 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiL-Bench (Human-in-Loop Benchmark): Do Agents Know When to Ask for Help?
Apr 13, 2026Frontier coding agents solve complex tasks when given complete context but collapse when specifications are incomplete or ambiguous. The bottleneck is not raw capability, but judgment: knowing when to act autonomously and when to ask for help. Current benchmarks are blind to this failure mode. They supply unambiguous detailed instructions and solely reward execution correctness, so an agent that makes a lucky guess for a missing requirement will score identically to one that would have asked to be certain. We present HiL-Bench (Human-in-the-Loop Benchmark) to measure this selective escalation skill. Each task contains human-validated blockers (missing information, ambiguous requests, contradictory information) that surface only through progressive exploration, not upfront inspection. Our core metric, Ask-F1, the harmonic mean of question precision and blocker recall, captures the tension between over-asking and silent guessing; its structure architecturally prevents gaming through question spam. Evaluation across SWE and text-to-SQL domains reveals a large universal judgment gap: no frontier model recovers more than a fraction of its full-information performance when deciding whether to ask. Failure analysis identifies three key help-seeking patterns: overconfident wrong beliefs with no gap detection; high uncertainty detection yet persistent errors; broad, imprecise escalation without self-correction. These consistent patterns confirm poor help-seeking is a model-level flaw, not task-specific. RL training on shaped Ask-F1 reward shows judgment is trainable: a 32B model improves both help-seeking quality and task pass rate, with gains that transfer across domains. The model does not learn domain-specific heuristics for when to ask; it learns to detect unresolvable uncertainty and act on it.
Verifiably Safe Exploration for End-to-End Reinforcement Learning
Jul 02, 2020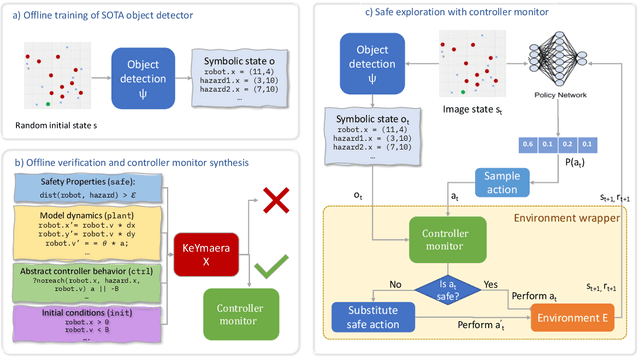
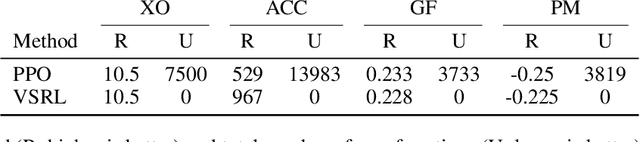
