 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA governance horizon for ethical-use constraints in open-weight AI models
May 23, 2026Ethical constraints on open-weight AI models are both a reflection of societal concerns and a foundation for AI governance policy. They are expected to propagate to downstream derivatives while implemented as voluntary metadata disclosures that must be restated at each generation of reuse. We audit 2,142,823 model repositories on Hugging Face Hub to test whether this disclosure-based governance infrastructure can sustain traceability across deep model lineages. Restriction evidence decays with a half-life of 1.31 derivation steps ($R^2$=0.98), and beyond seven downstream generations at least 80% of descendant models lack sufficient public evidence for a governance determination, a depth boundary we formalize as the governance horizon. Platform-level interventions to restore missing licence metadata reveal that policy design (not enforcement alone) is the binding factor: inheritance-only designs require near-complete enforcement to move the horizon, whereas a mandatory-declaration design that explicitly resolves orphan lineage components shifts the horizon already at moderate enforcement. The structural bottleneck is lineages with no inheritable upstream intent: such orphan components remain undecidable under any inheritance-only policy regardless of enforcement rate, and unresolved upstream nodes additionally create direct downstream undecidability bottlenecks that inheritance rules alone cannot recover. Comparison with PyPI, where governance signals are carried by explicit machine-readable declarations, corroborates that the collapse is topology-specific to open-weight derivation rather than inherent to open ecosystems. These results establish that disclosure-based governance has a shallow, structurally determined reach in open-weight AI, and that achieving deep supply-chain accountability requires provenance mechanisms propagating governance signals through derivation itself.
The Readability Spectrum: Patterns, Issues, and Prompt Effects in LLM-Generated Code
May 13, 2026As Large Language Models (LLMs) are transforming software development, the functional quality of generated code has become a central focus, leaving readability, one of critical non-functional attributes, understudied. Given that LLM-generated code still needs human review before adoption, it is important to understand its readability especially compared with human-written code and the role of prompt design in shaping it. We therefore set out to conduct a systematic investigation into the code readability of LLM-generated code. To systematically quantify code readability, We establish a comprehensive readability model that synthesizes textual, structural, program, and visual features of code. Based on the model, we evaluate the readability of code generated by the mainstream LLMs under 5,869 scenarios extracted from large code base including World of Code (WoC) and LeetCode. We find that current LLMs produce code with overall readability comparable to human-written code, but displaying distinct readability issue patterns. We further examine how different prompt dimensions affect the readability of LLM-generated code, and find that function signatures, constraints and style descriptions emerge as the most influential factors, while the overall impact of prompt design remains limited. Our findings indicate that, on one hand, LLM-generated code is at least comparable to human-written code in readability, validating its potential for systematic integration into software workflows from a non-functional perspective; on the other hand, distinct readability issue patterns and limited effectiveness of prompt engineering reveal a latent technical debt, highlighting the need for future research to improve the readability of LLM-generated code and thus ensure long-term maintainability.
