 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinqi: A System for 6D Localization and SLAM Augmentation Using Wideangle Optics and Coded Light Beacons
Aug 21, 2017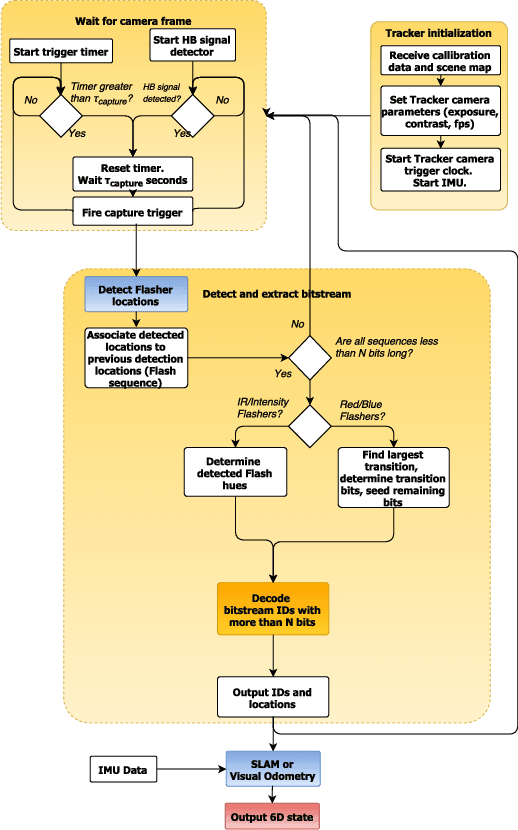
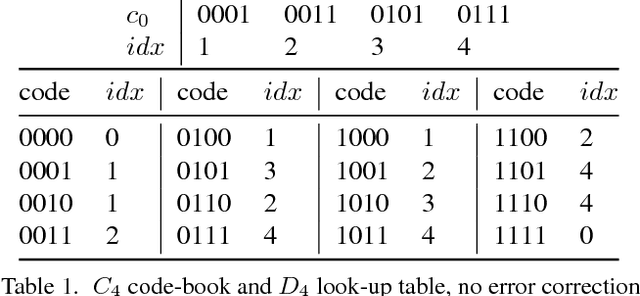
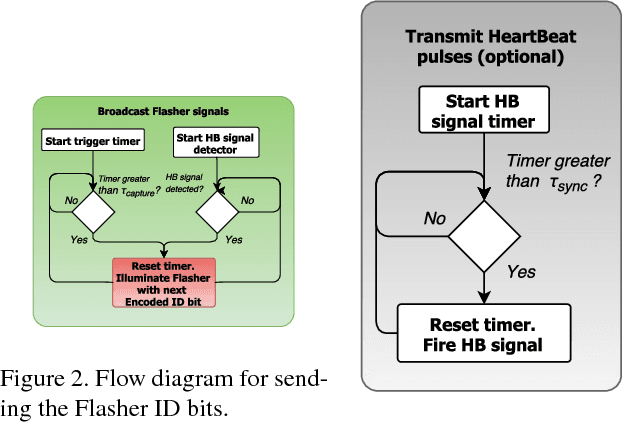

Simultaneous Localization and Mapping (SLAM) systems use commodity visible/near visible digital sensors coupled with processing units that detect, recognize and track image points in a camera stream. These systems are cheap, fast and make use of readily available camera technologies. However, SLAM systems suffer from issues of drift as well as sensitivity to lighting variation such as shadows and changing brightness. Beaconless SLAM systems will continue to suffer from this inherent drift problem irrespective of the improvements in on-board camera resolution, speed and inertial sensor precision. To cancel out destructive forms of drift, relocalization algorithms are used which use known detected landmarks together with loop closure processes to continually readjust the current location and orientation estimates to match "known" positions. However this is inherently problematic because these landmarks themselves may have been recorded with errors and they may also change under different illumination conditions. In this note we describe a unique beacon light coding system which is robust to desynchronized clock bit drift. The described beacons and codes are designed to be used in industrial or consumer environments for full standalone 6dof tracking or as known error free landmarks in a SLAM pipeline.
