 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual policy as self-model for planning
Jun 11, 2023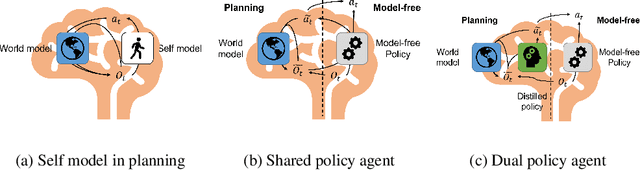

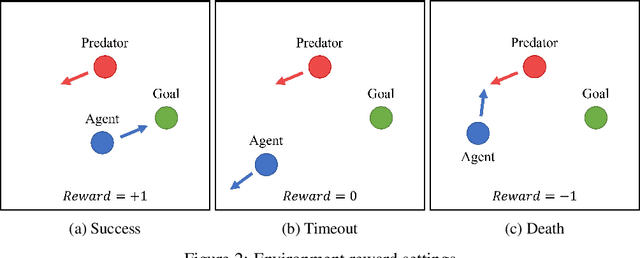
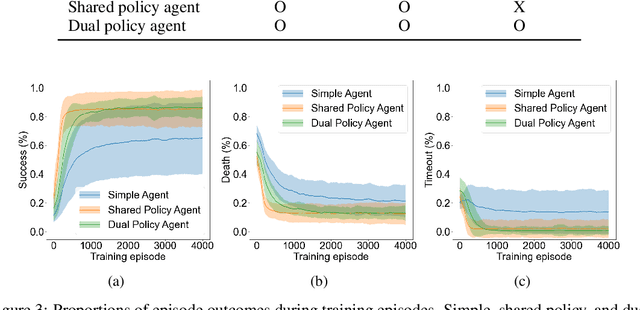
Planning is a data efficient decision-making strategy where an agent selects candidate actions by exploring possible future states. To simulate future states when there is a high-dimensional action space, the knowledge of one's decision making strategy must be used to limit the number of actions to be explored. We refer to the model used to simulate one's decisions as the agent's self-model. While self-models are implicitly used widely in conjunction with world models to plan actions, it remains unclear how self-models should be designed. Inspired by current reinforcement learning approaches and neuroscience, we explore the benefits and limitations of using a distilled policy network as the self-model. In such dual-policy agents, a model-free policy and a distilled policy are used for model-free actions and planned actions, respectively. Our results on a ecologically relevant, parametric environment indicate that distilled policy network for self-model stabilizes training, has faster inference than using model-free policy, promotes better exploration, and could learn a comprehensive understanding of its own behaviors, at the cost of distilling a new network apart from the model-free policy.
Review Learning: Alleviating Catastrophic Forgetting with Generative Replay without Generator
Oct 17, 2022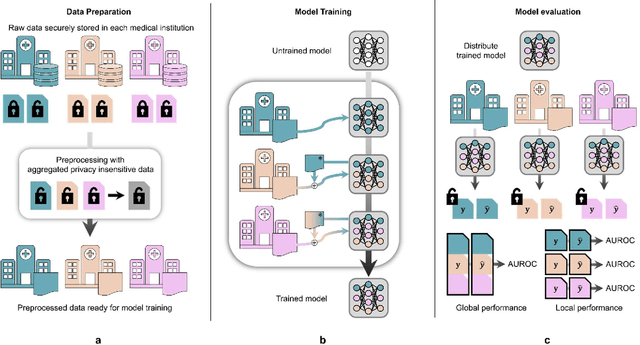

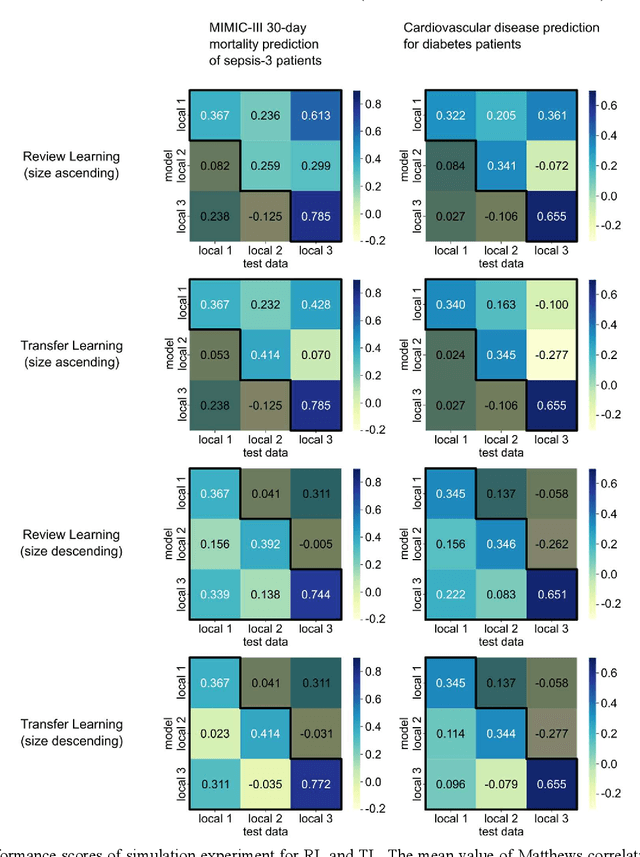
