 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Robustness of Natural Language Processing Models to Domain Shifts
May 31, 2023



Large Language Models have shown promising performance on various tasks, including fine-tuning, few-shot learning, and zero-shot learning. However, their performance on domains without labeled data still lags behind those with labeled data, which we refer as the Domain Robustness (DR) challenge. Existing research on DR suffers from disparate setups, lack of evaluation task variety, and reliance on challenge sets. In this paper, we explore the DR challenge of both fine-tuned and few-shot learning models in natural domain shift settings. We introduce a DR benchmark comprising diverse NLP tasks, including sentence and token-level classification, QA, and generation, each task consists of several domains. We propose two views of the DR challenge: Source Drop (SD) and Target Drop (TD), which alternate between the source and target in-domain performance as reference points. We find that in significant proportions of domain shifts, either SD or TD is positive, but not both, emphasizing the importance of considering both measures as diagnostic tools. Our experimental results demonstrate the persistent existence of the DR challenge in both fine-tuning and few-shot learning models, though it is less pronounced in the latter. We also find that increasing the fine-tuned model size improves performance, particularly in classification.
On the Robustness of Dialogue History Representation in Conversational Question Answering: A Comprehensive Study and a New Prompt-based Method
Jun 29, 2022
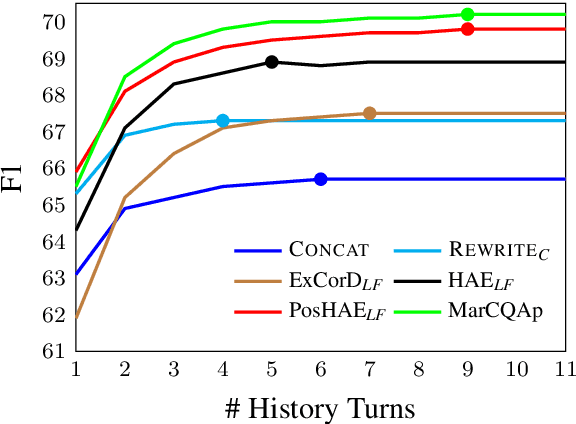
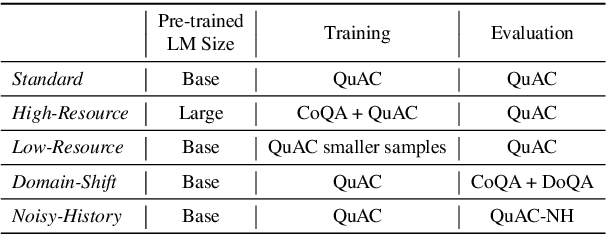
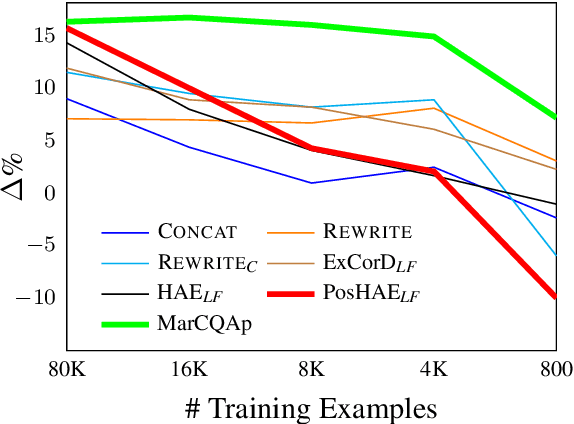
Most works on modeling the conversation history in Conversational Question Answering (CQA) report a single main result on a common CQA benchmark. While existing models show impressive results on CQA leaderboards, it remains unclear whether they are robust to shifts in setting (sometimes to more realistic ones), training data size (e.g. from large to small sets) and domain. In this work, we design and conduct the first large-scale robustness study of history modeling approaches for CQA. We find that high benchmark scores do not necessarily translate to strong robustness, and that various methods can perform extremely differently under different settings. Equipped with the insights from our study, we design a novel prompt-based history modeling approach, and demonstrate its strong robustness across various settings. Our approach is inspired by existing methods that highlight historic answers in the passage. However, instead of highlighting by modifying the passage token embeddings, we add textual prompts directly in the passage text. Our approach is simple, easy-to-plug into practically any model, and highly effective, thus we recommend it as a starting point for future model developers. We also hope that our study and insights will raise awareness to the importance of robustness-focused evaluation, in addition to obtaining high leaderboard scores, leading to better CQA systems.
