 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTakin: A Cohort of Superior Quality Zero-shot Speech Generation Models
Sep 18, 2024



With the advent of the big data and large language model era, zero-shot personalized rapid customization has emerged as a significant trend. In this report, we introduce Takin AudioLLM, a series of techniques and models, mainly including Takin TTS, Takin VC, and Takin Morphing, specifically designed for audiobook production. These models are capable of zero-shot speech production, generating high-quality speech that is nearly indistinguishable from real human speech and facilitating individuals to customize the speech content according to their own needs. Specifically, we first introduce Takin TTS, a neural codec language model that builds upon an enhanced neural speech codec and a multi-task training framework, capable of generating high-fidelity natural speech in a zero-shot way. For Takin VC, we advocate an effective content and timbre joint modeling approach to improve the speaker similarity, while advocating for a conditional flow matching based decoder to further enhance its naturalness and expressiveness. Last, we propose the Takin Morphing system with highly decoupled and advanced timbre and prosody modeling approaches, which enables individuals to customize speech production with their preferred timbre and prosody in a precise and controllable manner. Extensive experiments validate the effectiveness and robustness of our Takin AudioLLM series models. For detailed demos, please refer to https://takinaudiollm.github.io.
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Jun 14, 2024Zero-shot voice conversion (VC) aims to transform source speech into arbitrary unseen target voice while keeping the linguistic content unchanged. Recent VC methods have made significant progress, but semantic losses in the decoupling process as well as training-inference mismatch still hinder conversion performance. In this paper, we propose Vec-Tok-VC+, a novel prompt-based zero-shot VC model improved from Vec-Tok Codec, achieving voice conversion given only a 3s target speaker prompt. We design a residual-enhanced K-Means decoupler to enhance the semantic content extraction with a two-layer clustering process. Besides, we employ teacher-guided refinement to simulate the conversion process to eliminate the training-inference mismatch, forming a dual-mode training strategy. Furthermore, we design a multi-codebook progressive loss function to constrain the layer-wise output of the model from coarse to fine to improve speaker similarity and content accuracy. Objective and subjective evaluations demonstrate that Vec-Tok-VC+ outperforms the strong baselines in naturalness, intelligibility, and speaker similarity.
Vec-Tok Speech: speech vectorization and tokenization for neural speech generation
Oct 12, 2023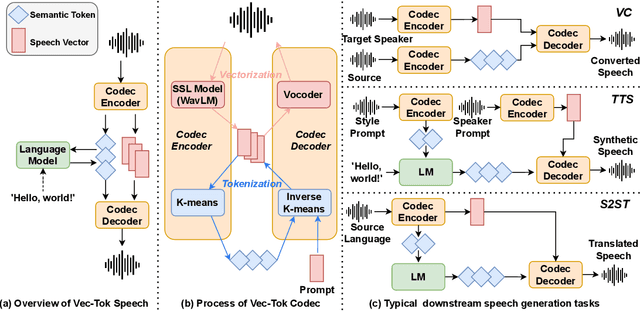


Language models (LMs) have recently flourished in natural language processing and computer vision, generating high-fidelity texts or images in various tasks. In contrast, the current speech generative models are still struggling regarding speech quality and task generalization. This paper presents Vec-Tok Speech, an extensible framework that resembles multiple speech generation tasks, generating expressive and high-fidelity speech. Specifically, we propose a novel speech codec based on speech vectors and semantic tokens. Speech vectors contain acoustic details contributing to high-fidelity speech reconstruction, while semantic tokens focus on the linguistic content of speech, facilitating language modeling. Based on the proposed speech codec, Vec-Tok Speech leverages an LM to undertake the core of speech generation. Moreover, Byte-Pair Encoding (BPE) is introduced to reduce the token length and bit rate for lower exposure bias and longer context coverage, improving the performance of LMs. Vec-Tok Speech can be used for intra- and cross-lingual zero-shot voice conversion (VC), zero-shot speaking style transfer text-to-speech (TTS), speech-to-speech translation (S2ST), speech denoising, and speaker de-identification and anonymization. Experiments show that Vec-Tok Speech, built on 50k hours of speech, performs better than other SOTA models. Code will be available at https://github.com/BakerBunker/VecTok .
Improving Cross-lingual Speech Synthesis with Triplet Training Scheme
Feb 22, 2022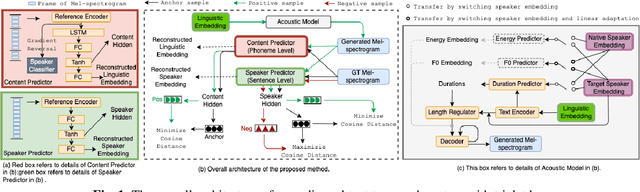
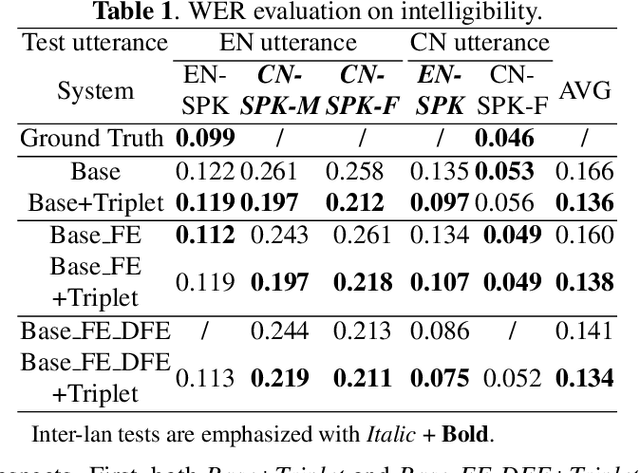
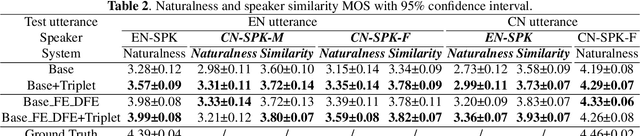
Recent advances in cross-lingual text-to-speech (TTS) made it possible to synthesize speech in a language foreign to a monolingual speaker. However, there is still a large gap between the pronunciation of generated cross-lingual speech and that of native speakers in terms of naturalness and intelligibility. In this paper, a triplet training scheme is proposed to enhance the cross-lingual pronunciation by allowing previously unseen content and speaker combinations to be seen during training. Proposed method introduces an extra fine-tune stage with triplet loss during training, which efficiently draws the pronunciation of the synthesized foreign speech closer to those from the native anchor speaker, while preserving the non-native speaker's timbre. Experiments are conducted based on a state-of-the-art baseline cross-lingual TTS system and its enhanced variants. All the objective and subjective evaluations show the proposed method brings significant improvement in both intelligibility and naturalness of the synthesized cross-lingual speech.