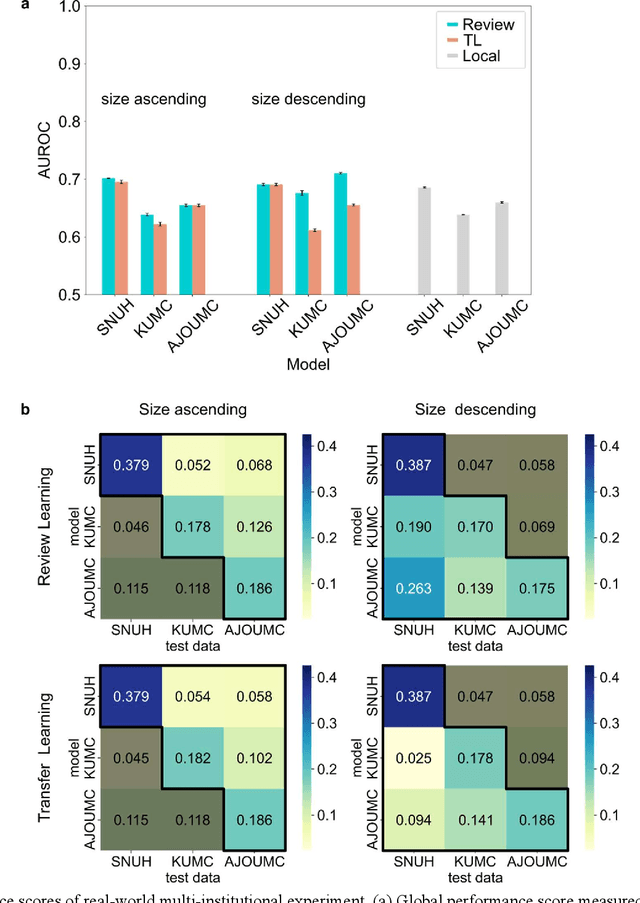
When a deep learning model is sequentially trained on different datasets, it forgets the knowledge acquired from previous data, a phenomenon known as catastrophic forgetting. It deteriorates performance of the deep learning model on diverse datasets, which is critical in privacy-preserving deep learning (PPDL) applications based on transfer learning (TL). To overcome this, we propose review learning (RL), a generative-replay-based continual learning technique that does not require a separate generator. Data samples are generated from the memory stored within the synaptic weights of the deep learning model which are used to review knowledge acquired from previous datasets. The performance of RL was validated through PPDL experiments. Simulations and real-world medical multi-institutional experiments were conducted using three types of binary classification electronic health record data. In the real-world experiments, the global area under the receiver operating curve was 0.710 for RL and 0.655 for TL. Thus, RL was highly effective in retaining previously learned knowledge.
On the Performance of Generative Adversarial Network (GAN) Variants: A Clinical Data Study
Sep 21, 2020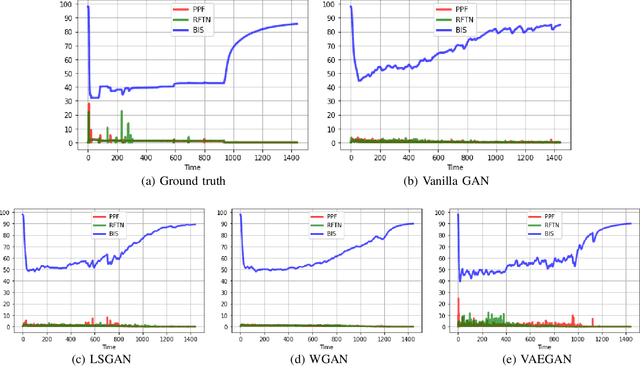
Generative Adversarial Network (GAN) is a useful type of Neural Networks in various types of applications including generative models and feature extraction. Various types of GANs are being researched with different insights, resulting in a diverse family of GANs with a better performance in each generation. This review focuses on various GANs categorized by their common traits.