 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIBERTy: A Causal Framework for Benchmarking Concept-Based Explanations of LLMs with Structural Counterfactuals
Jan 15, 2026Concept-based explanations quantify how high-level concepts (e.g., gender or experience) influence model behavior, which is crucial for decision-makers in high-stakes domains. Recent work evaluates the faithfulness of such explanations by comparing them to reference causal effects estimated from counterfactuals. In practice, existing benchmarks rely on costly human-written counterfactuals that serve as an imperfect proxy. To address this, we introduce a framework for constructing datasets containing structural counterfactual pairs: LIBERTy (LLM-based Interventional Benchmark for Explainability with Reference Targets). LIBERTy is grounded in explicitly defined Structured Causal Models (SCMs) of the text generation, interventions on a concept propagate through the SCM until an LLM generates the counterfactual. We introduce three datasets (disease detection, CV screening, and workplace violence prediction) together with a new evaluation metric, order-faithfulness. Using them, we evaluate a wide range of methods across five models and identify substantial headroom for improving concept-based explanations. LIBERTy also enables systematic analysis of model sensitivity to interventions: we find that proprietary LLMs show markedly reduced sensitivity to demographic concepts, likely due to post-training mitigation. Overall, LIBERTy provides a much-needed benchmark for developing faithful explainability methods.
Text2Model: Model Induction for Zero-shot Generalization Using Task Descriptions
Oct 27, 2022



We study the problem of generating a training-free task-dependent visual classifier from text descriptions without visual samples. This \textit{Text-to-Model} (T2M) problem is closely related to zero-shot learning, but unlike previous work, a T2M model infers a model tailored to a task, taking into account all classes in the task. We analyze the symmetries of T2M, and characterize the equivariance and invariance properties of corresponding models. In light of these properties, we design an architecture based on hypernetworks that given a set of new class descriptions predicts the weights for an object recognition model which classifies images from those zero-shot classes. We demonstrate the benefits of our approach compared to zero-shot learning from text descriptions in image and point-cloud classification using various types of text descriptions: From single words to rich text descriptions.
Example-based Hypernetworks for Out-of-Distribution Generalization
Apr 02, 2022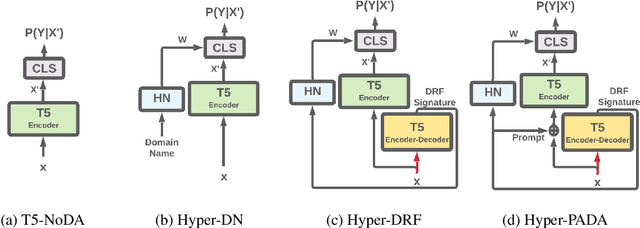



While Natural Language Processing (NLP) algorithms keep reaching unprecedented milestones, out-of-distribution generalization is still challenging. In this paper we address the problem of multi-source adaptation to unknown domains: Given labeled data from multiple source domains, we aim to generalize to data drawn from target domains that are unknown to the algorithm at training time. We present an algorithmic framework based on example-based Hypernetwork adaptation: Given an input example, a T5 encoder-decoder first generates a unique signature which embeds this example in the semantic space of the source domains, and this signature is then fed into a Hypernetwork which generates the weights of the task classifier. In an advanced version of our model, the learned signature also serves for improving the representation of the input example. In experiments with two tasks, sentiment classification and natural language inference, across 29 adaptation settings, our algorithms substantially outperform existing algorithms for this adaptation setup. To the best of our knowledge, this is the first time Hypernetworks are applied to domain adaptation or in example-based manner in NLP.
Inference-Time Personalized Federated Learning
Nov 16, 2021

