 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-Judge in Education: A Curriculum-Grounded Marking Pipeline
Jun 16, 2026Generative AI and large language models (LLMs) are increasingly applied to question generation and automated assessment. However, deploying LLMs in preparation for high-stakes exams requires more than prompt engineering; it demands software pipelines that systematically ground model outputs in authorised curriculum artefacts and marking guidelines issued by education authorities. This paper presents a curriculum-grounded, configurable LLM-as-Judge pipeline for question-level marking, co-developed with an industrial partner, to support exam preparation for university admission. The pipeline identifies the relevant topics, subtopics, and cognitive demand of a question, and assembles verifiable and authorised context to support LLM judgement. Curriculum intent is operationalised through concrete syllabus artefacts, including prescribed verbs and outcomes, performance band descriptors, glossary definitions, and marking-guideline principles. A staged LLM workflow is employed to first generate question-specific rubrics, capturing structured expectations of performance, and then derive and evaluate marking criteria used to allocate marks to student responses. This design improves consistency, transparency, and alignment with official marking practices. Preliminary evaluation shows that the proposed LLM-as-Judge pipeline delivers marking outcomes comparable to human tutors, while yielding justifications that are more traceable to authorised curriculum artefacts and marking standards. The pipeline has also been integrated into an online study platform, where early deployment data provide initial insights into operational usage and manual overrides.
A Rusty Link in the AI Supply Chain: Detecting Evil Configurations in Model Repositories
May 02, 2025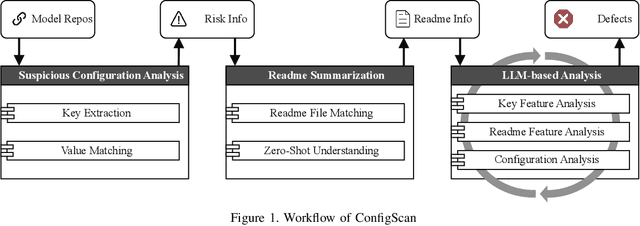

Recent advancements in large language models (LLMs) have spurred the development of diverse AI applications from code generation and video editing to text generation; however, AI supply chains such as Hugging Face, which host pretrained models and their associated configuration files contributed by the public, face significant security challenges; in particular, configuration files originally intended to set up models by specifying parameters and initial settings can be exploited to execute unauthorized code, yet research has largely overlooked their security compared to that of the models themselves; in this work, we present the first comprehensive study of malicious configurations on Hugging Face, identifying three attack scenarios (file, website, and repository operations) that expose inherent risks; to address these threats, we introduce CONFIGSCAN, an LLM-based tool that analyzes configuration files in the context of their associated runtime code and critical libraries, effectively detecting suspicious elements with low false positive rates and high accuracy; our extensive evaluation uncovers thousands of suspicious repositories and configuration files, underscoring the urgent need for enhanced security validation in AI model hosting platforms.
Good News for Script Kiddies? Evaluating Large Language Models for Automated Exploit Generation
May 02, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities in code-related tasks, raising concerns about their potential for automated exploit generation (AEG). This paper presents the first systematic study on LLMs' effectiveness in AEG, evaluating both their cooperativeness and technical proficiency. To mitigate dataset bias, we introduce a benchmark with refactored versions of five software security labs. Additionally, we design an LLM-based attacker to systematically prompt LLMs for exploit generation. Our experiments reveal that GPT-4 and GPT-4o exhibit high cooperativeness, comparable to uncensored models, while Llama3 is the most resistant. However, no model successfully generates exploits for refactored labs, though GPT-4o's minimal errors highlight the potential for LLM-driven AEG advancements.
