 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Scale Prediction: A Self-Supervised Approach for Real-World Image Denoising
Dec 24, 2025Self-supervised real-world image denoising remains a fundamental challenge, arising from the antagonistic trade-off between decorrelating spatially structured noise and preserving high-frequency details. Existing blind-spot network (BSN) methods rely on pixel-shuffle downsampling (PD) to decorrelate noise, but aggressive downsampling fragments fine structures, while milder downsampling fails to remove correlated noise. To address this, we introduce Next-Scale Prediction (NSP), a novel self-supervised paradigm that decouples noise decorrelation from detail preservation. NSP constructs cross-scale training pairs, where BSN takes low-resolution, fully decorrelated sub-images as input to predict high-resolution targets that retain fine details. As a by-product, NSP naturally supports super-resolution of noisy images without retraining or modification. Extensive experiments demonstrate that NSP achieves state-of-the-art self-supervised denoising performance on real-world benchmarks, significantly alleviating the long-standing conflict between noise decorrelation and detail preservation.
LaverNet: Lightweight All-in-one Video Restoration via Selective Propagation
Dec 18, 2025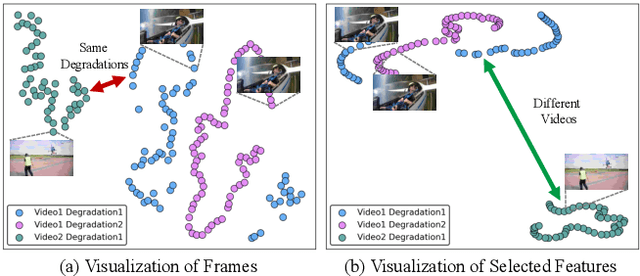
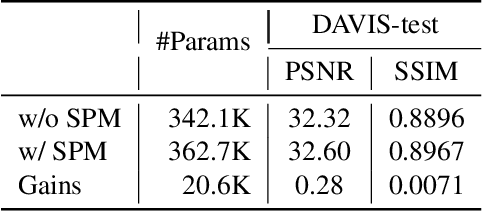
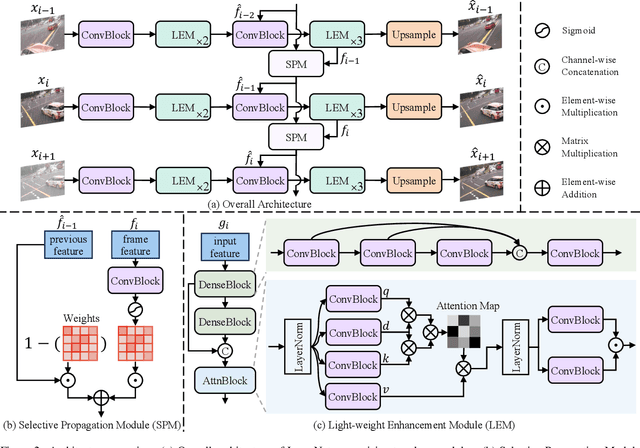
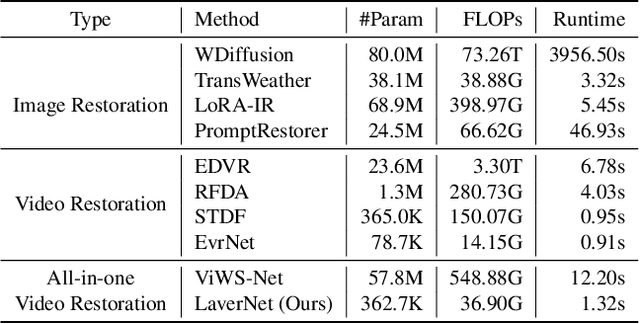
Recent studies have explored all-in-one video restoration, which handles multiple degradations with a unified model. However, these approaches still face two challenges when dealing with time-varying degradations. First, the degradation can dominate temporal modeling, confusing the model to focus on artifacts rather than the video content. Second, current methods typically rely on large models to handle all-in-one restoration, concealing those underlying difficulties. To address these challenges, we propose a lightweight all-in-one video restoration network, LaverNet, with only 362K parameters. To mitigate the impact of degradations on temporal modeling, we introduce a novel propagation mechanism that selectively transmits only degradation-agnostic features across frames. Through LaverNet, we demonstrate that strong all-in-one restoration can be achieved with a compact network. Despite its small size, less than 1\% of the parameters of existing models, LaverNet achieves comparable, even superior performance across benchmarks.
