 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinearized Kernel Dictionary Learning
Paper and Code

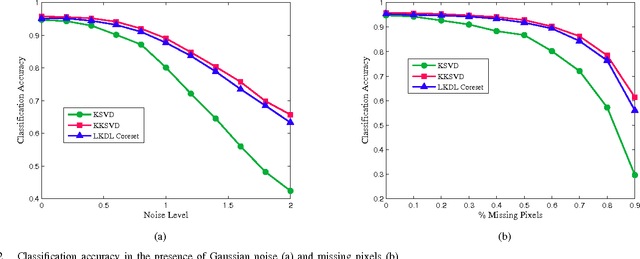
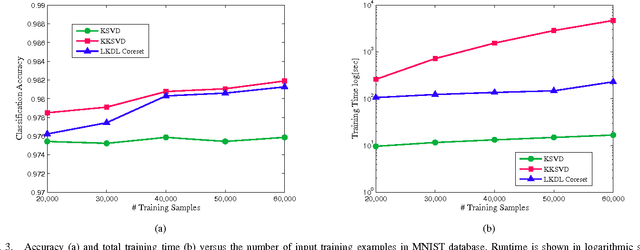
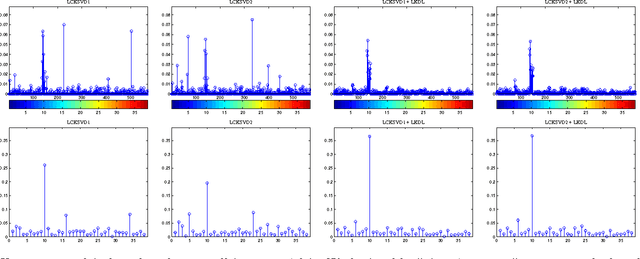
In this paper we present a new approach of incorporating kernels into dictionary learning. The kernel K-SVD algorithm (KKSVD), which has been introduced recently, shows an improvement in classification performance, with relation to its linear counterpart K-SVD. However, this algorithm requires the storage and handling of a very large kernel matrix, which leads to high computational cost, while also limiting its use to setups with small number of training examples. We address these problems by combining two ideas: first we approximate the kernel matrix using a cleverly sampled subset of its columns using the Nystr\"{o}m method; secondly, as we wish to avoid using this matrix altogether, we decompose it by SVD to form new "virtual samples," on which any linear dictionary learning can be employed. Our method, termed "Linearized Kernel Dictionary Learning" (LKDL) can be seamlessly applied as a pre-processing stage on top of any efficient off-the-shelf dictionary learning scheme, effectively "kernelizing" it. We demonstrate the effectiveness of our method on several tasks of both supervised and unsupervised classification and show the efficiency of the proposed scheme, its easy integration and performance boosting properties.