 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation-Driven Approach to Designing LLM Agents: Process and Architecture
Paper and Code
Nov 21, 2024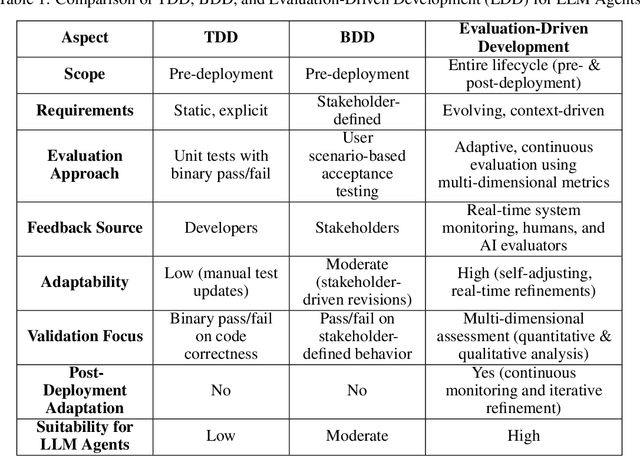

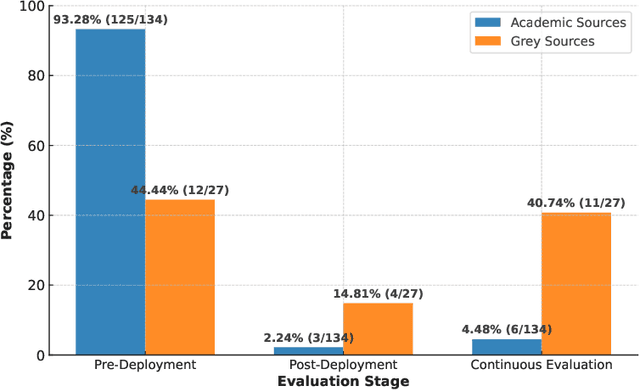

The advent of Large Language Models (LLMs) has enabled the development of LLM agents capable of autonomously achieving under-specified goals and continuously evolving through post-deployment improvement, sometimes without requiring code or model updates. Conventional approaches, such as pre-defined test cases and code/model redevelopment pipelines, are inadequate for addressing the unique challenges of LLM agent development, particularly in terms of quality and risk control. This paper introduces an evaluation-driven design approach, inspired by test-driven development, to address these challenges. Through a multivocal literature review (MLR), we synthesize existing LLM evaluation methods and propose a novel process model and reference architecture specifically designed for LLM agents. The proposed approach integrates online and offline evaluations to support adaptive runtime adjustments and systematic offline redevelopment, improving runtime pipelines, artifacts, system architecture, and LLMs by continuously incorporating evaluation results, including fine-grained feedback from human and AI evaluators.