MaIR: A Locality- and Continuity-Preserving Mamba for Image Restoration
Dec 28, 2024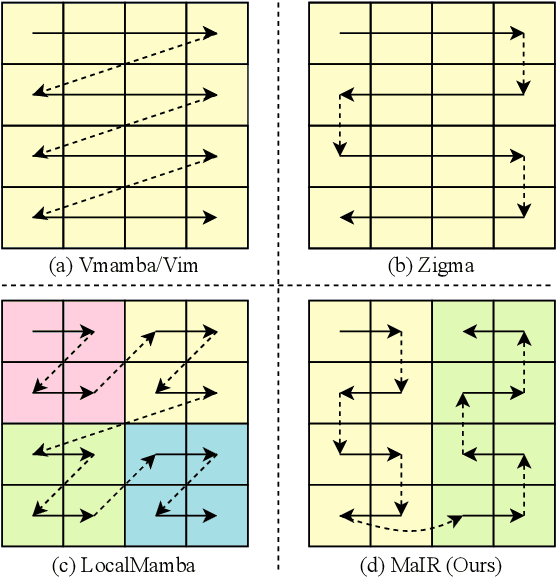
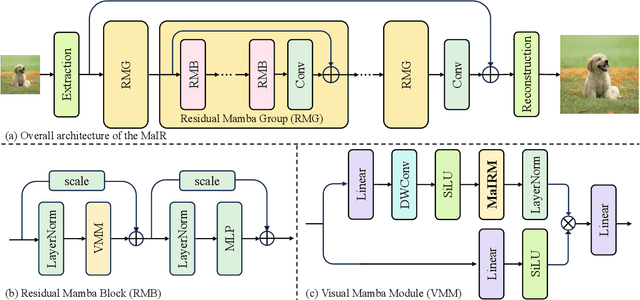
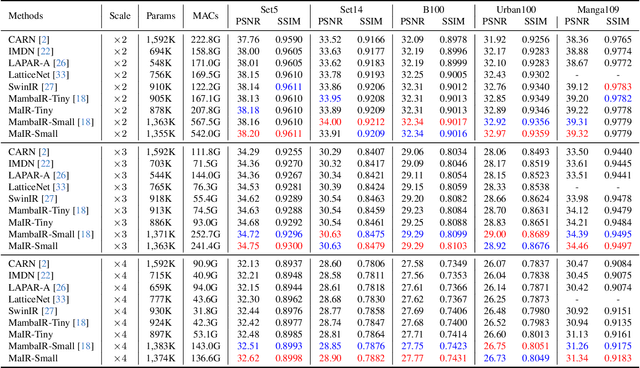
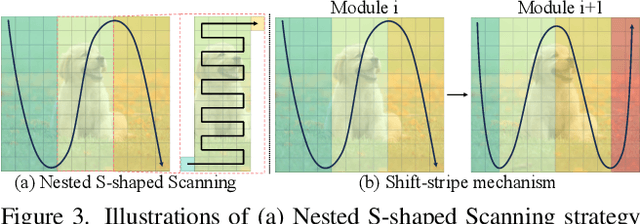
Recent advancements in Mamba have shown promising results in image restoration. These methods typically flatten 2D images into multiple distinct 1D sequences along rows and columns, process each sequence independently using selective scan operation, and recombine them to form the outputs. However, such a paradigm overlooks two vital aspects: i) the local relationships and spatial continuity inherent in natural images, and ii) the discrepancies among sequences unfolded through totally different ways. To overcome the drawbacks, we explore two problems in Mamba-based restoration methods: i) how to design a scanning strategy preserving both locality and continuity while facilitating restoration, and ii) how to aggregate the distinct sequences unfolded in totally different ways. To address these problems, we propose a novel Mamba-based Image Restoration model (MaIR), which consists of Nested S-shaped Scanning strategy (NSS) and Sequence Shuffle Attention block (SSA). Specifically, NSS preserves locality and continuity of the input images through the stripe-based scanning region and the S-shaped scanning path, respectively. SSA aggregates sequences through calculating attention weights within the corresponding channels of different sequences. Thanks to NSS and SSA, MaIR surpasses 40 baselines across 14 challenging datasets, achieving state-of-the-art performance on the tasks of image super-resolution, denoising, deblurring and dehazing. Our codes will be available after acceptance.