PADA: A Prompt-based Autoregressive Approach for Adaptation to Unseen Domains
Feb 24, 2021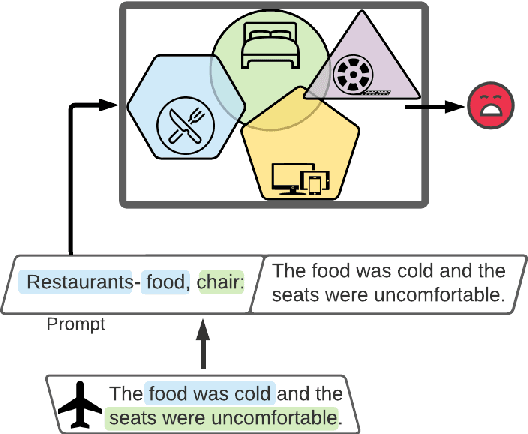
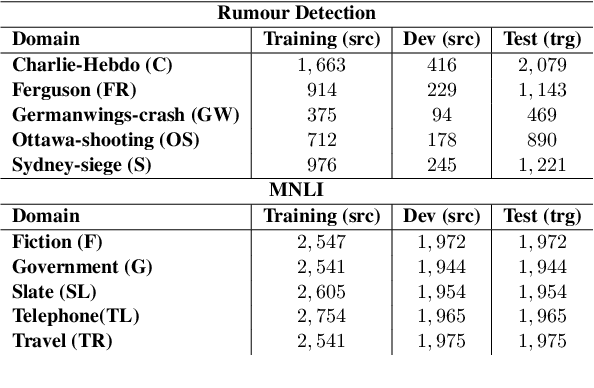
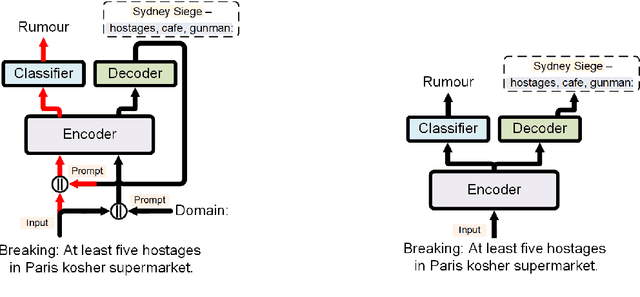
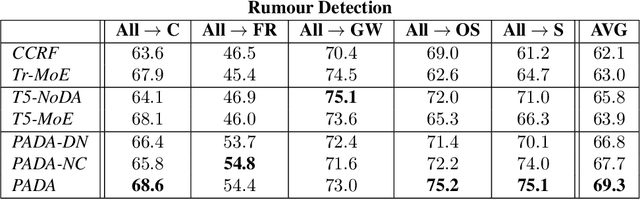
Natural Language Processing algorithms have made incredible progress recently, but they still struggle when applied to out-of-distribution examples. In this paper, we address a very challenging and previously underexplored version of this domain adaptation problem. In our setup an algorithm is trained on several source domains, and then applied to examples from an unseen domain that is unknown at training time. Particularly, no examples, labeled or unlabeled, or any other knowledge about the target domain are available to the algorithm at training time. We present PADA: A Prompt-based Autoregressive Domain Adaptation algorithm, based on the T5 model. Given a test example, PADA first generates a unique prompt and then, conditioned on this prompt, labels the example with respect to the NLP task. The prompt is a sequence of unrestricted length, consisting of pre-defined Domain Related Features (DRFs) that characterize each of the source domains. Intuitively, the prompt is a unique signature that maps the test example to the semantic space spanned by the source domains. In experiments with two tasks: Rumour Detection and Multi-Genre Natural Language Inference (MNLI), for a total of 10 multi-source adaptation scenarios, PADA strongly outperforms state-of-the-art approaches and additional strong baselines.
