 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Prompt Engineering Meets Software Engineering: CNL-P as Natural and Robust "APIs'' for Human-AI Interaction
Aug 09, 2025With the growing capabilities of large language models (LLMs), they are increasingly applied in areas like intelligent customer service, code generation, and knowledge management. Natural language (NL) prompts act as the ``APIs'' for human-LLM interaction. To improve prompt quality, best practices for prompt engineering (PE) have been developed, including writing guidelines and templates. Building on this, we propose Controlled NL for Prompt (CNL-P), which not only incorporates PE best practices but also draws on key principles from software engineering (SE). CNL-P introduces precise grammar structures and strict semantic norms, further eliminating NL's ambiguity, allowing for a declarative but structured and accurate expression of user intent. This helps LLMs better interpret and execute the prompts, leading to more consistent and higher-quality outputs. We also introduce an NL2CNL-P conversion tool based on LLMs, enabling users to write prompts in NL, which are then transformed into CNL-P format, thus lowering the learning curve of CNL-P. In particular, we develop a linting tool that checks CNL-P prompts for syntactic and semantic accuracy, applying static analysis techniques to NL for the first time. Extensive experiments demonstrate that CNL-P enhances the quality of LLM responses through the novel and organic synergy of PE and SE. We believe that CNL-P can bridge the gap between emerging PE and traditional SE, laying the foundation for a new programming paradigm centered around NL.
Privacy Meets Explainability: Managing Confidential Data and Transparency Policies in LLM-Empowered Science
Apr 14, 2025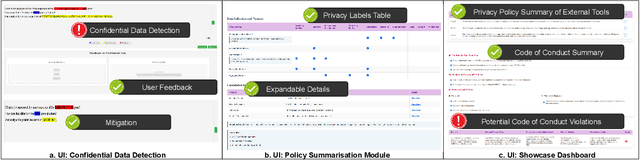


As Large Language Models (LLMs) become integral to scientific workflows, concerns over the confidentiality and ethical handling of confidential data have emerged. This paper explores data exposure risks through LLM-powered scientific tools, which can inadvertently leak confidential information, including intellectual property and proprietary data, from scientists' perspectives. We propose "DataShield", a framework designed to detect confidential data leaks, summarize privacy policies, and visualize data flow, ensuring alignment with organizational policies and procedures. Our approach aims to inform scientists about data handling practices, enabling them to make informed decisions and protect sensitive information. Ongoing user studies with scientists are underway to evaluate the framework's usability, trustworthiness, and effectiveness in tackling real-world privacy challenges.
An Evaluation-Driven Approach to Designing LLM Agents: Process and Architecture
Nov 21, 2024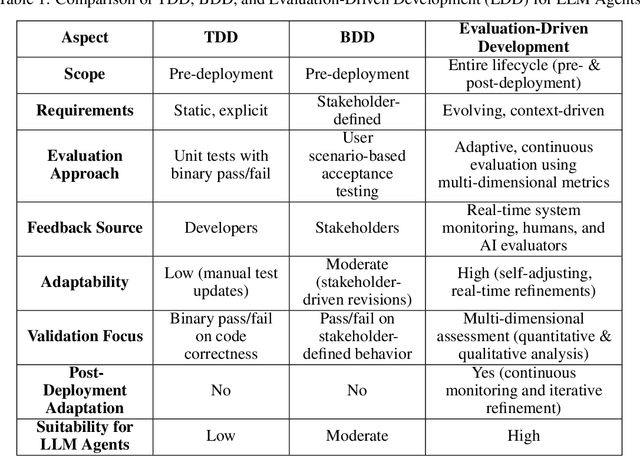

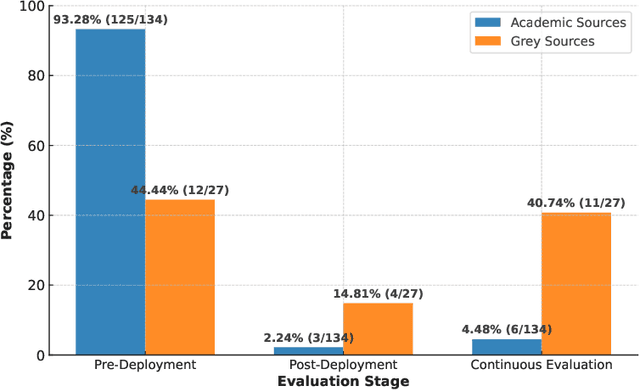

The advent of Large Language Models (LLMs) has enabled the development of LLM agents capable of autonomously achieving under-specified goals and continuously evolving through post-deployment improvement, sometimes without requiring code or model updates. Conventional approaches, such as pre-defined test cases and code/model redevelopment pipelines, are inadequate for addressing the unique challenges of LLM agent development, particularly in terms of quality and risk control. This paper introduces an evaluation-driven design approach, inspired by test-driven development, to address these challenges. Through a multivocal literature review (MLR), we synthesize existing LLM evaluation methods and propose a novel process model and reference architecture specifically designed for LLM agents. The proposed approach integrates online and offline evaluations to support adaptive runtime adjustments and systematic offline redevelopment, improving runtime pipelines, artifacts, system architecture, and LLMs by continuously incorporating evaluation results, including fine-grained feedback from human and AI evaluators.