Self-Supervised Conditional Distribution Learning on Graphs
Nov 20, 2024Graph contrastive learning (GCL) has shown promising performance in semisupervised graph classification. However, existing studies still encounter significant challenges in GCL. First, successive layers in graph neural network (GNN) tend to produce more similar node embeddings, while GCL aims to increase the dissimilarity between negative pairs of node embeddings. This inevitably results in a conflict between the message-passing mechanism of GNNs and the contrastive learning of negative pairs via intraviews. Second, leveraging the diversity and quantity of data provided by graph-structured data augmentations while preserving intrinsic semantic information is challenging. In this paper, we propose a self-supervised conditional distribution learning (SSCDL) method designed to learn graph representations from graph-structured data for semisupervised graph classification. Specifically, we present an end-to-end graph representation learning model to align the conditional distributions of weakly and strongly augmented features over the original features. This alignment effectively reduces the risk of disrupting intrinsic semantic information through graph-structured data augmentation. To avoid conflict between the message-passing mechanism and contrastive learning of negative pairs, positive pairs of node representations are retained for measuring the similarity between the original features and the corresponding weakly augmented features. Extensive experiments with several benchmark graph datasets demonstrate the effectiveness of the proposed SSCDL method.
Hierarchical Sparse Representation Clustering for High-Dimensional Data Streams
Sep 07, 2024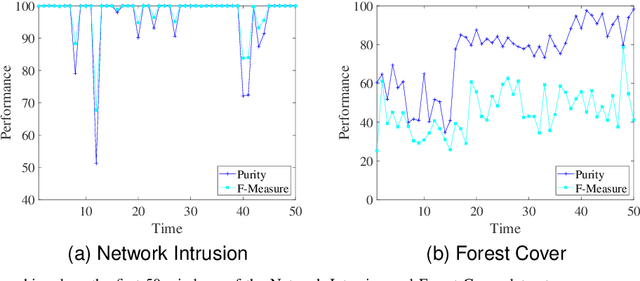



Data stream clustering reveals patterns within continuously arriving, potentially unbounded data sequences. Numerous data stream algorithms have been proposed to cluster data streams. The existing data stream clustering algorithms still face significant challenges when addressing high-dimensional data streams. First, it is intractable to measure the similarities among high-dimensional data objects via Euclidean distances when constructing and merging microclusters. Second, these algorithms are highly sensitive to the noise contained in high-dimensional data streams. In this paper, we propose a hierarchical sparse representation clustering (HSRC) method for clustering high-dimensional data streams. HSRC first employs an $l_1$-minimization technique to learn an affinity matrix for data objects in individual landmark windows with fixed sizes, where the number of neighboring data objects is automatically selected. This approach ensures that highly correlated data samples within clusters are grouped together. Then, HSRC applies a spectral clustering technique to the affinity matrix to generate microclusters. These microclusters are subsequently merged into macroclusters based on their sparse similarity degrees (SSDs). Additionally, HSRC introduces sparsity residual values (SRVs) to adaptively select representative data objects from the current landmark window. These representatives serve as dictionary samples for the next landmark window. Finally, HSRC refines each macrocluster through fine-tuning. In particular, HSRC enables the detection of outliers in high-dimensional data streams via the associated SRVs. The experimental results obtained on several benchmark datasets demonstrate the effectiveness and robustness of HSRC.
Exploiting Diffusion Priors for All-in-One Image Restoration
Dec 02, 2023



All-in-one aims to solve various tasks of image restoration in a single model. To this end, we present a feasible way of exploiting the image priors captured by the pretrained diffusion model, through addressing the two challenges, i.e., degradation modeling and diffusion guidance. The former aims to simulate the process of the clean image degenerated by certain degradations, and the latter aims at guiding the diffusion model to generate the corresponding clean image. With the motivations, we propose a zero-shot framework for all-in-one image restoration, termed ZeroAIR, which alternatively performs the test-time degradation modeling (TDM) and the three-stage diffusion guidance (TDG) at each timestep of the reverse sampling. To be specific, TDM exploits the diffusion priors to learn a degradation model from a given degraded image, and TDG divides the timesteps into three stages for taking full advantage of the varying diffusion priors. Thanks to their degradation-agnostic property, the all-in-one image restoration could be achieved in a zero-shot way by ZeroAIR. Through extensive experiments, we show that our ZeroAIR achieves comparable even better performance than those task-specific methods. The code will be available on Github.
