 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior evolution-inspired approach to walking gait reinforcement training for quadruped robots
Sep 25, 2024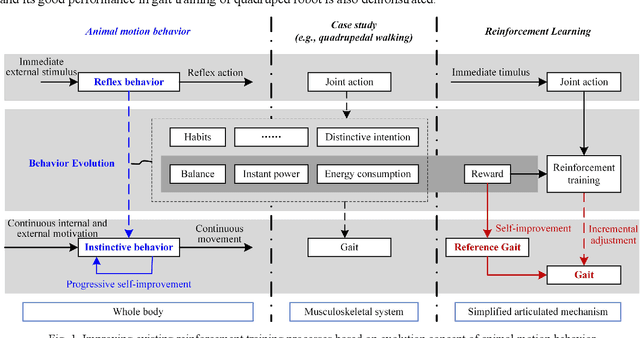



Reinforcement learning method is extremely competitive in gait generation techniques for quadrupedal robot, which is mainly due to the fact that stochastic exploration in reinforcement training is beneficial to achieve an autonomous gait. Nevertheless, although incremental reinforcement learning is employed to improve training success and movement smoothness by relying on the continuity inherent during limb movements, challenges remain in adapting gait policy to diverse terrain and external disturbance. Inspired by the association between reinforcement learning and the evolution of animal motion behavior, a self-improvement mechanism for reference gait is introduced in this paper to enable incremental learning of action and self-improvement of reference action together to imitate the evolution of animal motion behavior. Further, a new framework for reinforcement training of quadruped gait is proposed. In this framework, genetic algorithm is specifically adopted to perform global probabilistic search for the initial value of the arbitrary foot trajectory to update the reference trajectory with better fitness. Subsequently, the improved reference gait is used for incremental reinforcement learning of gait. The above process is repeatedly and alternatively executed to finally train the gait policy. The analysis considering terrain, model dimensions, and locomotion condition is presented in detail based on simulation, and the results show that the framework is significantly more adaptive to terrain compared to regular incremental reinforcement learning.
Incremental Reinforcement Learning --- a New Continuous Reinforcement Learning Frame Based on Stochastic Differential Equation methods
Aug 08, 2019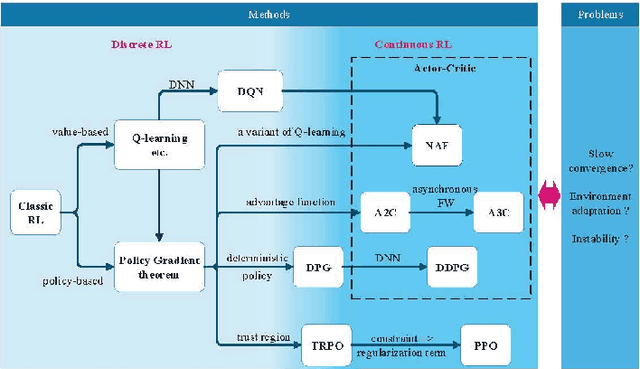
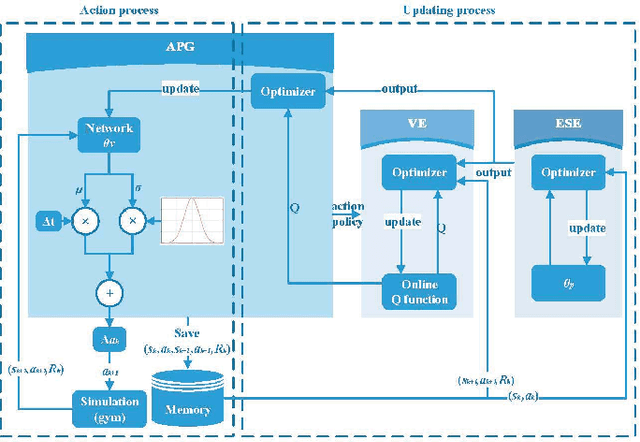
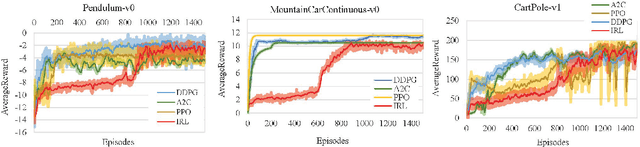
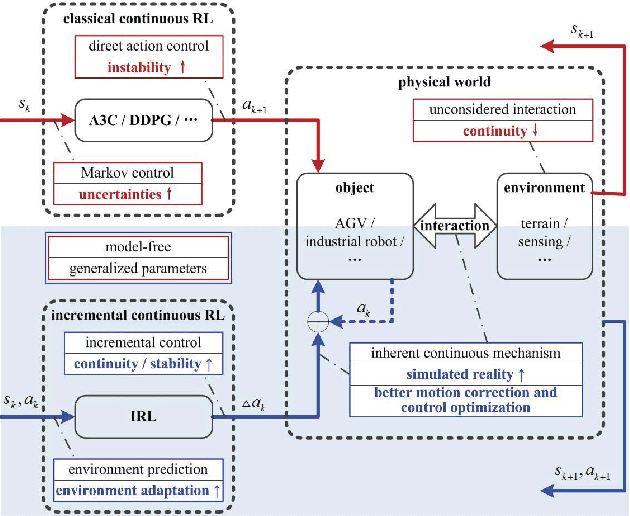
Continuous reinforcement learning such as DDPG and A3C are widely used in robot control and autonomous driving. However, both methods have theoretical weaknesses. While DDPG cannot control noises in the control process, A3C does not satisfy the continuity conditions under the Gaussian policy. To address these concerns, we propose a new continues reinforcement learning method based on stochastic differential equations and we call it Incremental Reinforcement Learning (IRL). This method not only guarantees the continuity of actions within any time interval, but controls the variance of actions in the training process. In addition, our method does not assume Markov control in agents' action control and allows agents to predict scene changes for action selection. With our method, agents no longer passively adapt to the environment. Instead, they positively interact with the environment for maximum rewards.