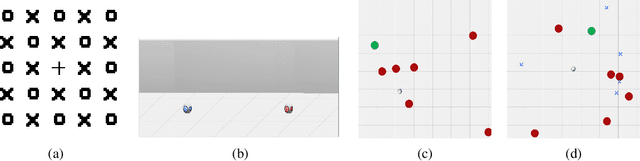

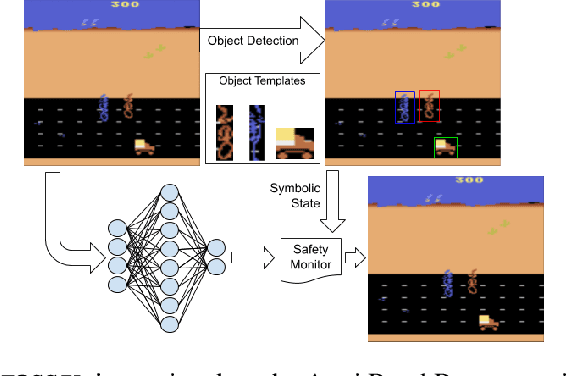
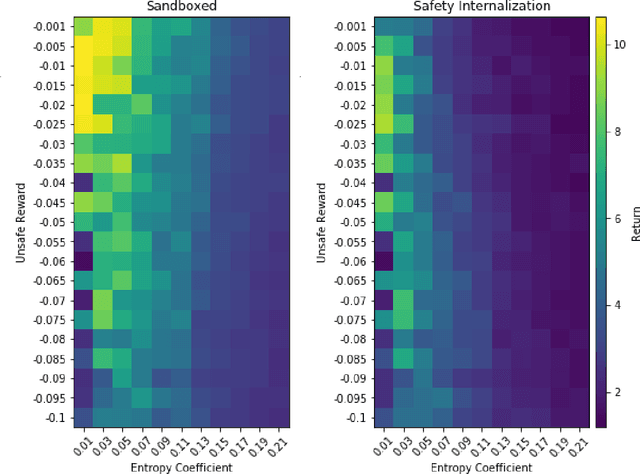
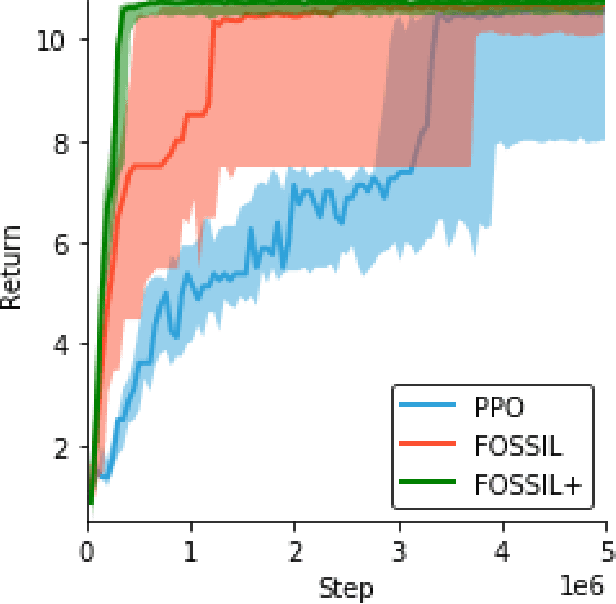
Deploying deep reinforcement learning in safety-critical settings requires developing algorithms that obey hard constraints during exploration. This paper contributes a first approach toward enforcing formal safety constraints on end-to-end policies with visual inputs. Our approach draws on recent advances in object detection and automated reasoning for hybrid dynamical systems. The approach is evaluated on a novel benchmark that emphasizes the challenge of safely exploring in the presence of hard constraints. Our benchmark draws from several proposed problem sets for safe learning and includes problems that emphasize challenges such as reward signals that are not aligned with safety constraints. On each of these benchmark problems, our algorithm completely avoids unsafe behavior while remaining competitive at optimizing for as much reward as is safe. We also prove that our method of enforcing the safety constraints preserves all safe policies from the original environment.
Formal Verification of End-to-End Learning in Cyber-Physical Systems: Progress and Challenges
Jun 15, 2020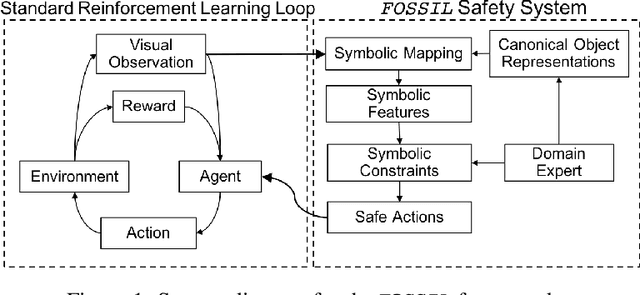
Autonomous systems -- such as self-driving cars, autonomous drones, and automated trains -- must come with strong safety guarantees. Over the past decade, techniques based on formal methods have enjoyed some success in providing strong correctness guarantees for large software systems including operating system kernels, cryptographic protocols, and control software for drones. These successes suggest it might be possible to ensure the safety of autonomous systems by constructing formal, computer-checked correctness proofs. This paper identifies three assumptions underlying existing formal verification techniques, explains how each of these assumptions limits the applicability of verification in autonomous systems, and summarizes preliminary work toward improving the strength of evidence provided by formal verification.