Relationship Quantification of Image Degradations
Dec 08, 2022In this paper, we study two challenging but less-touched problems in image restoration, namely, i) how to quantify the relationship between different image degradations and ii) how to improve the performance of a specific restoration task using the quantified relationship. To tackle the first challenge, Degradation Relationship Index (DRI) is proposed to measure the degradation relationship, which is defined as the drop rate difference in the validation loss between two models, i.e., one is trained using the anchor task only and another is trained using the anchor and the auxiliary tasks. Through quantifying the relationship between different degradations using DRI, we empirically observe that i) the degradation combination proportion is crucial to the image restoration performance. In other words, the combinations with only appropriate degradation proportions could improve the performance of the anchor restoration; ii) a positive DRI always predicts the performance improvement of image restoration. Based on the observations, we propose an adaptive Degradation Proportion Determination strategy (DPD) which could improve the performance of the anchor restoration task by using another restoration task as auxiliary. Extensive experimental results verify the effective of our method by taking image dehazing as the anchor task and denoising, desnowing, and deraining as the auxiliary tasks. The code will be released after acceptance.
Multi-Scale Adaptive Network for Single Image Denoising
Mar 08, 2022



Multi-scale architectures have shown effectiveness in a variety of tasks including single image denoising, thanks to appealing cross-scale complementarity. However, existing methods treat different scale features equally without considering their scale-specific characteristics, i.e., the within-scale characteristics are ignored. In this paper, we reveal this missing piece for multi-scale architecture design and accordingly propose a novel Multi-Scale Adaptive Network (MSANet) for single image denoising. To be specific, MSANet simultaneously embraces the within-scale characteristics and the cross-scale complementarity thanks to three novel neural blocks, i.e., adaptive feature block (AFeB), adaptive multi-scale block (AMB), and adaptive fusion block (AFuB). In brief, AFeB is designed to adaptively select details and filter noises, which is highly expected for fine-grained features. AMB could enlarge the receptive field and aggregate the multi-scale information, which is designed to satisfy the demands of both fine- and coarse-grained features. AFuB devotes to adaptively sampling and transferring the features from one scale to another scale, which is used to fuse the features with varying characteristics from coarse to fine. Extensive experiments on both three real and six synthetic noisy image datasets show the superiority of MSANet compared with 12 methods.
You Only Look Yourself: Unsupervised and Untrained Single Image Dehazing Neural Network
Jun 30, 2020
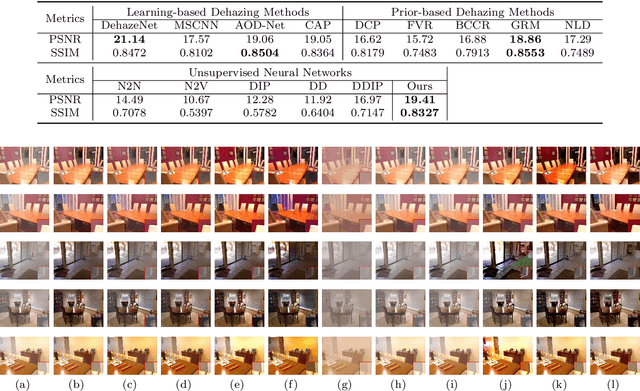

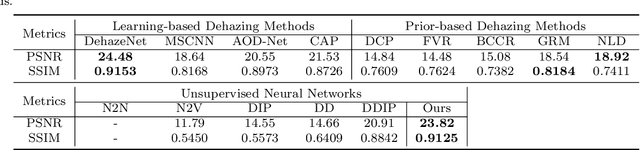
In this paper, we study two challenging and less-touched problems in single image dehazing, namely, how to make deep learning achieve image dehazing without training on the ground-truth clean image (unsupervised) and a image collection (untrained). An unsupervised neural network will avoid the intensive labor collection of hazy-clean image pairs, and an untrained model is a ``real'' single image dehazing approach which could remove haze based on only the observed hazy image itself and no extra images is used. Motivated by the layer disentanglement idea, we propose a novel method, called you only look yourself (\textbf{YOLY}) which could be one of the first unsupervised and untrained neural networks for image dehazing. In brief, YOLY employs three jointly subnetworks to separate the observed hazy image into several latent layers, \textit{i.e.}, scene radiance layer, transmission map layer, and atmospheric light layer. After that, these three layers are further composed to the hazy image in a self-supervised manner. Thanks to the unsupervised and untrained characteristics of YOLY, our method bypasses the conventional training paradigm of deep models on hazy-clean pairs or a large scale dataset, thus avoids the labor-intensive data collection and the domain shift issue. Besides, our method also provides an effective learning-based haze transfer solution thanks to its layer disentanglement mechanism. Extensive experiments show the promising performance of our method in image dehazing compared with 14 methods on four databases.