 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentify Critical KV Cache in LLM Inference from an Output Perturbation Perspective
Paper and Code
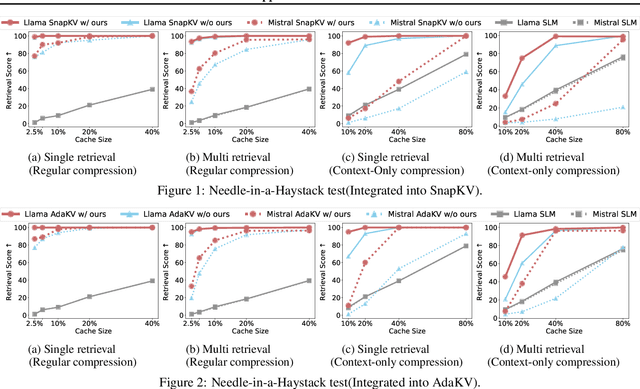
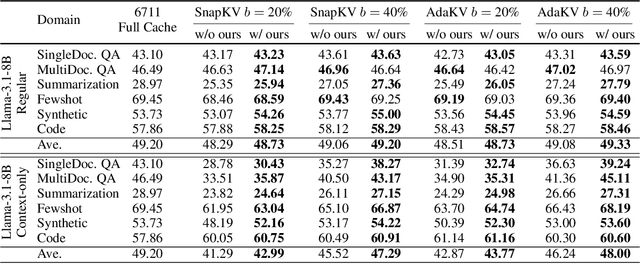
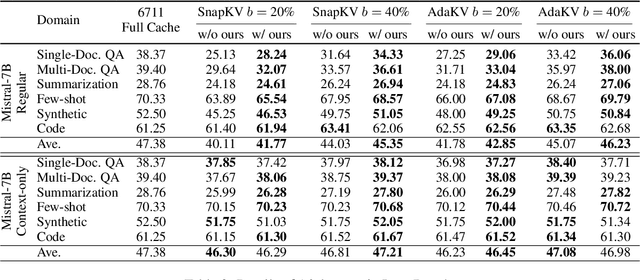
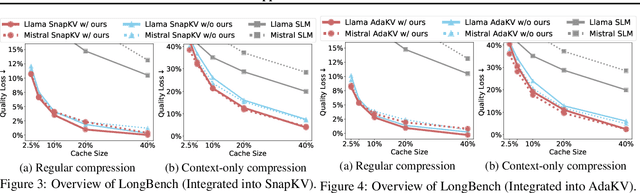
Large language models have revolutionized natural language processing but face significant challenges of high storage and runtime costs, due to the transformer architecture's reliance on self-attention, particularly the large Key-Value (KV) cache for long-sequence inference. Recent efforts to reduce KV cache size by pruning less critical entries based on attention weights remain empirical and lack formal grounding. This paper presents a formal study on identifying critical KV cache entries by analyzing attention output perturbation. Our analysis reveals that, beyond attention weights, the value states within KV entries and pretrained parameter matrices are also crucial. Based on this, we propose a perturbation-constrained selection algorithm that optimizes the worst-case output perturbation to identify critical entries. Evaluations on the Needle-in-a-Haystack test and Longbench benchmark show our algorithm enhances state-of-the-art cache eviction methods. Further empirical analysis confirms that our algorithm achieves lower output perturbations in over 92% attention heads in Llama model, thereby providing a significant improvement over existing methods.