 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPTER: Looking at the Bigger Picture in Scene Text Recognition
Paper and Code

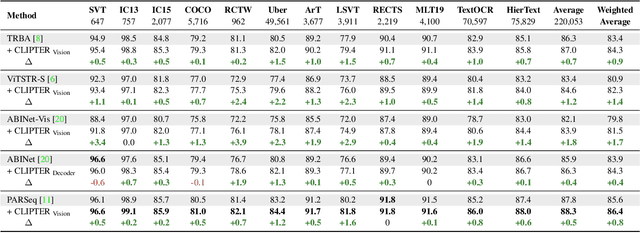
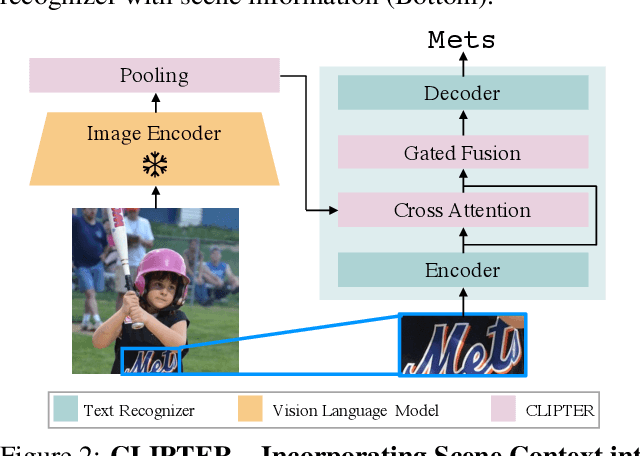

Understanding the scene is often essential for reading text in real-world scenarios. However, current scene text recognizers operate on cropped text images, unaware of the bigger picture. In this work, we harness the representative power of recent vision-language models, such as CLIP, to provide the crop-based recognizer with scene, image-level information. Specifically, we obtain a rich representation of the entire image and fuse it with the recognizer word-level features via cross-attention. Moreover, a gated mechanism is introduced that gradually shifts to the context-enriched representation, enabling simply fine-tuning a pretrained recognizer. We implement our model-agnostic framework, named CLIPTER - CLIP Text Recognition, on several leading text recognizers and demonstrate consistent performance gains, achieving state-of-the-art results over multiple benchmarks. Furthermore, an in-depth analysis reveals improved robustness to out-of-vocabulary words and enhanced generalization in low-data regimes.