 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Cross-lingual Speech Synthesis with Triplet Training Scheme
Paper and Code
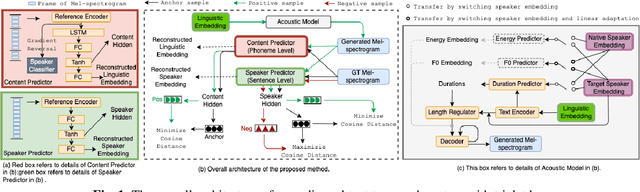
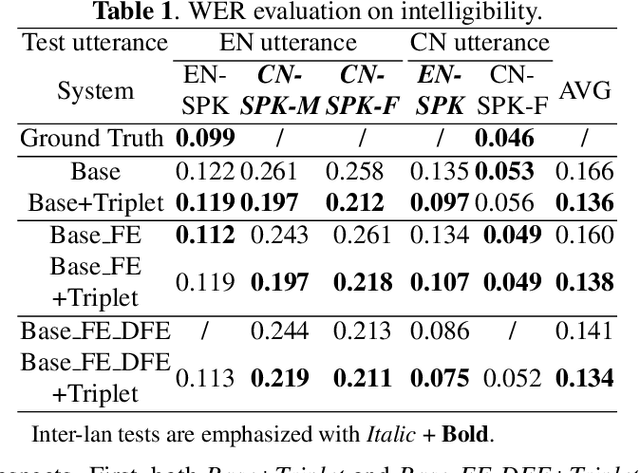
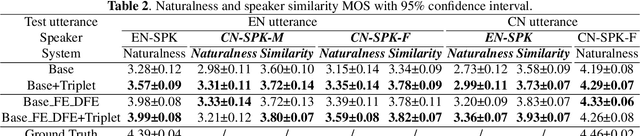
Recent advances in cross-lingual text-to-speech (TTS) made it possible to synthesize speech in a language foreign to a monolingual speaker. However, there is still a large gap between the pronunciation of generated cross-lingual speech and that of native speakers in terms of naturalness and intelligibility. In this paper, a triplet training scheme is proposed to enhance the cross-lingual pronunciation by allowing previously unseen content and speaker combinations to be seen during training. Proposed method introduces an extra fine-tune stage with triplet loss during training, which efficiently draws the pronunciation of the synthesized foreign speech closer to those from the native anchor speaker, while preserving the non-native speaker's timbre. Experiments are conducted based on a state-of-the-art baseline cross-lingual TTS system and its enhanced variants. All the objective and subjective evaluations show the proposed method brings significant improvement in both intelligibility and naturalness of the synthesized cross-lingual speech.