Towards AI-Safety-by-Design: A Taxonomy of Runtime Guardrails in Foundation Model based Systems
Aug 05, 2024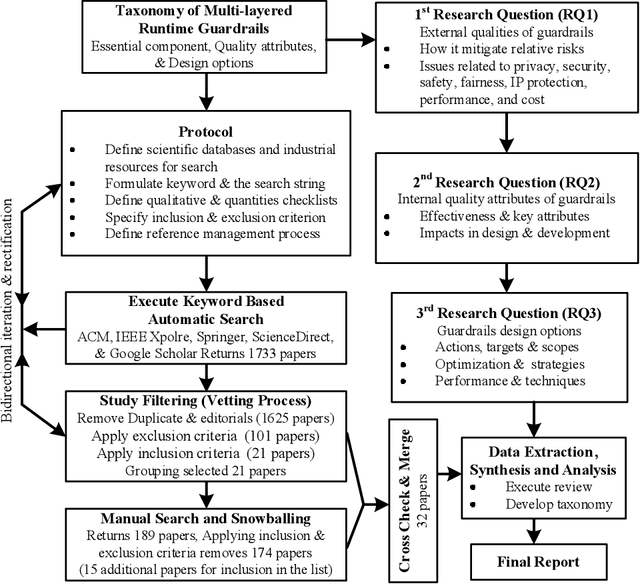
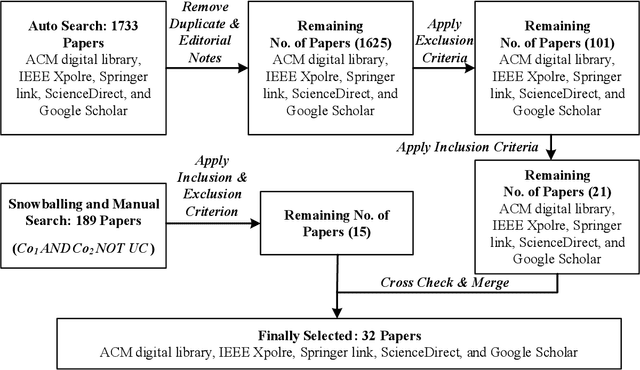
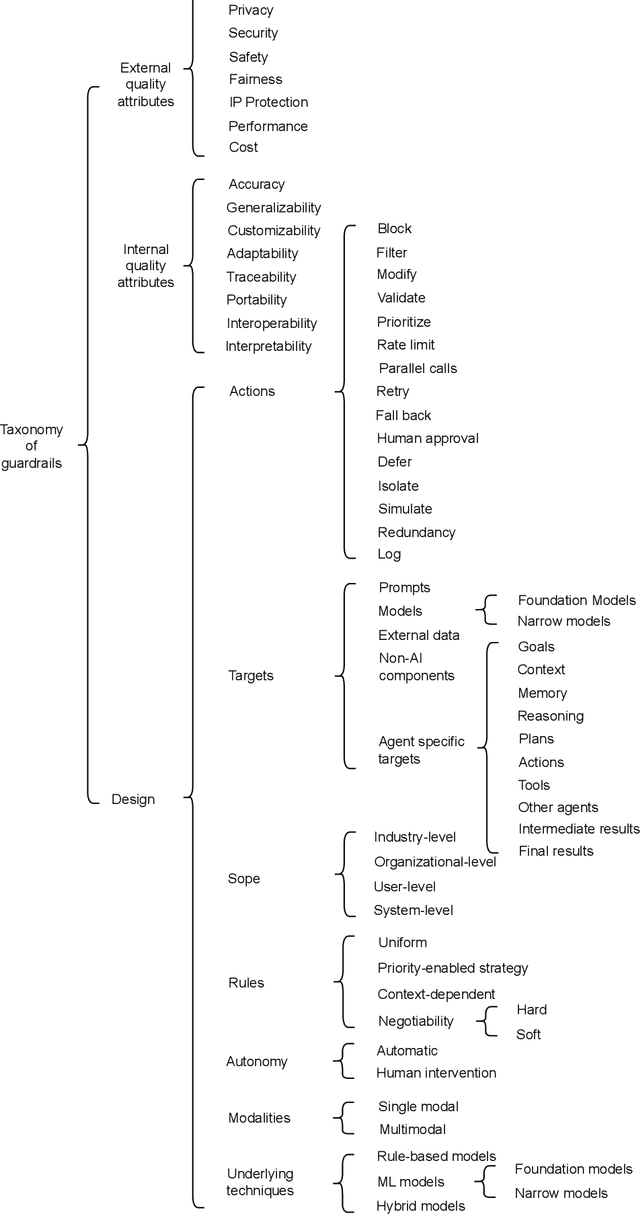
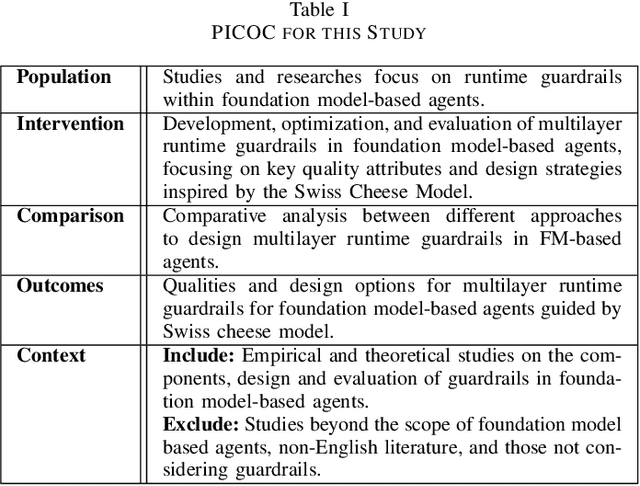
The rapid advancement and widespread deployment of foundation model (FM) based systems have revolutionized numerous applications across various domains. However, the fast-growing capabilities and autonomy have also raised significant concerns about responsible AI and AI safety. Recently, there have been increasing attention toward implementing guardrails to ensure the runtime behavior of FM-based systems is safe and responsible. Given the early stage of FMs and their applications (such as agents), the design of guardrails have not yet been systematically studied. It remains underexplored which software qualities should be considered when designing guardrails and how these qualities can be ensured from a software architecture perspective. Therefore, in this paper, we present a taxonomy for guardrails to classify and compare the characteristics and design options of guardrails. Our taxonomy is organized into three main categories: the motivation behind adopting runtime guardrails, the quality attributes to consider, and the design options available. This taxonomy provides structured and concrete guidance for making architectural design decisions when designing guardrails and highlights trade-offs arising from the design decisions.
Agent Design Pattern Catalogue: A Collection of Architectural Patterns for Foundation Model based Agents
May 16, 2024



Foundation model-enabled generative artificial intelligence facilitates the development and implementation of agents, which can leverage distinguished reasoning and language processing capabilities to takes a proactive, autonomous role to pursue users' goals. Nevertheless, there is a lack of systematic knowledge to guide practitioners in designing the agents considering challenges of goal-seeking (including generating instrumental goals and plans), such as hallucinations inherent in foundation models, explainability of reasoning process, complex accountability, etc. To address this issue, we have performed a systematic literature review to understand the state-of-the-art foundation model-based agents and the broader ecosystem. In this paper, we present a pattern catalogue consisting of 16 architectural patterns with analyses of the context, forces, and trade-offs as the outcomes from the previous literature review. The proposed catalogue can provide holistic guidance for the effective use of patterns, and support the architecture design of foundation model-based agents by facilitating goal-seeking and plan generation.