CausaLM: Causal Model Explanation Through Counterfactual Language Models
Jun 14, 2020
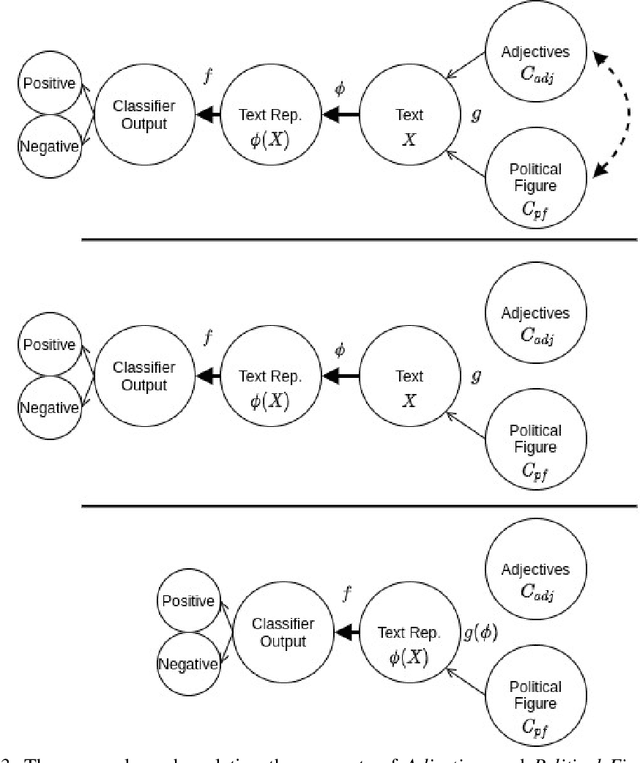

Understanding predictions made by deep neural networks is notoriously difficult, but also crucial to their dissemination. As all ML-based methods, they are as good as their training data, and can also capture unwanted biases. While there are tools that can help understand whether such biases exist, they do not distinguish between correlation and causation, and might be ill-suited for text-based models and for reasoning about high level language concepts. A key problem of estimating the causal effect of a concept of interest on a given model is that this estimation requires the generation of counterfactual examples, which is challenging with existing generation technology. To bridge that gap, we propose CausaLM, a framework for producing causal model explanations using counterfactual language representation models. Our approach is based on fine-tuning of deep contextualized embedding models with auxiliary adversarial tasks derived from the causal graph of the problem. Concretely, we show that by carefully choosing auxiliary adversarial pre-training tasks, language representation models such as BERT can effectively learn a counterfactual representation for a given concept of interest, and be used to estimate its true causal effect on model performance. A byproduct of our method is a language representation model that is unaffected by the tested concept, which can be useful in mitigating unwanted bias ingrained in the data.
Bidding in Spades
Feb 10, 2020


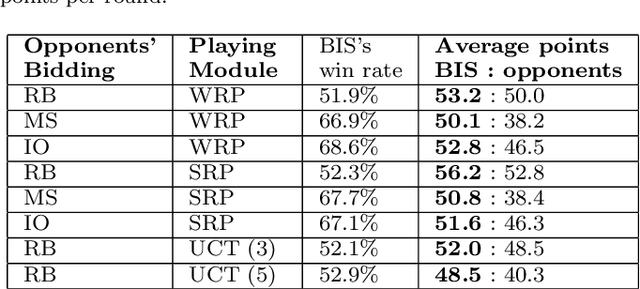
We present a Spades bidding algorithm that is superior to recreational human players and to publicly available bots. Like in Bridge, the game of Spades is composed of two independent phases, \textit{bidding} and \textit{playing}. This paper focuses on the bidding algorithm, since this phase holds a precise challenge: based on the input, choose the bid that maximizes the agent's winning probability. Our \emph{Bidding-in-Spades} (BIS) algorithm heuristically determines the bidding strategy by comparing the expected utility of each possible bid. A major challenge is how to estimate these expected utilities. To this end, we propose a set of domain-specific heuristics, and then correct them via machine learning using data from real-world players. The \BIS algorithm we present can be attached to any playing algorithm. It beats rule-based bidding bots when all use the same playing component. When combined with a rule-based playing algorithm, it is superior to the average recreational human.
