 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocVLM: Make Your VLM an Efficient Reader
Dec 11, 2024



Vision-Language Models (VLMs) excel in diverse visual tasks but face challenges in document understanding, which requires fine-grained text processing. While typical visual tasks perform well with low-resolution inputs, reading-intensive applications demand high-resolution, resulting in significant computational overhead. Using OCR-extracted text in VLM prompts partially addresses this issue but underperforms compared to full-resolution counterpart, as it lacks the complete visual context needed for optimal performance. We introduce DocVLM, a method that integrates an OCR-based modality into VLMs to enhance document processing while preserving original weights. Our approach employs an OCR encoder to capture textual content and layout, compressing these into a compact set of learned queries incorporated into the VLM. Comprehensive evaluations across leading VLMs show that DocVLM significantly reduces reliance on high-resolution images for document understanding. In limited-token regimes (448$\times$448), DocVLM with 64 learned queries improves DocVQA results from 56.0% to 86.6% when integrated with InternVL2 and from 84.4% to 91.2% with Qwen2-VL. In LLaVA-OneVision, DocVLM achieves improved results while using 80% less image tokens. The reduced token usage allows processing multiple pages effectively, showing impressive zero-shot results on DUDE and state-of-the-art performance on MP-DocVQA, highlighting DocVLM's potential for applications requiring high-performance and efficiency.
GRAM: Global Reasoning for Multi-Page VQA
Jan 07, 2024


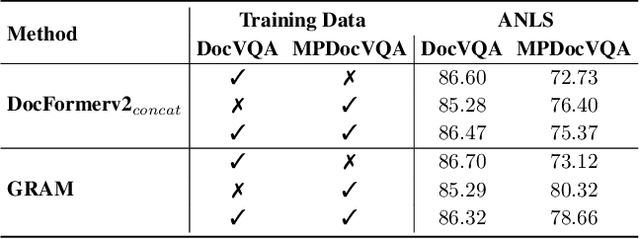
The increasing use of transformer-based large language models brings forward the challenge of processing long sequences. In document visual question answering (DocVQA), leading methods focus on the single-page setting, while documents can span hundreds of pages. We present GRAM, a method that seamlessly extends pre-trained single-page models to the multi-page setting, without requiring computationally-heavy pretraining. To do so, we leverage a single-page encoder for local page-level understanding, and enhance it with document-level designated layers and learnable tokens, facilitating the flow of information across pages for global reasoning. To enforce our model to utilize the newly introduced document-level tokens, we propose a tailored bias adaptation method. For additional computational savings during decoding, we introduce an optional compression stage using our C-Former model, which reduces the encoded sequence length, thereby allowing a tradeoff between quality and latency. Extensive experiments showcase GRAM's state-of-the-art performance on the benchmarks for multi-page DocVQA, demonstrating the effectiveness of our approach.
CLIPTER: Looking at the Bigger Picture in Scene Text Recognition
Jan 18, 2023
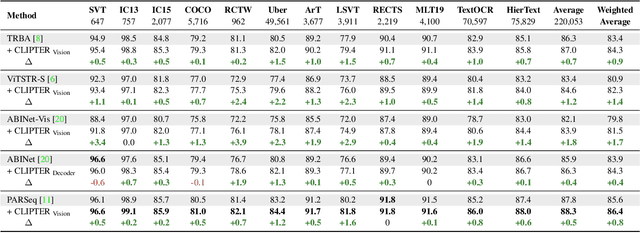
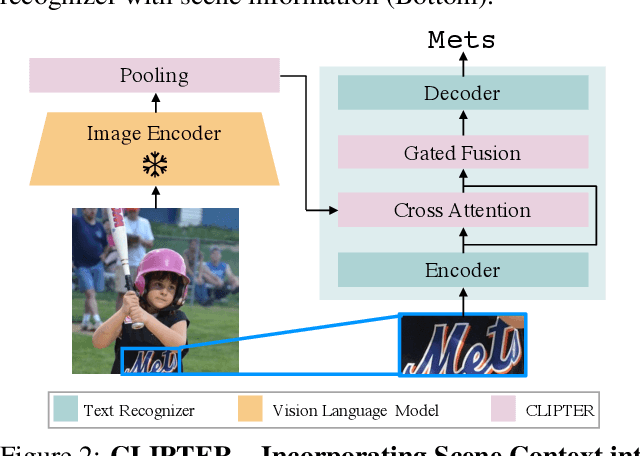

