 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Sparse Representation Clustering for High-Dimensional Data Streams
Paper and Code
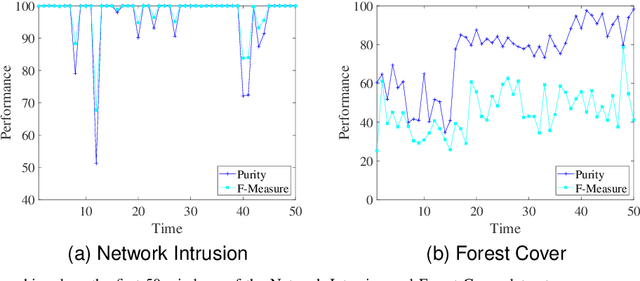



Data stream clustering reveals patterns within continuously arriving, potentially unbounded data sequences. Numerous data stream algorithms have been proposed to cluster data streams. The existing data stream clustering algorithms still face significant challenges when addressing high-dimensional data streams. First, it is intractable to measure the similarities among high-dimensional data objects via Euclidean distances when constructing and merging microclusters. Second, these algorithms are highly sensitive to the noise contained in high-dimensional data streams. In this paper, we propose a hierarchical sparse representation clustering (HSRC) method for clustering high-dimensional data streams. HSRC first employs an $l_1$-minimization technique to learn an affinity matrix for data objects in individual landmark windows with fixed sizes, where the number of neighboring data objects is automatically selected. This approach ensures that highly correlated data samples within clusters are grouped together. Then, HSRC applies a spectral clustering technique to the affinity matrix to generate microclusters. These microclusters are subsequently merged into macroclusters based on their sparse similarity degrees (SSDs). Additionally, HSRC introduces sparsity residual values (SRVs) to adaptively select representative data objects from the current landmark window. These representatives serve as dictionary samples for the next landmark window. Finally, HSRC refines each macrocluster through fine-tuning. In particular, HSRC enables the detection of outliers in high-dimensional data streams via the associated SRVs. The experimental results obtained on several benchmark datasets demonstrate the effectiveness and robustness of HSRC.