 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePADA: A Prompt-based Autoregressive Approach for Adaptation to Unseen Domains
Paper and Code
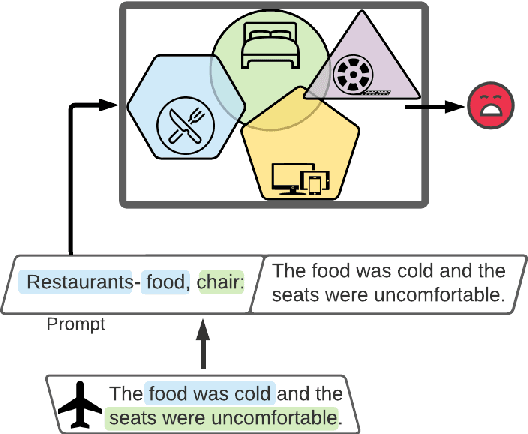
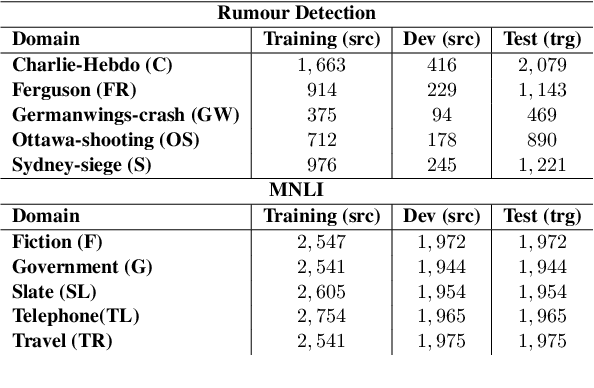
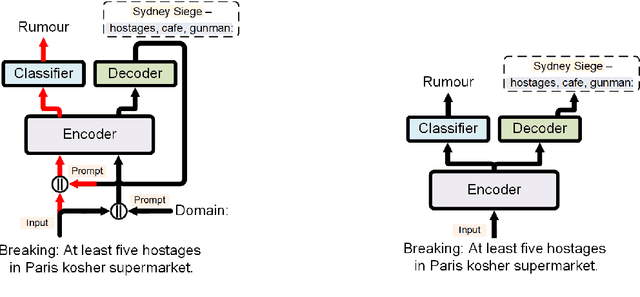
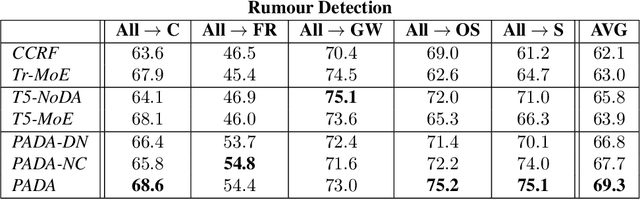
Natural Language Processing algorithms have made incredible progress recently, but they still struggle when applied to out-of-distribution examples. In this paper, we address a very challenging and previously underexplored version of this domain adaptation problem. In our setup an algorithm is trained on several source domains, and then applied to examples from an unseen domain that is unknown at training time. Particularly, no examples, labeled or unlabeled, or any other knowledge about the target domain are available to the algorithm at training time. We present PADA: A Prompt-based Autoregressive Domain Adaptation algorithm, based on the T5 model. Given a test example, PADA first generates a unique prompt and then, conditioned on this prompt, labels the example with respect to the NLP task. The prompt is a sequence of unrestricted length, consisting of pre-defined Domain Related Features (DRFs) that characterize each of the source domains. Intuitively, the prompt is a unique signature that maps the test example to the semantic space spanned by the source domains. In experiments with two tasks: Rumour Detection and Multi-Genre Natural Language Inference (MNLI), for a total of 10 multi-source adaptation scenarios, PADA strongly outperforms state-of-the-art approaches and additional strong baselines.