FactFlow: Automatic Fact Sheet Generation and Customization from Tabular Dataset via AI Chain Design & Implementation
Feb 25, 2025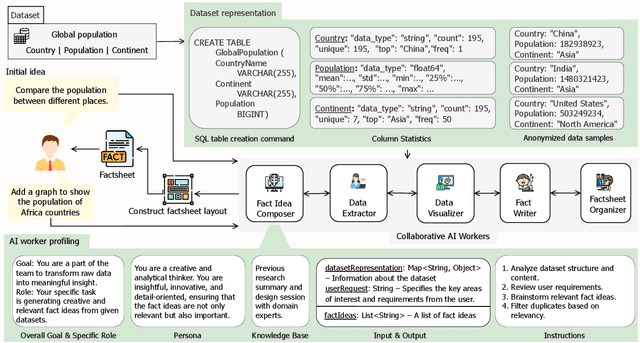
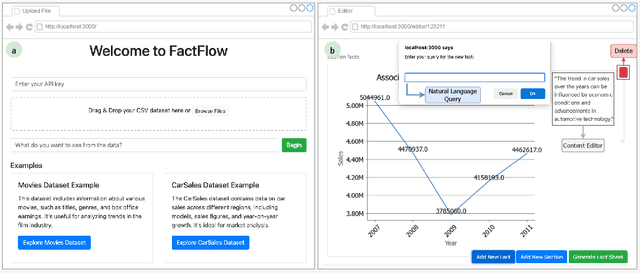
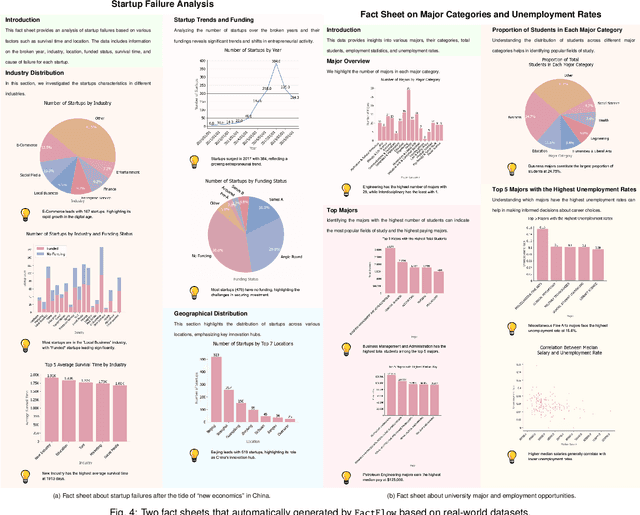
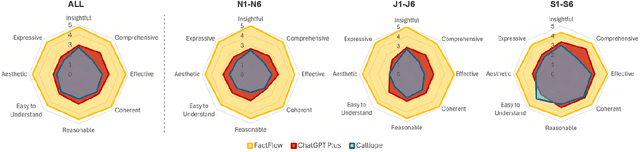
With the proliferation of data across various domains, there is a critical demand for tools that enable non-experts to derive meaningful insights without deep data analysis skills. To address this need, existing automatic fact sheet generation tools offer heuristic-based solutions to extract facts and generate stories. However, they inadequately grasp the semantics of data and struggle to generate narratives that fully capture the semantics of the dataset or align the fact sheet with specific user needs. Addressing these shortcomings, this paper introduces \tool, a novel tool designed for the automatic generation and customisation of fact sheets. \tool applies the concept of collaborative AI workers to transform raw tabular dataset into comprehensive, visually compelling fact sheets. We define effective taxonomy to profile AI worker for specialised tasks. Furthermore, \tool empowers users to refine these fact sheets through intuitive natural language commands, ensuring the final outputs align closely with individual preferences and requirements. Our user evaluation with 18 participants confirms that \tool not only surpasses state-of-the-art baselines in automated fact sheet production but also provides a positive user experience during customization tasks.
Hierarchical Vectorization for Portrait Images
May 24, 2022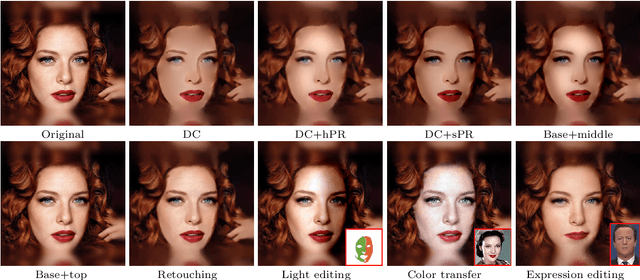
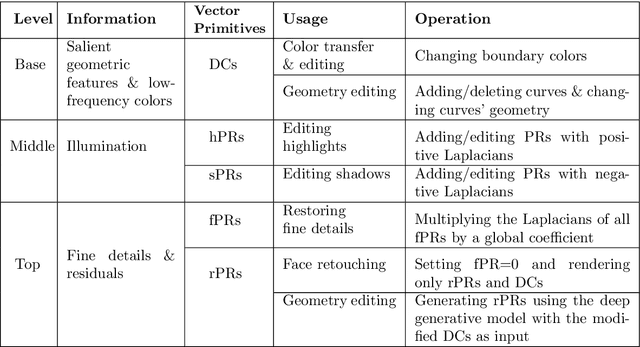
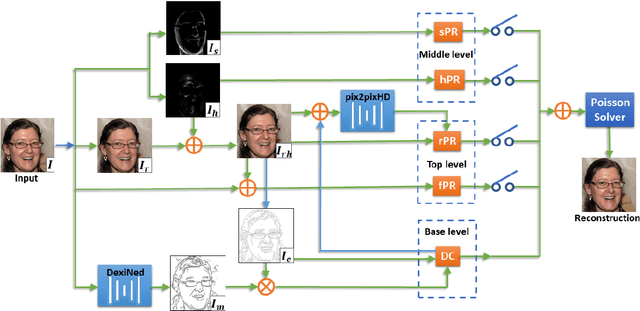
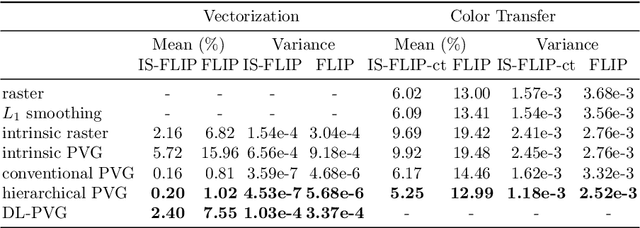
Aiming at developing intuitive and easy-to-use portrait editing tools, we propose a novel vectorization method that can automatically convert raster images into a 3-tier hierarchical representation. The base layer consists of a set of sparse diffusion curves (DC) which characterize salient geometric features and low-frequency colors and provide means for semantic color transfer and facial expression editing. The middle level encodes specular highlights and shadows to large and editable Poisson regions (PR) and allows the user to directly adjust illumination via tuning the strength and/or changing shape of PR. The top level contains two types of pixel-sized PRs for high-frequency residuals and fine details such as pimples and pigmentation. We also train a deep generative model that can produce