 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-Student Consistency For Multi-Source Domain Adaptation
Paper and Code
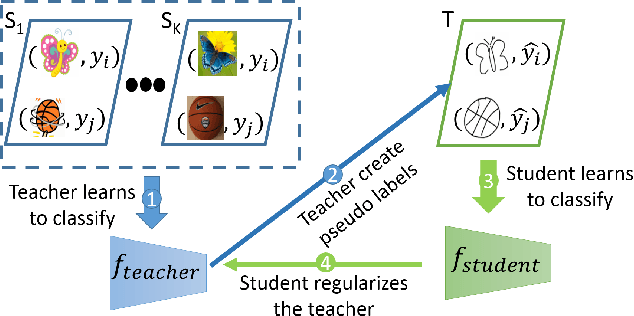

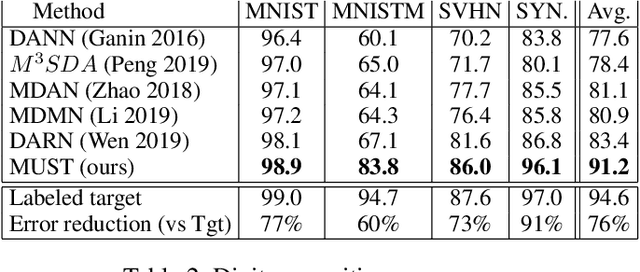
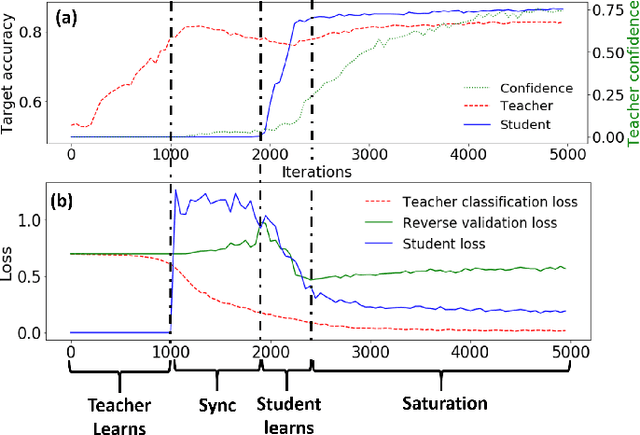
In Multi-Source Domain Adaptation (MSDA), models are trained on samples from multiple source domains and used for inference on a different, target, domain. Mainstream domain adaptation approaches learn a joint representation of source and target domains. Unfortunately, a joint representation may emphasize features that are useful for the source domains but hurt inference on target (negative transfer), or remove essential information about the target domain (knowledge fading). We propose Multi-source Student Teacher (MUST), a novel procedure designed to alleviate these issues. The key idea has two steps: First, we train a teacher network on source labels and infer pseudo labels on the target. Then, we train a student network using the pseudo labels and regularized the teacher to fit the student predictions. This regularization helps the teacher predictions on the target data remain consistent between epochs. Evaluations of MUST on three MSDA benchmarks: digits, text sentiment analysis, and visual-object recognition show that MUST outperforms current SoTA, sometimes by a very large margin. We further analyze the solutions and the dynamics of the optimization showing that the learned models follow the target distribution density, implicitly using it as information within the unlabeled target data.