 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Vehicle Detection using DETR: A Transformer-Based Approach for Navigating Treacherous Roads
Feb 25, 2025Automatic Vehicle Detection (AVD) in diverse driving environments presents unique challenges due to varying lighting conditions, road types, and vehicle types. Traditional methods, such as YOLO and Faster R-CNN, often struggle to cope with these complexities. As computer vision evolves, combining Convolutional Neural Networks (CNNs) with Transformer-based approaches offers promising opportunities for improving detection accuracy and efficiency. This study is the first to experiment with Detection Transformer (DETR) for automatic vehicle detection in complex and varied settings. We employ a Collaborative Hybrid Assignments Training scheme, Co-DETR, to enhance feature learning and attention mechanisms in DETR. By leveraging versatile label assignment strategies and introducing multiple parallel auxiliary heads, we provide more effective supervision during training and extract positive coordinates to boost training efficiency. Through extensive experiments on DETR variants and YOLO models, conducted using the BadODD dataset, we demonstrate the advantages of our approach. Our method achieves superior results, and improved accuracy in diverse conditions, making it practical for real-world deployment. This work significantly advances autonomous navigation technology and opens new research avenues in object detection for autonomous vehicles. By integrating the strengths of CNNs and Transformers, we highlight the potential of DETR for robust and efficient vehicle detection in challenging driving environments.
A Post-Processing Based Bengali Document Layout Analysis with YOLOV8
Sep 02, 2023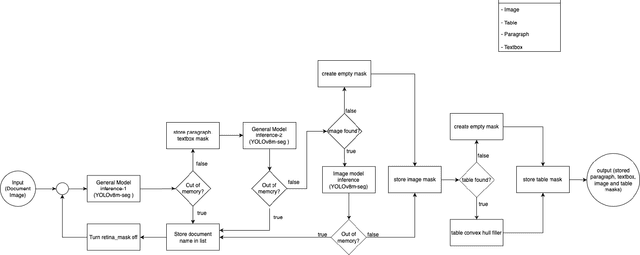


This paper focuses on enhancing Bengali Document Layout Analysis (DLA) using the YOLOv8 model and innovative post-processing techniques. We tackle challenges unique to the complex Bengali script by employing data augmentation for model robustness. After meticulous validation set evaluation, we fine-tune our approach on the complete dataset, leading to a two-stage prediction strategy for accurate element segmentation. Our ensemble model, combined with post-processing, outperforms individual base architectures, addressing issues identified in the BaDLAD dataset. By leveraging this approach, we aim to advance Bengali document analysis, contributing to improved OCR and document comprehension and BaDLAD serves as a foundational resource for this endeavor, aiding future research in the field. Furthermore, our experiments provided key insights to incorporate new strategies into the established solution.