high-frequency residuals automatically. Thanks to the meaningful organization of vector primitives, editing portraits becomes easy and intuitive. In particular, our method supports color transfer, facial expression editing, highlight and shadow editing and automatic retouching. Thanks to the linearity of the Laplace operator, we introduce alpha blending, linear dodge and linear burn to vector editing and show that they are effective in editing highlights and shadows. To quantitatively evaluate the results, we extend the commonly used FLIP metric (which measures differences between two images) by considering illumination. The new metric, called illumination-sensitive FLIP or IS-FLIP, can effectively capture the salient changes in color transfer results, and is more consistent with human perception than FLIP and other quality measures on portrait images. We evaluate our method on the FFHQR dataset and show that our method is effective for common portrait editing tasks, such as retouching, light editing, color transfer and expression editing. We will make the code and trained models publicly available.
Flexible Portrait Image Editing with Fine-Grained Control
Apr 04, 2022


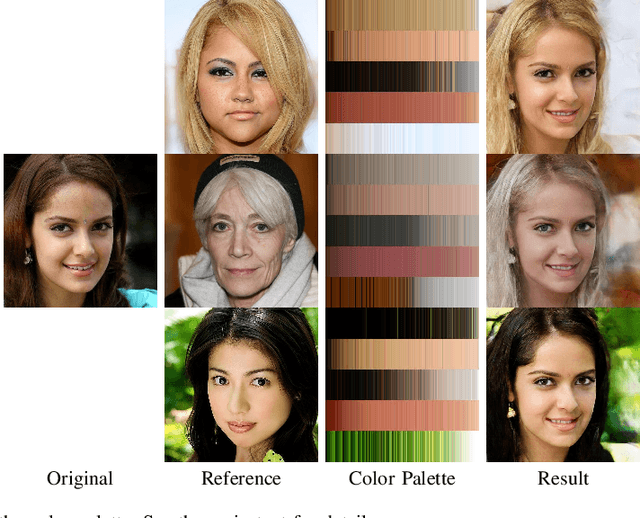
We develop a new method for portrait image editing, which supports fine-grained editing of geometries, colors, lights and shadows using a single neural network model. We adopt a novel asymmetric conditional GAN architecture: the generators take the transformed conditional inputs, such as edge maps, color palette, sliders and masks, that can be directly edited by the user; the discriminators take the conditional inputs in the way that can guide controllable image generation more effectively. Taking color editing as an example, we feed color palettes (which can be edited easily) into the generator, and color maps (which contain positional information of colors) into the discriminator. We also design a region-weighted discriminator so that higher weights are assigned to more important regions, like eyes and skin. Using a color palette, the user can directly specify the desired colors of hair, skin, eyes, lip and background. Color sliders allow the user to blend colors in an intuitive manner. The user can also edit lights and shadows by modifying the corresponding masks. We demonstrate the effectiveness of our method by evaluating it on the CelebAMask-HQ dataset with a wide range of tasks, including geometry/color/shadow/light editing, hand-drawn sketch to image translation, and color transfer. We also present ablation studies to justify our design.