Learning Invariant Representations Of Planar Curves
Feb 16, 2017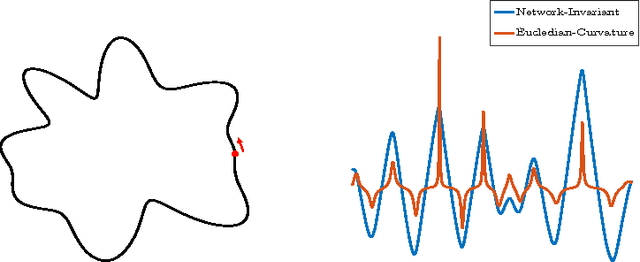
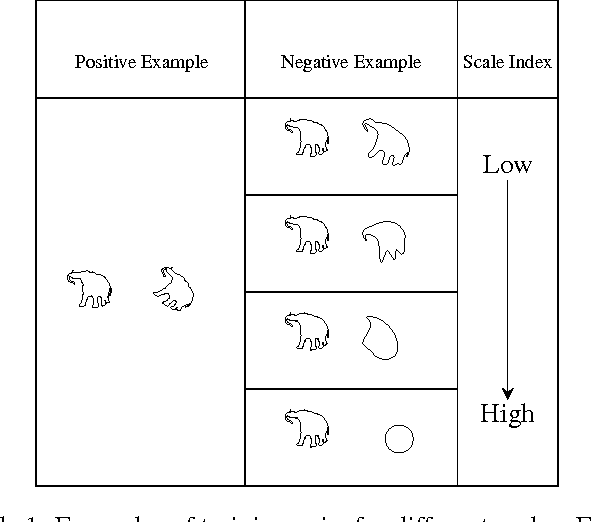
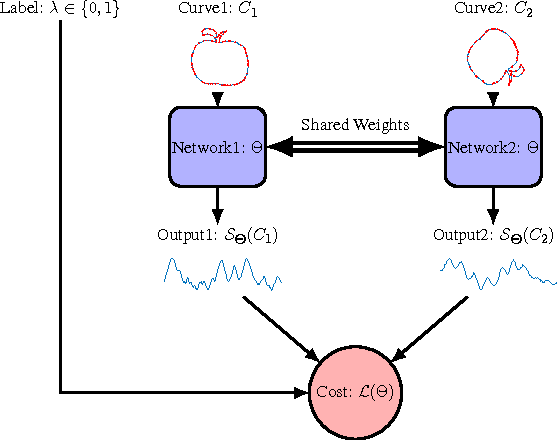
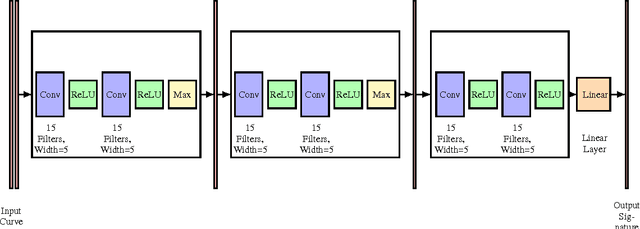
We propose a metric learning framework for the construction of invariant geometric functions of planar curves for the Eucledian and Similarity group of transformations. We leverage on the representational power of convolutional neural networks to compute these geometric quantities. In comparison with axiomatic constructions, we show that the invariants approximated by the learning architectures have better numerical qualities such as robustness to noise, resiliency to sampling, as well as the ability to adapt to occlusion and partiality. Finally, we develop a novel multi-scale representation in a similarity metric learning paradigm.
Deep Stereo Matching with Dense CRF Priors
Jan 24, 2017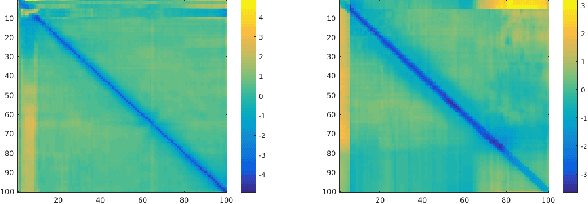
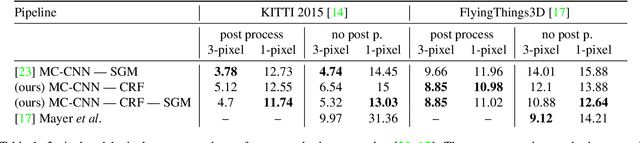
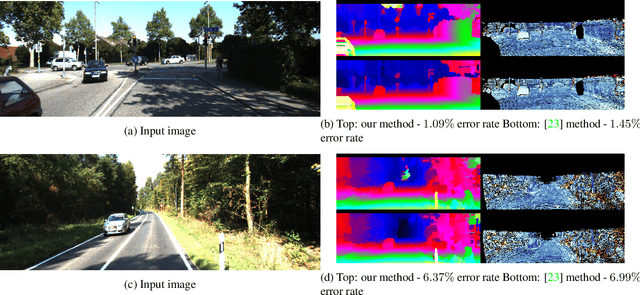
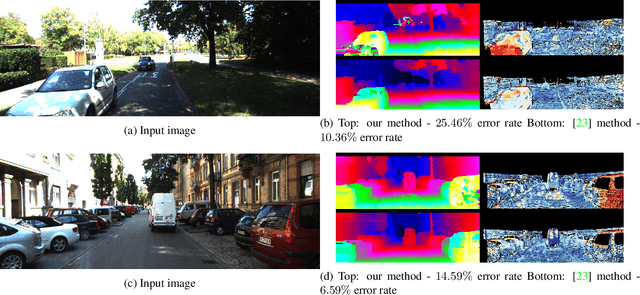
Stereo reconstruction from rectified images has recently been revisited within the context of deep learning. Using a deep Convolutional Neural Network to obtain patch-wise matching cost volumes has resulted in state of the art stereo reconstruction on classic datasets like Middlebury and Kitti. By introducing this cost into a classical stereo pipeline, the final results are improved dramatically over non-learning based cost models. However these pipelines typically include hand engineered post processing steps to effectively regularize and clean the result. Here, we show that it is possible to take a more holistic approach by training a fully end-to-end network which directly includes regularization in the form of a densely connected Conditional Random Field (CRF) that acts as a prior on inter-pixel interactions. We demonstrate that our approach on both synthetic and real world datasets outperforms an alternative end-to-end network and compares favorably to more hand engineered approaches.