Understanding the scene is often essential for reading text in real-world scenarios. However, current scene text recognizers operate on cropped text images, unaware of the bigger picture. In this work, we harness the representative power of recent vision-language models, such as CLIP, to provide the crop-based recognizer with scene, image-level information. Specifically, we obtain a rich representation of the entire image and fuse it with the recognizer word-level features via cross-attention. Moreover, a gated mechanism is introduced that gradually shifts to the context-enriched representation, enabling simply fine-tuning a pretrained recognizer. We implement our model-agnostic framework, named CLIPTER - CLIP Text Recognition, on several leading text recognizers and demonstrate consistent performance gains, achieving state-of-the-art results over multiple benchmarks. Furthermore, an in-depth analysis reveals improved robustness to out-of-vocabulary words and enhanced generalization in low-data regimes.
Ada-LISTA: Learned Solvers Adaptive to Varying Models
Feb 19, 2020

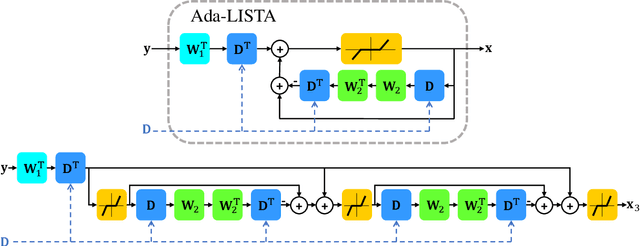
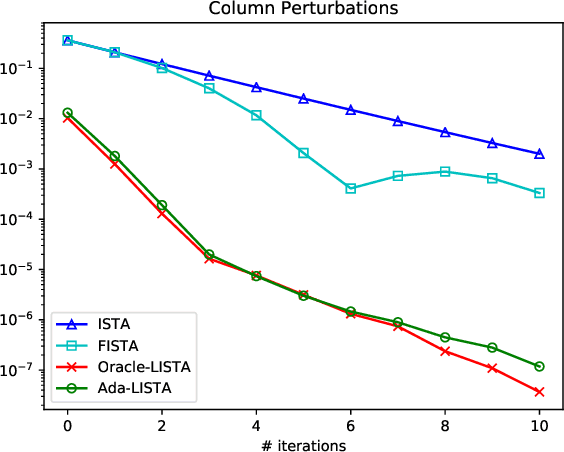
Neural networks that are based on unfolding of an iterative solver, such as LISTA (learned iterative soft threshold algorithm), are widely used due to their accelerated performance. Nevertheless, as opposed to non-learned solvers, these networks are trained on a certain dictionary, and therefore they are inapplicable for varying model scenarios. This work introduces an adaptive learned solver, termed Ada-LISTA, which receives pairs of signals and their corresponding dictionaries as inputs, and learns a universal architecture to serve them all. We prove that this scheme is guaranteed to solve sparse coding in linear rate for varying models, including dictionary perturbations and permutations. We also provide an extensive numerical study demonstrating its practical adaptation capabilities. Finally, we deploy Ada-LISTA to natural image inpainting, where the patch-masks vary spatially, thus requiring such an adaptation.
Unsupervised Single Image Dehazing Using Dark Channel Prior Loss
Dec 06, 2018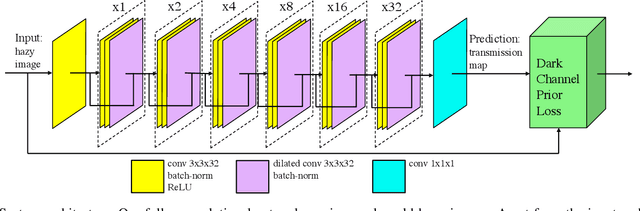
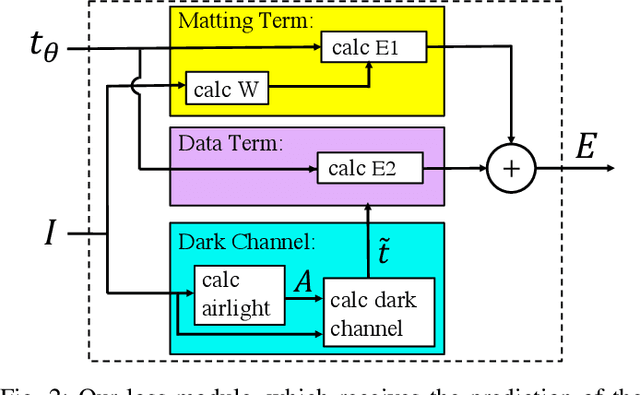