Characterising Open Source Co-opetition in Company-hosted Open Source Software Projects: The Cases of PyTorch, TensorFlow, and Transformers
Oct 23, 2024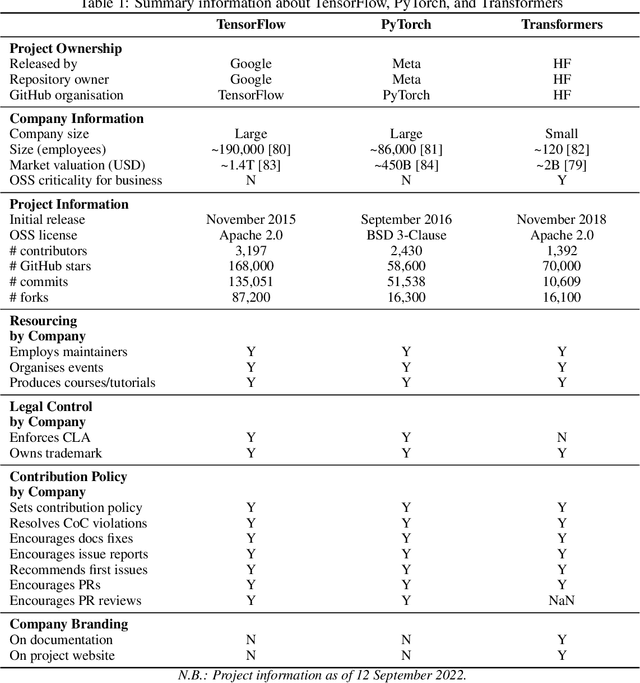
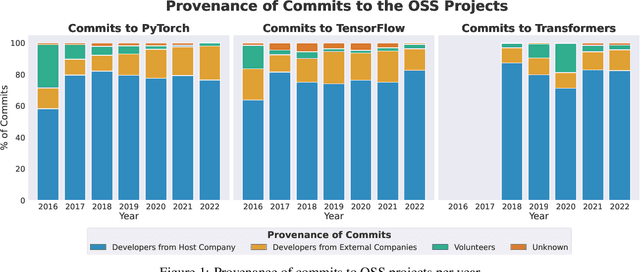

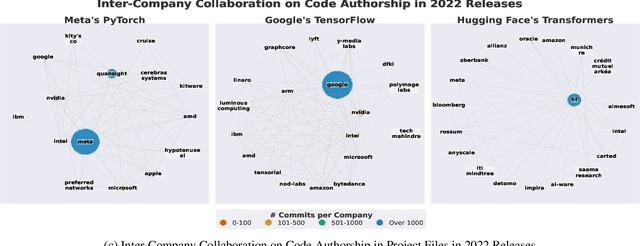
Companies, including market rivals, have long collaborated on the development of open source software (OSS), resulting in a tangle of co-operation and competition known as "open source co-opetition". While prior work investigates open source co-opetition in OSS projects that are hosted by vendor-neutral foundations, we have a limited understanding thereof in OSS projects that are hosted and governed by one company. Given their prevalence, it is timely to investigate open source co-opetition in such contexts. Towards this end, we conduct a mixed-methods analysis of three company-hosted OSS projects in the artificial intelligence (AI) industry: Meta's PyTorch (prior to its donation to the Linux Foundation), Google's TensorFlow, and Hugging Face's Transformers. We contribute three key findings. First, while the projects exhibit similar code authorship patterns between host and external companies (80%/20% of commits), collaborations are structured differently (e.g., decentralised vs. hub-and-spoke networks). Second, host and external companies engage in strategic, non-strategic, and contractual collaborations, with varying incentives and collaboration practices. Some of the observed collaborations are specific to the AI industry (e.g., hardware-software optimizations or AI model integrations), while others are typical of the broader software industry (e.g., bug fixing or task outsourcing). Third, single-vendor governance creates a power imbalance that influences open source co-opetition practices and possibilities, from the host company's singular decision-making power (e.g., the risk of license change) to their community involvement strategy (e.g., from over-control to over-delegation). We conclude with recommendations for future research.
A First Look at License Compliance Capability of LLMs in Code Generation
Aug 05, 2024



Recent advances in Large Language Models (LLMs) have revolutionized code generation, leading to widespread adoption of AI coding tools by developers. However, LLMs can generate license-protected code without providing the necessary license information, leading to potential intellectual property violations during software production. This paper addresses the critical, yet underexplored, issue of license compliance in LLM-generated code by establishing a benchmark to evaluate the ability of LLMs to provide accurate license information for their generated code. To establish this benchmark, we conduct an empirical study to identify a reasonable standard for "striking similarity" that excludes the possibility of independent creation, indicating a copy relationship between the LLM output and certain open-source code. Based on this standard, we propose an evaluation benchmark LiCoEval, to evaluate the license compliance capabilities of LLMs. Using LiCoEval, we evaluate 14 popular LLMs, finding that even top-performing LLMs produce a non-negligible proportion (0.88% to 2.01%) of code strikingly similar to existing open-source implementations. Notably, most LLMs fail to provide accurate license information, particularly for code under copyleft licenses. These findings underscore the urgent need to enhance LLM compliance capabilities in code generation tasks. Our study provides a foundation for future research and development to improve license compliance in AI-assisted software development, contributing to both the protection of open-source software copyrights and the mitigation of legal risks for LLM users.