLP-based classifier can fit any continuous function theoretically and is adaptively learned to binarize networks and backpropagate gradients without any specific soft function. With this view, we further prove experimentally that even a simple linear function can outperform previous complex soft functions. Extensive experiments demonstrate that the proposed method yields surprising performance both in image classification and human pose estimation tasks. Specifically, we achieve 65.7% top-1 accuracy of ResNet-34 on ImageNet dataset, with an absolute improvement of 2.8%. When evaluating on the challenging Microsoft COCO keypoint dataset, the proposed method enables binary networks to achieve a mAP of 60.6 for the first time, on par with some full-precision methods.
Data-Free Quantization with Accurate Activation Clipping and Adaptive Batch Normalization
Apr 08, 2022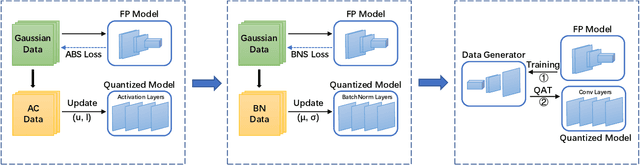
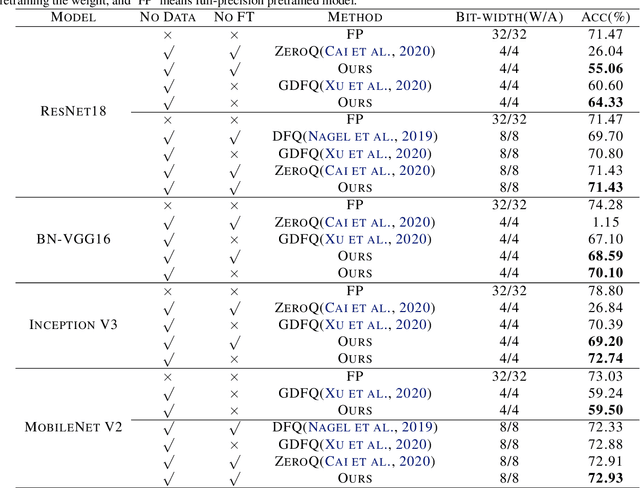
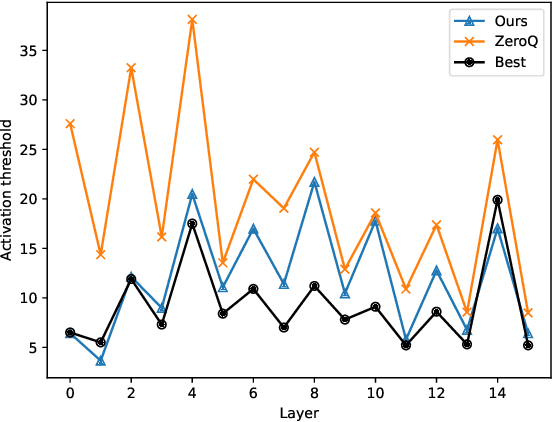
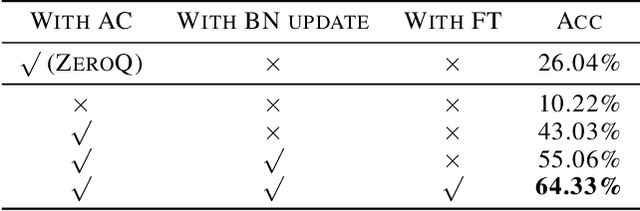
Data-free quantization is a task that compresses the neural network to low bit-width without access to original training data. Most existing data-free quantization methods cause severe performance degradation due to inaccurate activation clipping range and quantization error, especially for low bit-width. In this paper, we present a simple yet effective data-free quantization method with accurate activation clipping and adaptive batch normalization. Accurate activation clipping (AAC) improves the model accuracy by exploiting accurate activation information from the full-precision model. Adaptive batch normalization firstly proposes to address the quantization error from distribution changes by updating the batch normalization layer adaptively. Extensive experiments demonstrate that the proposed data-free quantization method can yield surprisingly performance, achieving 64.33% top-1 accuracy of ResNet18 on ImageNet dataset, with 3.7% absolute improvement outperforming the existing state-of-the-art methods.