Clinical Intervention Prediction and Understanding using Deep Networks
May 23, 2017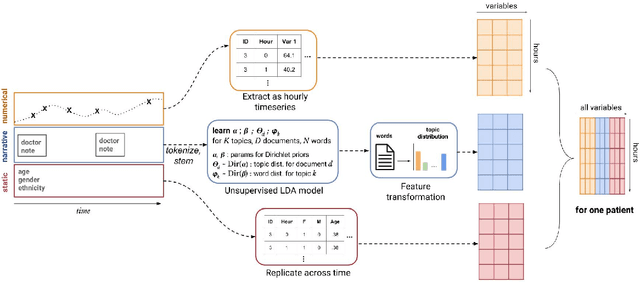
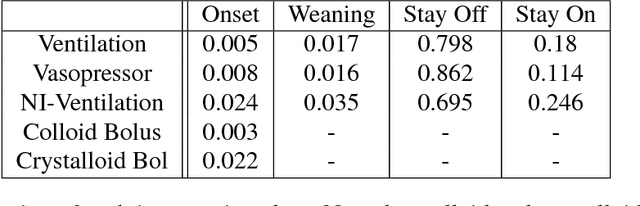
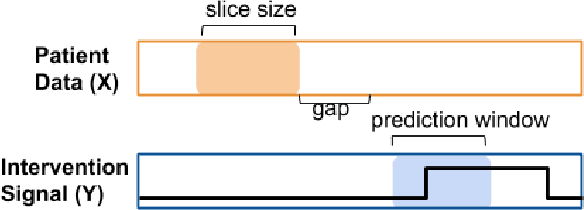
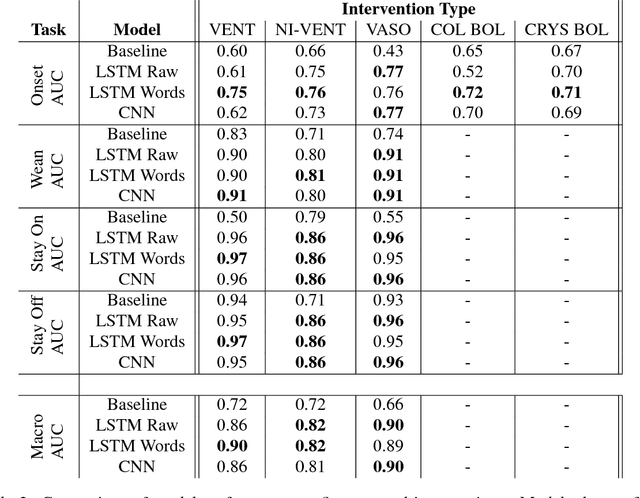
Real-time prediction of clinical interventions remains a challenge within intensive care units (ICUs). This task is complicated by data sources that are noisy, sparse, heterogeneous and outcomes that are imbalanced. In this paper, we integrate data from all available ICU sources (vitals, labs, notes, demographics) and focus on learning rich representations of this data to predict onset and weaning of multiple invasive interventions. In particular, we compare both long short-term memory networks (LSTM) and convolutional neural networks (CNN) for prediction of five intervention tasks: invasive ventilation, non-invasive ventilation, vasopressors, colloid boluses, and crystalloid boluses. Our predictions are done in a forward-facing manner to enable "real-time" performance, and predictions are made with a six hour gap time to support clinically actionable planning. We achieve state-of-the-art results on our predictive tasks using deep architectures. We explore the use of feature occlusion to interpret LSTM models, and compare this to the interpretability gained from examining inputs that maximally activate CNN outputs. We show that our models are able to significantly outperform baselines in intervention prediction, and provide insight into model learning, which is crucial for the adoption of such models in practice.