Predicting In-game Actions From the Language of NBA Players
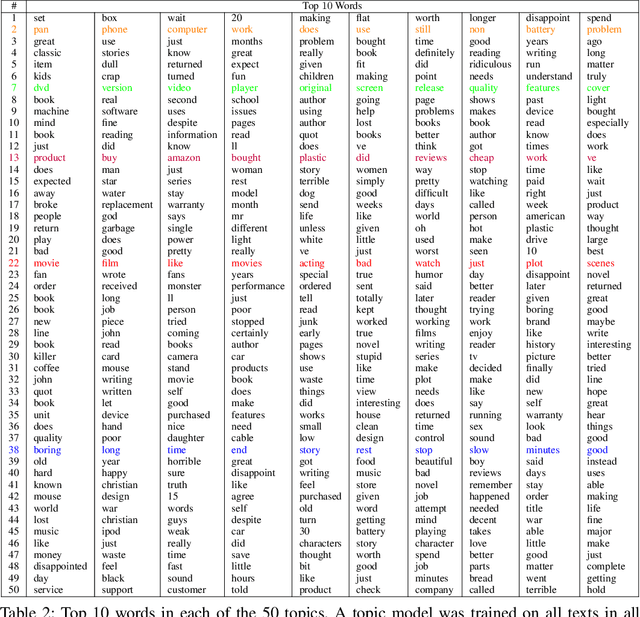
Oct 25, 2019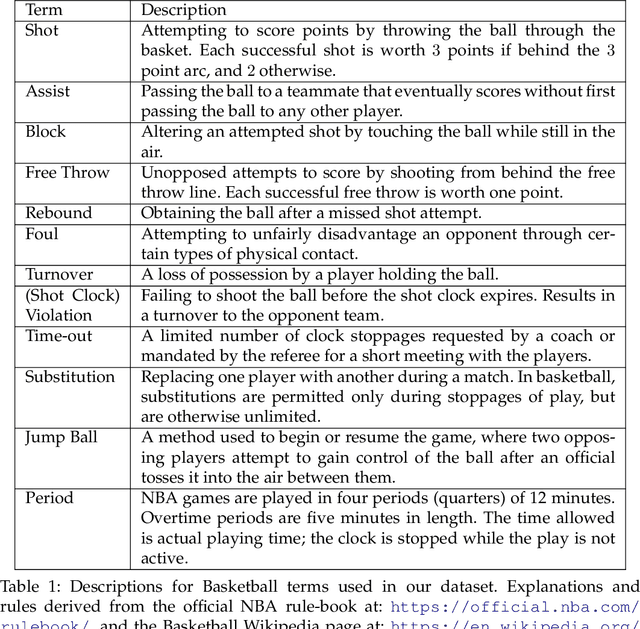
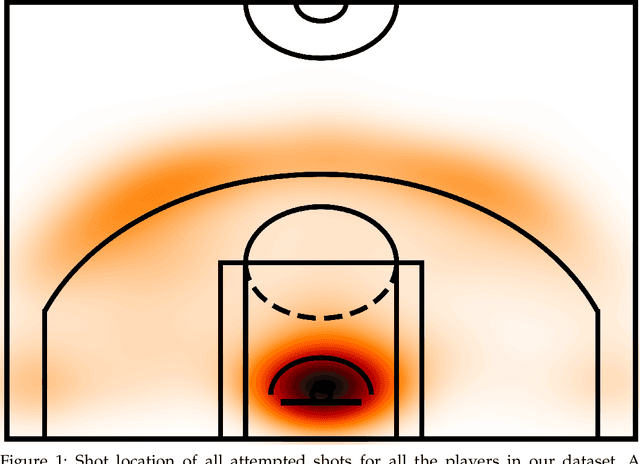
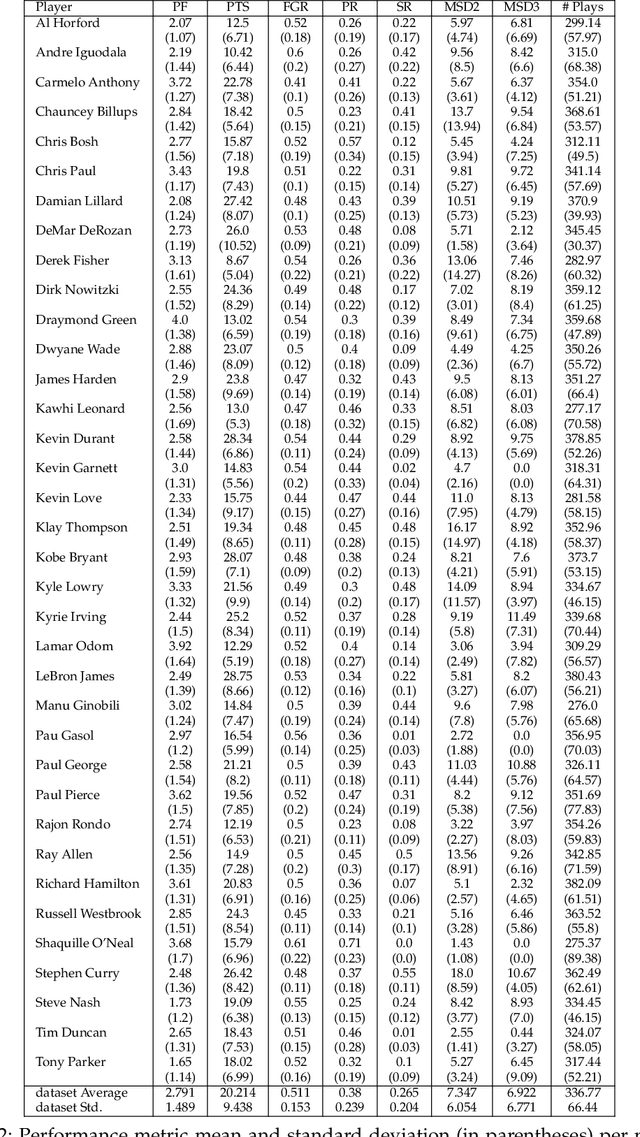
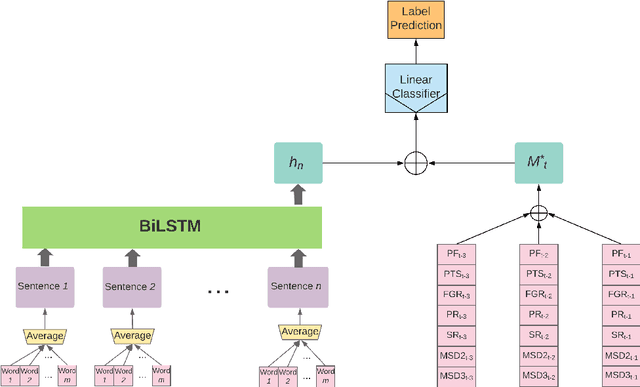
Sports competitions are widely researched in computer and social science, with the goal of understanding how players act under uncertainty. While there is an abundance of computational work on player metrics prediction based on past performance, very few attempts to incorporate out-of-game signals have been made. Specifically, it was previously unclear whether linguistic signals gathered from players' interviews can add information which does not appear in performance metrics. To bridge that gap, we define text classification tasks of predicting deviations from mean in NBA players' in-game actions, which are associated with strategic choices, player behavior and risk, using their choice of language prior to the game. We collected a dataset of transcripts from key NBA players' pre-game interviews and their in-game performance metrics, totaling in 5,226 interview-metric pairs. We design neural models for players' action prediction based on increasingly more complex aspects of the language signals in their open-ended interviews. Our models can make their predictions based on the textual signal alone, or on a combination with signals from past-performance metrics. Our text-based models outperform strong baselines trained on performance metrics only, demonstrating the importance of language usage for action prediction. Moreover, the models that employ both textual input and past-performance metrics produced the best results. Finally, as neural networks are notoriously difficult to interpret, we propose a method for gaining further insight into what our models have learned. Particularly, we present an LDA-based analysis, where we interpret model predictions in terms of correlated topics. We find that our best performing textual model is most associated with topics that are intuitively related to each prediction task and that better models yield higher correlation with more informative topics.