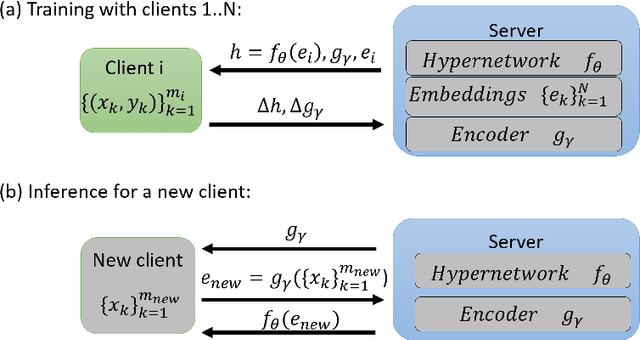
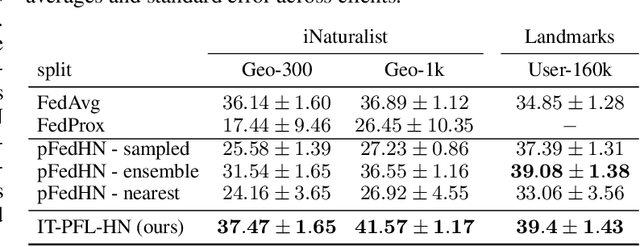
In Federated learning (FL), multiple clients collaborate to learn a model through a central server but keep the data decentralized. Personalized federated learning (PFL) further extends FL to handle data heterogeneity between clients by learning personalized models. In both FL and PFL, all clients participate in the training process and their labeled data is used for training. However, in reality, novel clients may wish to join a prediction service after it has been deployed, obtaining predictions for their own unlabeled data. Here, we defined a new learning setup, Inference-Time PFL (IT-PFL), where a model trained on a set of clients, needs to be later evaluated on novel unlabeled clients at inference time. We propose a novel approach to this problem IT-PFL-HN, based on a hypernetwork module and an encoder module. Specifically, we train an encoder network that learns a representation for a client given its unlabeled data. That client representation is fed to a hypernetwork that generates a personalized model for that client. Evaluated on four benchmark datasets, we find that IT-PFL-HN generalizes better than current FL and PFL methods, especially when the novel client has a large domain shift. We also analyzed the generalization error for the novel client, showing how it can be bounded using results from multi-task learning and domain adaptation. Finally, since novel clients do not contribute their data to training, they can potentially have better control over their data privacy; indeed, we showed analytically and experimentally how novel clients can apply differential privacy to their data.
Teacher-Student Consistency For Multi-Source Domain Adaptation
Oct 20, 2020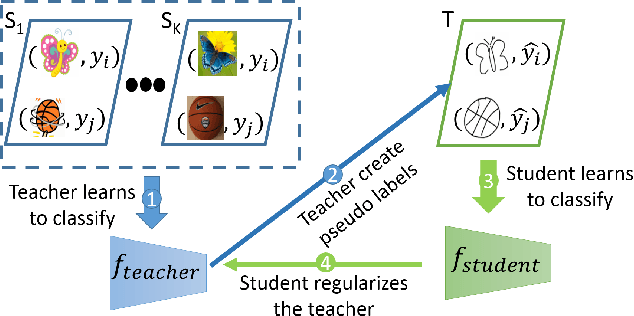

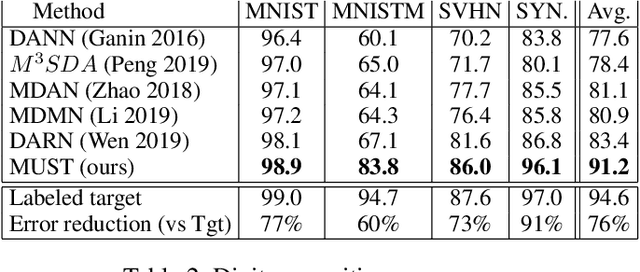
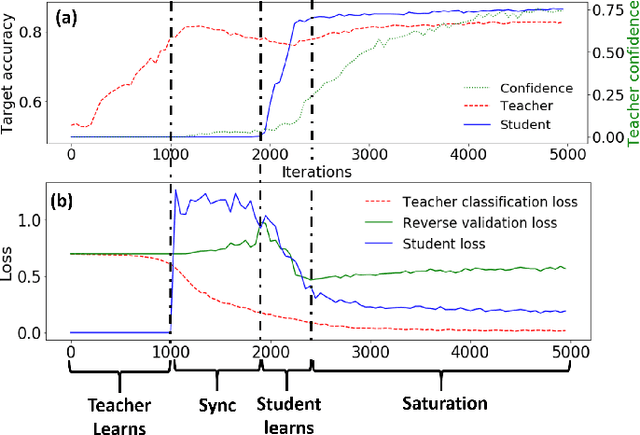
In Multi-Source Domain Adaptation (MSDA), models are trained on samples from multiple source domains and used for inference on a different, target, domain. Mainstream domain adaptation approaches learn a joint representation of source and target domains. Unfortunately, a joint representation may emphasize features that are useful for the source domains but hurt inference on target (negative transfer), or remove essential information about the target domain (knowledge fading). We propose Multi-source Student Teacher (MUST), a novel procedure designed to alleviate these issues. The key idea has two steps: First, we train a teacher network on source labels and infer pseudo labels on the target. Then, we train a student network using the pseudo labels and regularized the teacher to fit the student predictions. This regularization helps the teacher predictions on the target data remain consistent between epochs. Evaluations of MUST on three MSDA benchmarks: digits, text sentiment analysis, and visual-object recognition show that MUST outperforms current SoTA, sometimes by a very large margin. We further analyze the solutions and the dynamics of the optimization showing that the learned models follow the target distribution density, implicitly using it as information within the unlabeled target data.