Real-Time Depth Refinement for Specular Objects
Mar 30, 2016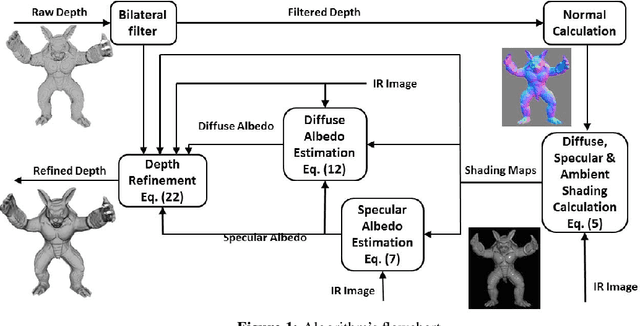
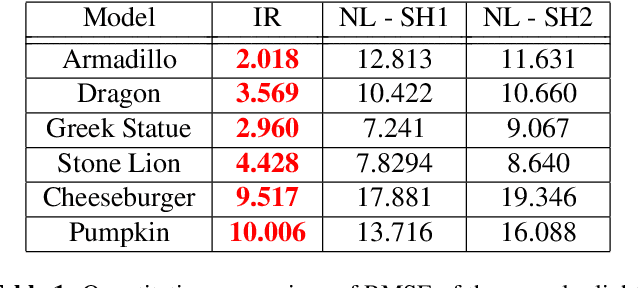
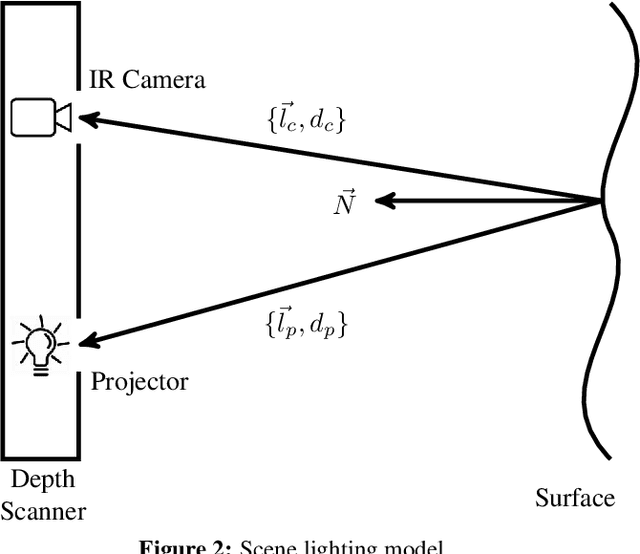
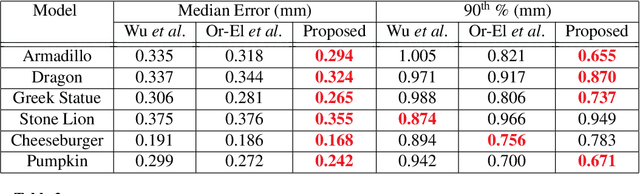
The introduction of consumer RGB-D scanners set off a major boost in 3D computer vision research. Yet, the precision of existing depth scanners is not accurate enough to recover fine details of a scanned object. While modern shading based depth refinement methods have been proven to work well with Lambertian objects, they break down in the presence of specularities. We present a novel shape from shading framework that addresses this issue and enhances both diffuse and specular objects' depth profiles. We take advantage of the built-in monochromatic IR projector and IR images of the RGB-D scanners and present a lighting model that accounts for the specular regions in the input image. Using this model, we reconstruct the depth map in real-time. Both quantitative tests and visual evaluations prove that the proposed method produces state of the art depth reconstruction results.
Rule Of Thumb: Deep derotation for improved fingertip detection
Jul 21, 2015

We investigate a novel global orientation regression approach for articulated objects using a deep convolutional neural network. This is integrated with an in-plane image derotation scheme, DeROT, to tackle the problem of per-frame fingertip detection in depth images. The method reduces the complexity of learning in the space of articulated poses which is demonstrated by using two distinct state-of-the-art learning based hand pose estimation methods applied to fingertip detection. Significant classification improvements are shown over the baseline implementation. Our framework involves no tracking, kinematic constraints or explicit prior model of the articulated object in hand. To support our approach we also describe a new pipeline for high accuracy magnetic annotation and labeling of objects imaged by a depth camera.