 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multimodal Accuracy Through Modality Pre-training and Attention
Nov 11, 2020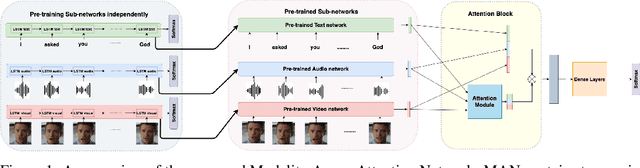
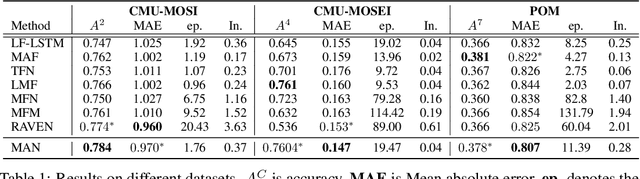
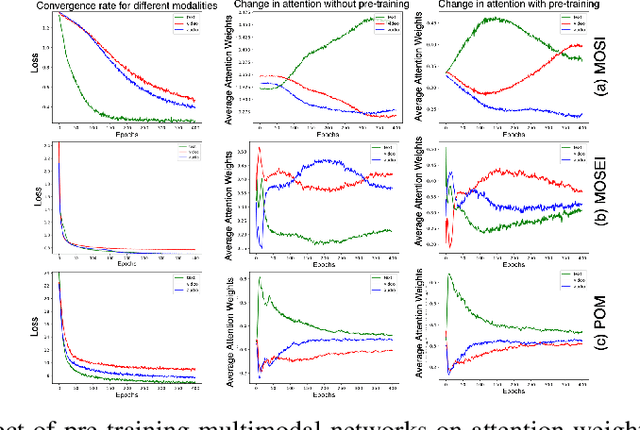

Training a multimodal network is challenging and it requires complex architectures to achieve reasonable performance. We show that one reason for this phenomena is the difference between the convergence rate of various modalities. We address this by pre-training modality-specific sub-networks in multimodal architectures independently before end-to-end training of the entire network. Furthermore, we show that the addition of an attention mechanism between sub-networks after pre-training helps identify the most important modality during ambiguous scenarios boosting the performance. We demonstrate that by performing these two tricks a simple network can achieve similar performance to a complicated architecture that is significantly more expensive to train on multiple tasks including sentiment analysis, emotion recognition, and speaker trait recognition.