Single image dehazing is a critical stage in many modern-day autonomous vision applications. Early prior-based methods often involved a time-consuming minimization of a hand-crafted energy function. Recent learning-based approaches utilize the representational power of deep neural networks (DNNs) to learn the underlying transformation between hazy and clear images. Due to inherent limitations in collecting matching clear and hazy images, these methods resort to training on synthetic data; constructed from indoor images and corresponding depth information. This may result in a possible domain shift when treating outdoor scenes. We propose a completely unsupervised method of training via minimization of the well-known, Dark Channel Prior (DCP) energy function. Instead of feeding the network with synthetic data, we solely use real-world outdoor images and tune the network's parameters by directly minimizing the DCP. Although our `Deep DCP' technique can be regarded as a fast approximator of DCP, it actually improves its results significantly. This suggests an additional regularization obtained via the network and learning process. Experiments show that our method performs on par with other large-scale, supervised methods.
Deep Energy: Using Energy Functions for Unsupervised Training of DNNs
May 31, 2018
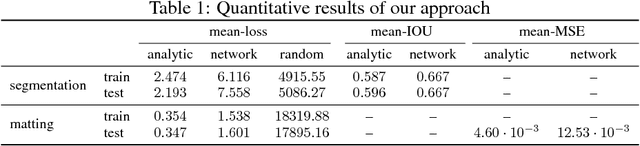


The success of deep learning has been due in no small part to the availability of large annotated datasets. Thus, a major bottleneck in the current learning pipeline is the human annotation of data, which can be quite time consuming. For a given problem setting, we aim to circumvent this issue via the use of an externally specified energy function appropriate for that setting; we call this the "Deep Energy" approach. We show how to train a network on an entirely unlabelled dataset using such an energy function, and apply this general technique to learn CNNs for two specific tasks: seeded segmentation and image matting. Once the network parameters have been learned, we obtain a high-quality solution in a fast feed-forward style, without the need to repeatedly optimize the energy function for each image.
Linearized Kernel Dictionary Learning
Sep 18, 2015
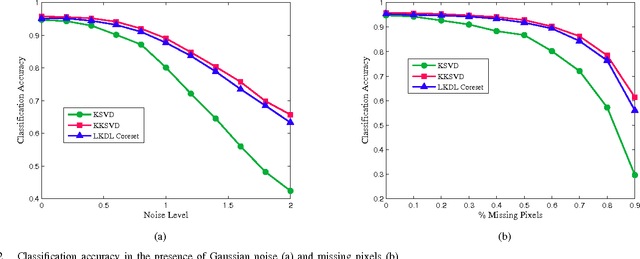
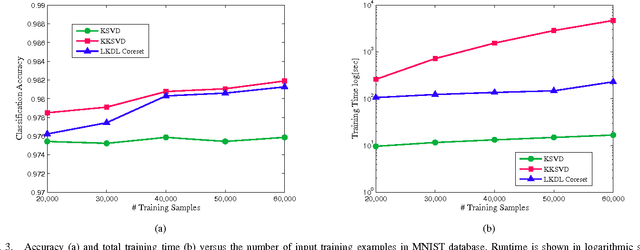
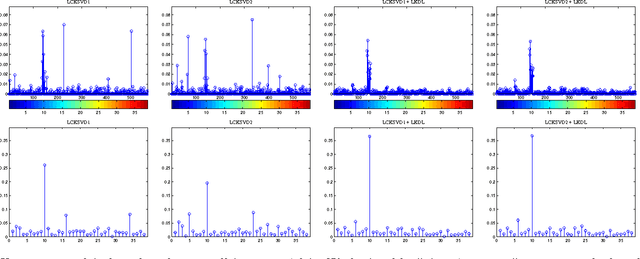
In this paper we present a new approach of incorporating kernels into dictionary learning. The kernel K-SVD algorithm (KKSVD), which has been introduced recently, shows an improvement in classification performance, with relation to its linear counterpart K-SVD. However, this algorithm requires the storage and handling of a very large kernel matrix, which leads to high computational cost, while also limiting its use to setups with small number of training examples. We address these problems by combining two ideas: first we approximate the kernel matrix using a cleverly sampled subset of its columns using the Nystr\"{o}m method; secondly, as we wish to avoid using this matrix altogether, we decompose it by SVD to form new "virtual samples," on which any linear dictionary learning can be employed. Our method, termed "Linearized Kernel Dictionary Learning" (LKDL) can be seamlessly applied as a pre-processing stage on top of any efficient off-the-shelf dictionary learning scheme, effectively "kernelizing" it. We demonstrate the effectiveness of our method on several tasks of both supervised and unsupervised classification and show the efficiency of the proposed scheme, its easy integration and performance boosting properties.